Clear Sky Science · fr
Synthèse de la littérature scientifique avec des modèles de langage augmentés par recherche
Pourquoi il est si difficile de suivre la science
Chaque année, des millions de nouveaux articles scientifiques paraissent en ligne. Aucun chercheur humain ne peut les lire tous, et pourtant des traitements médicaux importants, des connaissances sur le climat et des avancées technologiques peuvent se cacher dans ce flot d’informations. Cet article examine si des systèmes d’IA avancés peuvent aider les scientifiques à parcourir cet océan d’études et à en tirer des synthèses claires et fiables — sans inventer des éléments.
Un nouvel assistant de recherche
Les auteurs présentent OpenScholar, un système d’intelligence artificielle conçu spécifiquement pour lire et synthétiser la littérature scientifique. Contrairement aux chatbots généralistes, OpenScholar est étroitement connecté à une immense base de données ouverte d’environ 45 millions d’articles de recherche, appelée OpenScholar DataStore. Lorsqu’un scientifique pose une question — par exemple comment refroidir des nanoparticules lévitantes ou quelles méthodes fonctionnent le mieux pour l’imagerie cérébrale — le système parcourt d’abord cette base pour trouver des passages pertinents, puis rédige une réponse avec des citations intégrées, à la manière d’un article de synthèse écrit par un humain. Il répète ce processus plusieurs fois, critiquant et affinant ses propres brouillons pour améliorer la clarté, l’exhaustivité et la qualité des citations.
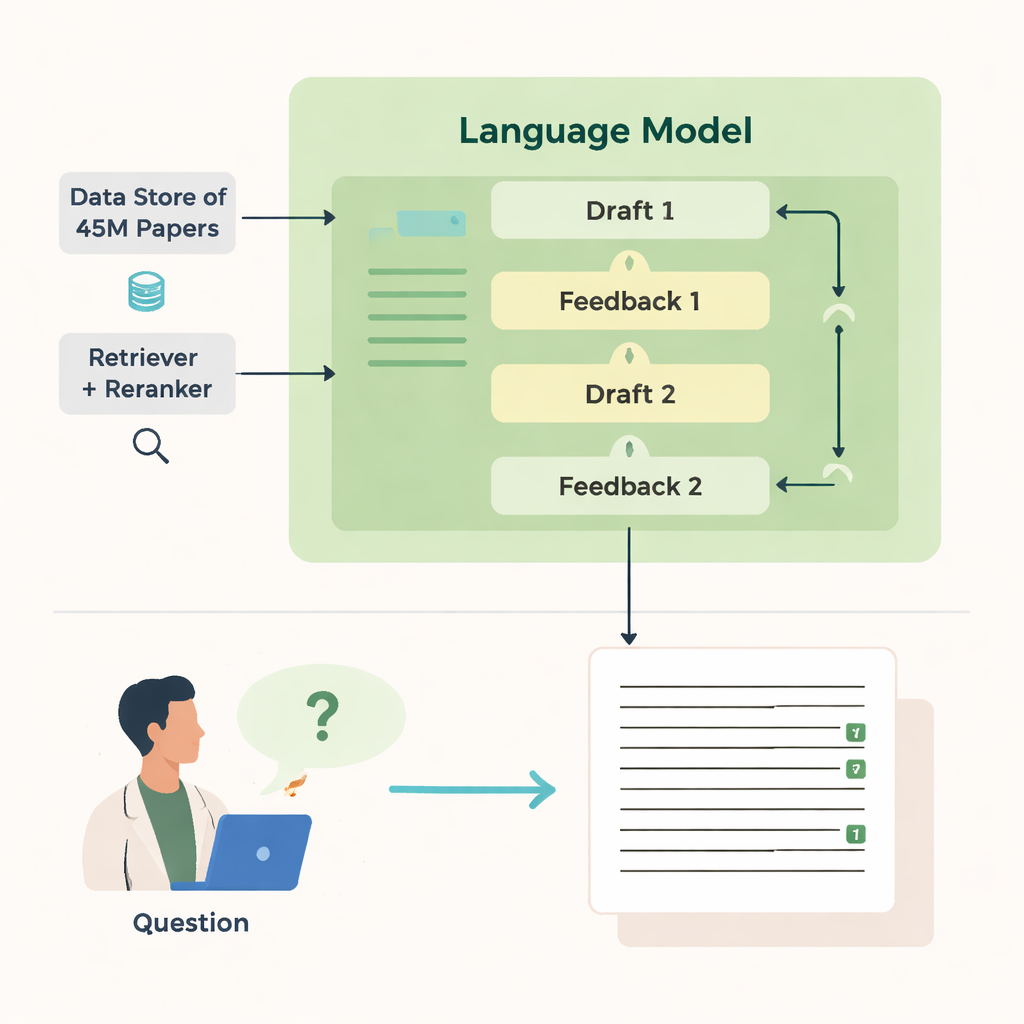
Comment il recherche et rédige
La puissance d’OpenScholar provient de plusieurs composants coordonnés. Un module « récupérateur » parcourt des embeddings textuels pré-calculés issus de millions d’articles pour trouver des extraits prometteurs, tandis qu’un « réordonneur » remet ces extraits dans un ordre privilégiant les plus pertinents. Le modèle de langage utilise ensuite ces éléments de preuve pour produire une réponse longue avec des références numérotées. Après le premier brouillon, le modèle génère un retour sur lui-même — signalant des perspectives manquantes, une structure faible ou des preuves insuffisantes — et, si nécessaire, déclenche des recherches plus ciblées. Il réécrit alors la réponse en intégrant de nouveaux articles et en ajustant les citations. Une vérification finale s’assure que les affirmations nécessitant des preuves sont étayées par au moins une source récupérée.
Mettre à l’épreuve les affirmations et les citations
Pour vérifier si OpenScholar apporte réellement une aide, les auteurs ont créé ScholarQABench, un large banc d’essai conçu pour imiter des questions de revue de la littérature réelles. Il comprend près de 3 000 questions rédigées par des experts et des centaines de réponses longues couvrant l’informatique, la physique, les neurosciences et la biomédecine. Il est important de noter que ces questions exigent généralement la lecture de plusieurs articles, et pas seulement d’un résumé. L’équipe a évalué les systèmes selon plusieurs axes : exactitude factuelle, couverture des points clés, clarté de la rédaction et précision des citations par rapport aux articles sous-jacents. Ils ont combiné des vérifications automatiques avec des évaluations détaillées par des experts au niveau doctorat qui ont comparé les réponses générées par l’IA aux réponses humaines.
Battre des chatbots puissants et égaler des experts
Sur ce banc d’essai, OpenScholar a surpassé à la fois les modèles de langage standard et des outils antérieurs qui se contentaient d’ajouter une recherche à un chatbot généraliste. Une version compacte de huit milliards de paramètres, entraînée entièrement sur des données ouvertes, a obtenu de meilleurs résultats sur une tâche exigeante de synthèse multi-articles que GPT-4o et un système concurrent appelé PaperQA2, malgré le fait que ceux-ci s’appuyaient sur des modèles propriétaires plus volumineux. Une constatation frappante fut la fréquence des hallucinations de références par les chatbots ordinaires : dans 78 à 90 % des cas, leurs listes de citations incluaient des articles qui n’existaient pas ou qui ne soutenaient pas les affirmations. En revanche, la précision des citations d’OpenScholar rivalisait avec celle des experts humains. Lorsque des experts ont comparé directement les réponses, ils ont préféré OpenScholar-8B aux réponses rédigées par des experts environ la moitié du temps, et une pipeline OpenScholar construite sur GPT-4o environ 70 % du temps, principalement parce que l’IA couvrait davantage d’études pertinentes et les organisait clairement.
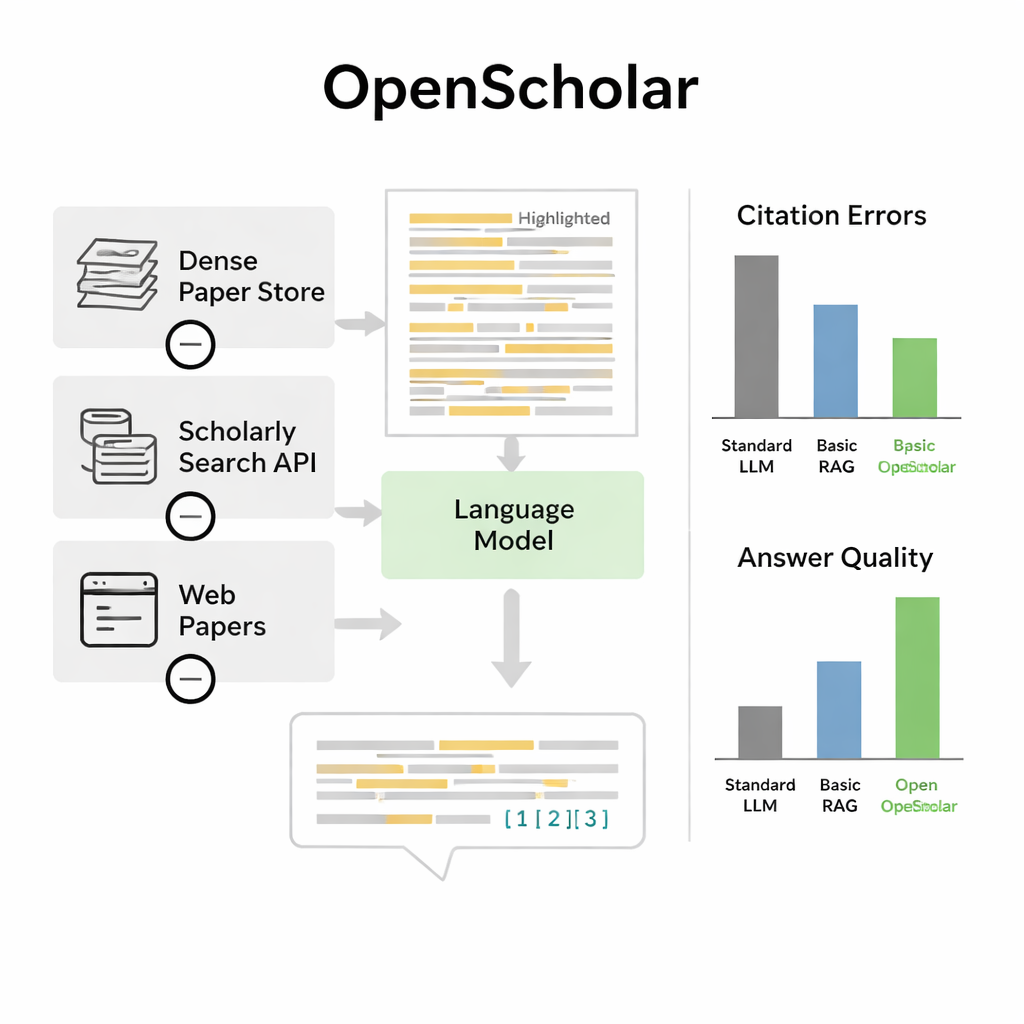
Limites et améliorations futures
Malgré ces progrès, les auteurs soulignent qu’OpenScholar ne remplace pas les scientifiques. Le système peut encore manquer les articles les plus représentatifs, surpondérer des travaux moins importants ou introduire des erreurs factuelles, en particulier dans les modèles plus compacts. Le banc d’essai lui-même a aussi des limites : il se concentre principalement sur l’informatique, la biomédecine et la physique, et les questions soigneusement annotées restent relativement peu nombreuses car le temps d’expertise est coûteux. Les évaluations peinent également à capturer pleinement des qualités plus subtiles, comme le fait de savoir si les citations mettent en avant des travaux véritablement séminales ou si une réponse guiderait réellement une nouvelle expérience.
Ce que cela signifie pour la science de tous les jours
Pour les non-spécialistes, l’essentiel est que des outils d’IA bien conçus peuvent déjà aider les scientifiques à mieux naviguer dans la littérature, à condition qu’ils soient reliés à des données réelles et soumis à des normes strictes d’évidence et de transparence. OpenScholar montre que lorsqu’un système d’IA est construit dès le départ pour rechercher, vérifier et citer de vrais articles — et quand sa performance est testée face à des experts humains — il peut produire des synthèses de la littérature qui sont non seulement lisibles mais aussi vérifiables. En pratique, de tels outils pourraient libérer les chercheurs pour qu’ils se concentrent davantage sur la conception d’expériences et l’interprétation des résultats, tout en laissant aux humains la responsabilité finale de juger ce qui est vrai et important.
Citation: Asai, A., He, J., Shao, R. et al. Synthesizing scientific literature with retrieval-augmented language models. Nature 650, 857–863 (2026). https://doi.org/10.1038/s41586-025-10072-4
Mots-clés: revue de la littérature scientifique, modèles de langage augmentés par recherche, OpenScholar, exactitude des citations, outils d’IA pour la recherche