Clear Sky Science · fr
Fiabilité des modèles de langue comme assistants médicaux pour le grand public : une étude randomisée préenregistrée
Pourquoi votre téléphone n’est peut-être pas le meilleur premier médecin
De plus en plus de personnes se tournent vers des chatbots d’IA lorsqu’elles se sentent malades, espérant obtenir rapidement une réponse sur l’origine de leurs symptômes, s’il faut s’inquiéter et s’il faut se rendre à l’hôpital. Cette étude pose une question simple mais urgente : si des personnes ordinaires utilisent des modèles de langage puissants comme assistants médicaux à domicile, prennent-elles réellement de meilleures décisions concernant leur santé — ou la technologie peut-elle donner une fausse impression de sécurité ?
Tester des machines intelligentes sur des cas réalistes
Pour le vérifier, des chercheurs au Royaume‑Uni ont conçu dix récits médicaux réalistes, comme un mal de tête soudain et intense ou des difficultés respiratoires, basés sur des affections courantes que beaucoup d’entre nous peuvent rencontrer. Une équipe de médecins expérimentés a convenu de la « prochaine étape » la plus appropriée pour chaque histoire — allant du fait de rester à la maison et de se soigner soi‑même à appeler une ambulance — et a listé les affections clés qu’une personne prudente devrait envisager. Ensuite, 1 298 adultes de tout le Royaume‑Uni ont été assignés au hasard à l’une des quatre options : utiliser l’un des trois chatbots d’IA principaux, ou utiliser ce sur quoi ils se fient habituellement à domicile, comme la recherche sur le web ou l’expérience personnelle.
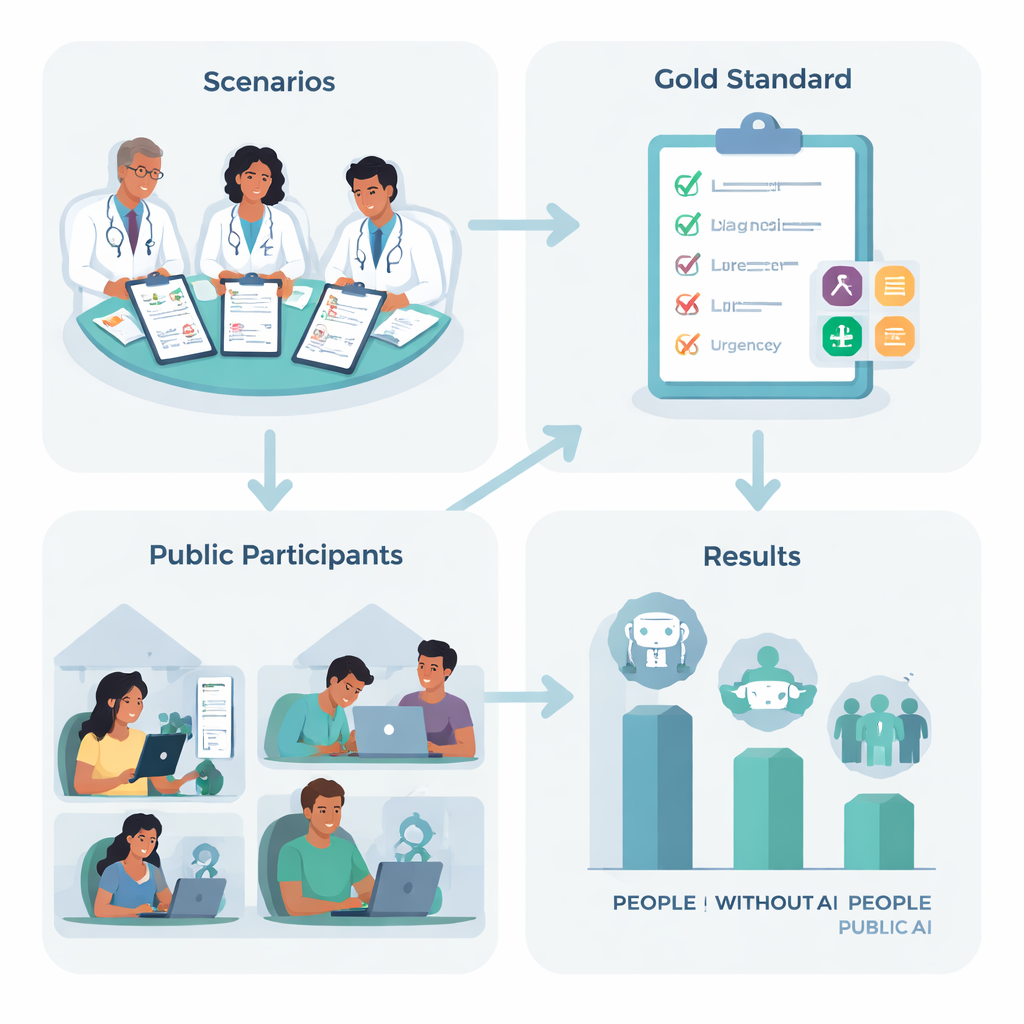
Performance des personnes et des machines — séparément et ensemble
Lorsque les modèles de langage ont été testés seuls, en leur fournissant les descriptions complètes des cas et en leur demandant directement un diagnostic et une action recommandée, ils se sont montrés remarquablement performants. Sur les trois systèmes, ils ont suggéré correctement au moins une condition médicale pertinente dans environ 95 % des cas et ont choisi le bon niveau d’urgence plus de la moitié du temps — bien mieux que le simple hasard. Sur le papier, ces systèmes semblaient être de bons candidats pour guider des patients inquiets.
Quand les conseils de l’IA rencontrent des personnes réelles
Mais dès que des utilisateurs quotidiens sont intervenus, la donne a changé. Les participants utilisant l’IA n’étaient pas plus précis que le groupe témoin pour choisir la marche à suivre, et ils étaient en réalité moins bons pour nommer les affections sous‑jacentes pertinentes. Les personnes du groupe sans IA étaient environ 1,8 fois plus susceptibles d’identifier une condition correcte que celles utilisant des chatbots. La plupart des participants de tous les groupes ont sous‑estimé la gravité de la situation. Autrement dit, l’accès à un modèle de langage avancé n’a pas aidé les gens à mieux comprendre leurs symptômes, et n’a pas clairement orienté leurs choix vers des options plus sûres.
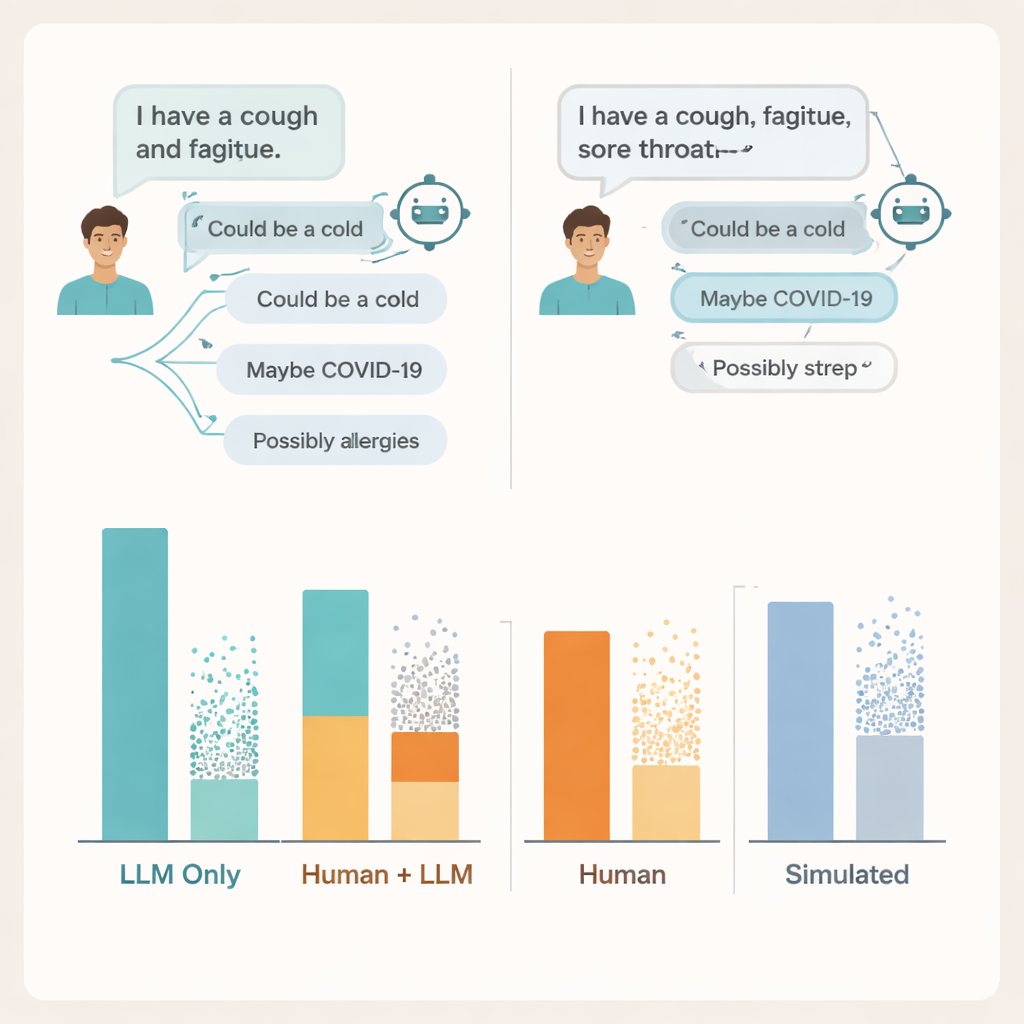
Où la conversation se grippe
Pour comprendre pourquoi, les chercheurs ont examiné les transcriptions réelles des conversations. Ils ont trouvé des problèmes des deux côtés de l’échange. Beaucoup d’utilisateurs ne fournissaient pas suffisamment de détails sur leurs symptômes pour que l’IA puisse donner un conseil fiable — tout comme des patients omettent parfois des informations clés lorsqu’ils parlent à un médecin. Les modèles eux‑mêmes mentionnaient souvent au moins une condition pertinente, mais ajoutaient aussi plusieurs possibilités incorrectes ou distrayantes, et les utilisateurs peinaient à distinguer quelles suggestions étaient importantes. Dans certains cas, des descriptions de symptômes presque identiques ont conduit à des conseils très différents du même modèle, rendant difficile pour les gens de savoir quand faire confiance à ce qu’ils voyaient à l’écran.
Pourquoi les tests standard passent à côté des risques réels
L’équipe a également comparé ces résultats à deux méthodes populaires d’évaluation des IA médicales : des questions d’examen à choix multiple et des chats entièrement simulés de « patient » menés entre deux modèles. Dans les deux cas, les systèmes semblaient à nouveau performants, atteignant ou dépassant les notes de passage habituelles aux questions de type examen et obtenant de meilleurs résultats avec des patients simulés que réels. Pourtant, de bons scores aux examens et des conversations simulées soignées ne correspondaient pas à la manière dont les personnes réelles se débrouillaient en utilisant les mêmes outils. Les bancs d’essai qui évaluent les connaissances isolément, soutiennent les auteurs, manquent la nature désordonnée et fragile des interactions réelles entre humains et IA.
Ce que cela signifie pour les patients et les systèmes de santé
Pour l’instant, conclut l’étude, les modèles de langage généralistes actuels ne sont pas prêts à agir comme conseillers de première ligne non supervisés pour le grand public. Ils contiennent manifestement une grande quantité de connaissances médicales, mais ces connaissances ne se traduisent pas automatiquement par des choix plus sûrs lorsque des personnes anxieuses saisissent des questions partielles et confuses à domicile. Rendre l’IA réellement utile dans des contextes à enjeux élevés comme la santé exigera plus que de meilleurs scores d’examen — cela demandera une conception soignée, des tests avec des utilisateurs réels et divers, et des contrôles plus stricts sur la manière dont l’information est recueillie, expliquée et accueillie dans l’échange conversationnel.
Citation: Bean, A.M., Payne, R.E., Parsons, G. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat Med 32, 609–615 (2026). https://doi.org/10.1038/s41591-025-04074-y
Mots-clés: chatbots médicaux, auto-diagnostic, IA en santé, décision du patient, grands modèles de langage