Clear Sky Science · fr
Anticipation et découverte des métabolites mammifères guidées par des modèles de langage chimique
La chimie cachée à l’intérieur de nos corps
Chaque goutte de sang ou d’urine contient des milliers de petites molécules qui reflètent ce que nous mangeons, notre mode de vie et si nous tombons malades. Pourtant, pour la plupart de ces molécules, les chercheurs ne connaissent ni le nom ni la fonction. Cet article présente DeepMet, un système d’intelligence artificielle qui lit le « langage » de ces molécules et prédit lesquelles manquent dans nos cartes actuelles de la chimie humaine et animale. En orientant les expériences vers les candidats les plus prometteurs, DeepMet aide à dévoiler cette matière chimique obscure et à mieux comprendre le fonctionnement de nos organismes.
Pourquoi tant de molécules restent inconnues
Les instruments modernes peuvent peser et partiellement caractériser des milliers de molécules dans un échantillon de tissu en une seule fois. Mais convertir ces empreintes en structures exactes est difficile. Les bases de données existantes répertorient de nombreux métabolites connus, pourtant la plupart des signaux observés dans des échantillons réels ne correspondent à rien dans ces catalogues. Cet écart suggère que les cartes actuelles du métabolisme sont incomplètes et que de nombreuses molécules naturelles chez les mammifères n’ont jamais été décrites. Les auteurs ont entrepris de créer un outil capable d’apprendre à partir de métabolites connus puis d’imaginer les plus plausibles manquants, de la même façon que les modèles de langage prédisent des mots probables dans une phrase.
Apprendre à une machine la grammaire du métabolisme
L’équipe a entraîné un réseau neuronal baptisé DeepMet sur environ 2 000 métabolites humains bien établis, en encodant chacun comme une courte chaîne décrivant sa structure. Après un entraînement initial sur des molécules de type médicament pour apprendre les règles chimiques générales, DeepMet a été affiné sur cet ensemble de métabolites. Lorsqu’on lui a demandé de générer de nouvelles structures, le modèle a produit des molécules qui occupaient les mêmes régions de l’espace chimique que les métabolites réels et a même reproduit de nombreux types de réactions enzymatiques connues, sans qu’on lui ait explicitement enseigné ces règles. Autrement dit, DeepMet semble avoir internalisé la grammaire non écrite qui relie des blocs de construction tels que sucres et acides aminés en petites molécules biologiquement réalistes.
Prédire quelles nouvelles molécules existent probablement
Les chercheurs ont ensuite échantillonné un milliard de candidats moléculaires à partir de DeepMet et compté la fréquence d’apparition de chaque structure unique. Les structures fréquemment répétées avaient tendance à ressembler davantage à des métabolites connus, à partager des noyaux chimiques communs avec eux et à correspondre à des transformations enzymatiques plausibles. Pour tester si ces candidats à haute fréquence correspondaient à de véritables molécules, l’équipe a comparé les prédictions de DeepMet aux métabolites ajoutés à la Human Metabolome Database après la date de clôture des données d’entraînement du modèle. DeepMet avait déjà généré la plupart de ces découvertes ultérieures et en avait classé beaucoup parmi ses candidats les plus probables. Parmi les milliers de structures absentes des bases mais très bien classées, les auteurs en ont acheté ou synthétisé 80 et ont contrôlé des échantillons humains réels par spectrométrie de masse. Ils ont confirmé la présence de plusieurs métabolites auparavant non reconnus, dont certains avaient été négligés alors même qu’ils apparaissaient dans la littérature existante.
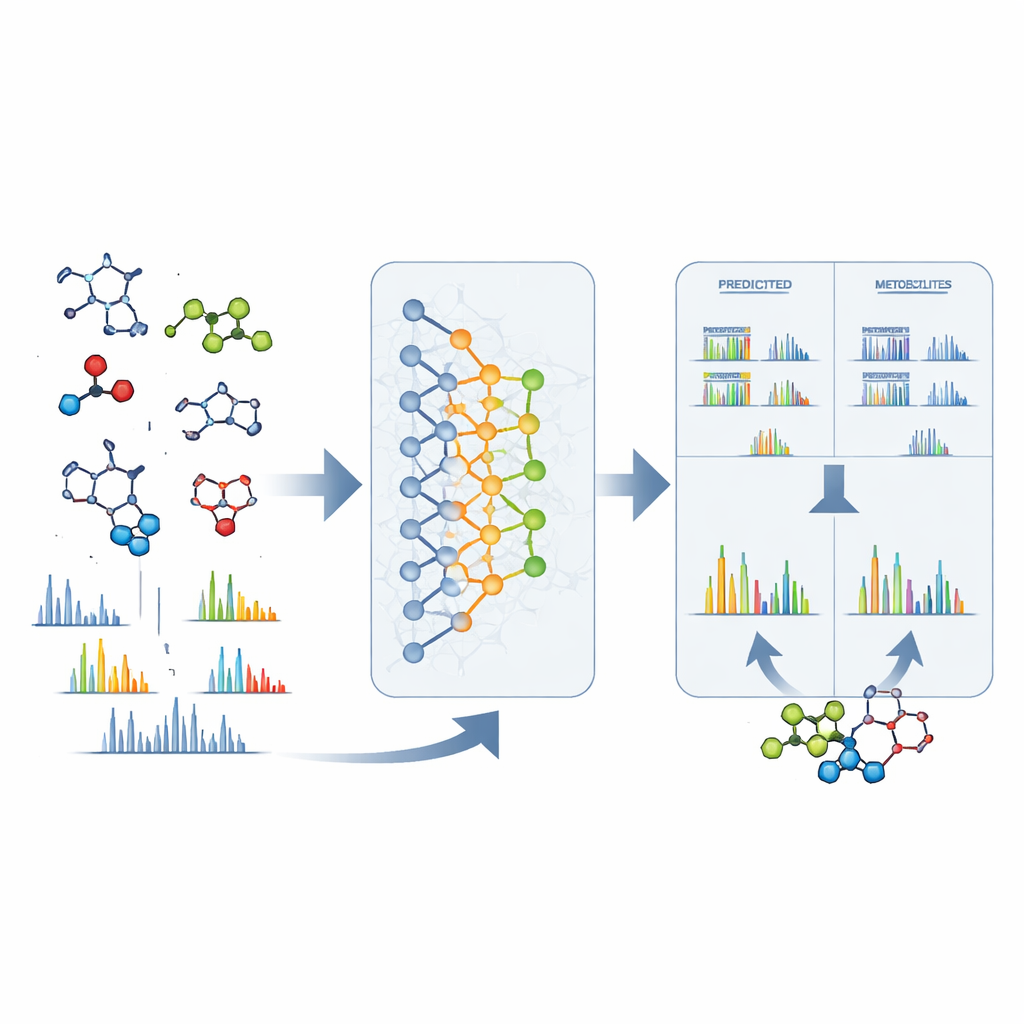
Des signaux bruts aux structures concrètes
DeepMet est également utile lorsqu’un pic inconnu a été observé en spectrométrie de masse. À partir de la masse exacte d’une molécule mystérieuse, le modèle peut dresser une liste de structures possibles ayant le même poids et les classer selon leur ressemblance à un métabolite. Dans près d’un tiers des cas testés, la bonne structure arrivait en tête ; dans beaucoup d’autres, elle figurait parmi une poignée de candidats bien classés et était généralement très similaire à le préféré du modèle. Pour affiner davantage la sélection, les auteurs ont combiné DeepMet avec un logiciel distinct prédisant la fragmentation attendue de chaque candidat en spectrométrie de masse. La mise en correspondance de ces motifs prédits avec des spectres expérimentaux réels a à peu près doublé la précision d’identification. La recherche dans de grands ensembles de données publiques avec cette approche combinée a permis d’attribuer des structures provisoires à de nombreux signaux auparavant anonymes et d’identifier des métabolites qui varient selon les maladies, les régimes alimentaires et l’état du microbiome.
Éclairer la matière noire chimique de la vie
En mêlant l’intuition chimique apprise à partir des données à une puissante mise en correspondance des motifs spectrométriques, DeepMet fournit une feuille de route pour découvrir de nouveaux métabolites de manière ciblée et pratique. Il ne peut pas encore révéler toutes les molécules inconnues — certaines structures sont trop éloignées de celles qu’il a vues, et certains isomères restent indistinguables sans méthodes spécialisées. Mais l’étude montre que des outils de type modèle de langage peuvent non seulement inventer des molécules réalistes, ils peuvent aussi anticiper de véritables composés que les biologistes confirmeront ensuite chez les animaux et les humains. Pour le grand public, la conclusion est que l’IA peut désormais aider les chimistes à dévoiler systématiquement la chimie cachée de nos corps, révélant potentiellement de nouveaux biomarqueurs, retraçant les liens régime–microbes–hôte et transformant peu à peu la matière noire métabolique d’aujourd’hui en une biologie bien cartographiée demain.
Citation: Qiang, H., Wang, F., Lu, W. et al. Language model-guided anticipation and discovery of mammalian metabolites. Nature 651, 211–220 (2026). https://doi.org/10.1038/s41586-025-09969-x
Mots-clés: métabolomique, modèles de langage chimique, DeepMet, spectrométrie de masse, matière noire métabolique