Clear Sky Science · fr
Révéler les pics clés pour l’authentification de l’huile d’olive par spectroscopie Raman et chimiométrie
Pourquoi l’histoire de la fraude à l’huile d’olive compte
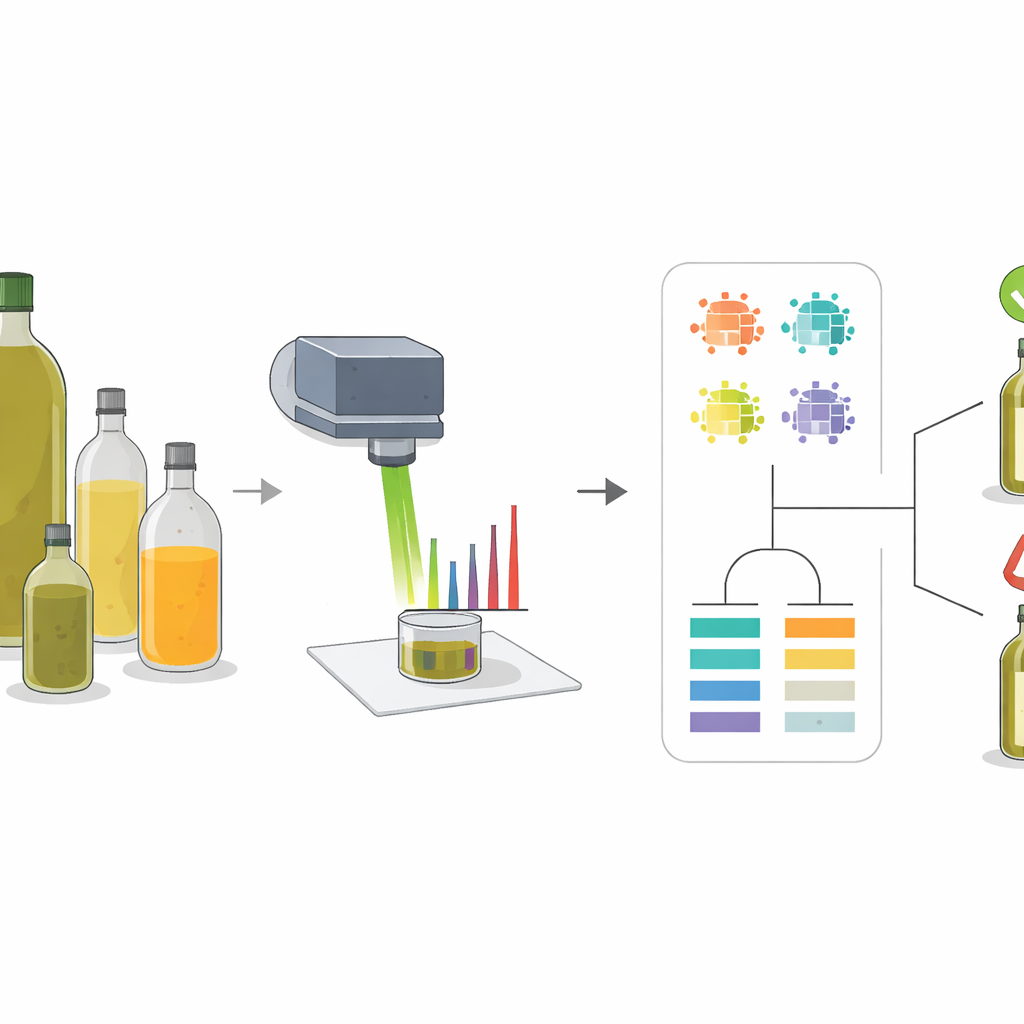
Lorsque vous payez plus cher une bouteille d’huile d’olive, vous vous attendez au produit authentique, et non à un mélange discrètement étiré avec des huiles végétales moins chères. Pourtant, comme l’huile d’olive a de la valeur et que le commerce mondial est complexe, la fraude et le mauvais étiquetage sont des problèmes fréquents. Cette étude présente une méthode rapide et non destructive pour repérer ces tromperies en éclairant les huiles avec un laser et en laissant des programmes informatiques intelligents lire les empreintes chimiques cachées. L’approche vise à aider à protéger les consommateurs, les producteurs honnêtes et les autorités en facilitant la vérification de la conformité entre le contenu de la bouteille et son étiquetage.
Éclairer pour lire les empreintes de l’huile
Les chercheurs ont utilisé une technique appelée spectroscopie Raman, qui consiste à diriger un faisceau lumineux focalisé sur un échantillon et à mesurer la façon dont la lumière est diffusée. Différentes molécules vibrent différemment, laissant une série de pics dans le spectre obtenu, un peu comme un code-barres. L’huile d’olive et les adulterants courants tels que les huiles de tournesol, de colza et de maïs ont des mélanges différents d’acides gras et de pigments naturels, de sorte que leurs spectres ne sont pas identiques. En étudiant ces motifs sur des huiles pures et des mélanges préparés avec soin, l’équipe a pu identifier un petit ensemble de « pics clés » dont la forme et l’intensité variaient de manière fiable selon la proportion d’huile d’olive présente dans un mélange.
Repérer les signaux les plus informatifs
Plutôt que de s’appuyer sur une seule mesure, l’équipe a extrait plusieurs descripteurs pour chaque pic important : sa hauteur (intensité), l’aire qu’il couvre, sa largeur à mi-hauteur et la façon dont son aire se compare à celle d’autres pics. Ils ont ensuite utilisé des cartes de regroupement et de corrélation pour voir comment ces descripteurs rassemblaient différentes huiles et comment ils évoluaient quand la teneur en huile d’olive augmentait. Les pics associés aux composés colorés comme le bêta-carotène et à certains types d’acides gras insaturés se sont révélés particulièrement informatifs. Par exemple, certains pics s’intensifiaient avec l’augmentation de l’huile d’olive, tandis que d’autres s’affaiblissaient parce qu’ils étaient liés à l’acide linoléique, plus abondant dans l’huile de tournesol. Cette vue multi-caractéristiques a capté des différences subtiles qui auraient été manquées en ne considérant qu’une seule valeur d’intensité.
Laisser les algorithmes trier l’honnête et l’adultéré
Pour transformer ces empreintes spectrales en décisions pratiques, les auteurs ont entraîné plusieurs modèles d’apprentissage automatique. D’abord, ils ont demandé aux modèles de classer dix types d’huiles, comprenant quatre huiles pures et six types de mélanges binaires et ternaires. Les méthodes basées sur les arbres — forêts aléatoires et arbres boostés par gradient — ont donné les meilleurs résultats, attribuant correctement presque tous les échantillons à la bonne catégorie lorsqu’on leur fournissait l’ensemble complet des caractéristiques de pics. Ensuite, le même type de modèles a servi à des prédictions numériques : estimer le pourcentage réel d’huile d’olive dans des mélanges à deux ou trois huiles. Là encore, les approches basées sur les arbres ont surpassé des méthodes plus traditionnelles, suivant avec précision la teneur en huile d’olive même lorsque les signaux des différentes huiles se chevauchaient fortement dans les spectres.
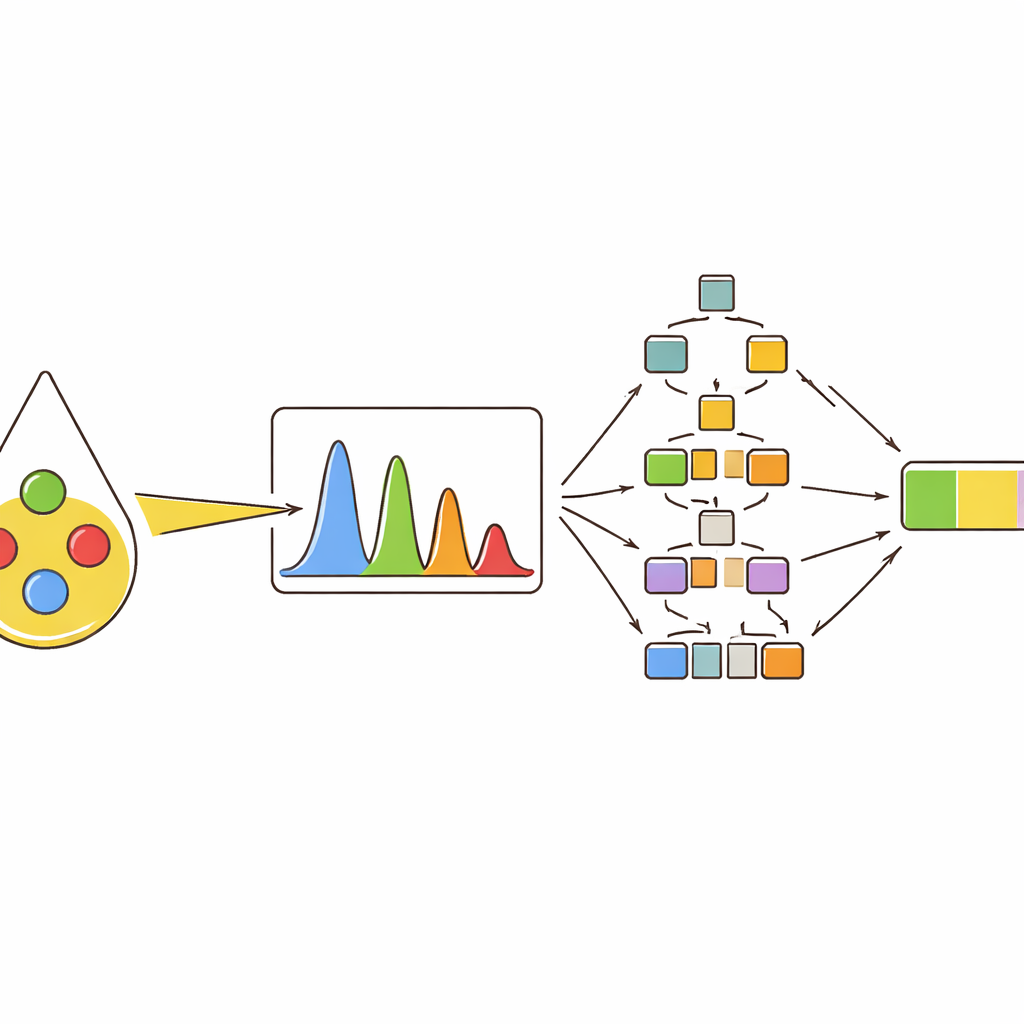
Ouvrir la boîte noire des modèles intelligents
Beauxcoup d’outils puissants d’apprentissage automatique sont difficiles à interpréter ; ils peuvent bien fonctionner mais donner peu d’informations sur les raisons d’une décision. Pour remédier à cela, l’étude a utilisé une méthode d’explication qui attribue à chaque caractéristique d’entrée une contribution à la prédiction finale. Cela a révélé que quelques pics spécifiques dominaient les jugements des modèles, faisant systématiquement monter ou baisser la prédiction de teneur en huile d’olive selon leurs valeurs. Les mêmes pics revenaient comme les plus importants à travers différents types de mélanges et lors de tests sur des huiles commerciales de supermarché, qui contenaient seulement une petite quantité d’huile d’olive. Pour ces échantillons du monde réel, les meilleurs modèles ont estimé la teneur en huile d’olive très près de la valeur réelle, soutenant à la fois la précision et la transparence de l’approche.
Ce que cela signifie pour votre bouteille à la maison
En termes pratiques, ce travail montre qu’un scan rapide à base de lumière, interprété par des modèles informatiques bien conçus et explicables, peut dire si une « huile d’olive » est pure, fortement diluée ou quelque part entre les deux. En se concentrant sur une poignée de caractéristiques spectrales robustes et en les combinant dans des algorithmes avancés mais interprétables, les chercheurs ont construit un outil susceptible d’être intégré aux contrôles de qualité de routine, potentiellement même dans des appareils portables. Bien que des tests plus larges portant sur davantage de régions, de variétés et de types de fraude soient encore nécessaires, ce cadre ouvre la voie vers un avenir où vérifier l’honnêteté d’aliments de grande valeur comme l’huile d’olive devient plus rapide, plus simple et plus fiable pour tous.
Citation: Chen, Y., Shao, R., Zeng, S. et al. Unveiling key peak features for olive oil authentication utilizing Raman spectroscopy and chemometrics. npj Sci Food 10, 88 (2026). https://doi.org/10.1038/s41538-026-00738-2
Mots-clés: authentification de l’huile d’olive, détection de fraude alimentaire, spectroscopie Raman, apprentissage automatique, qualité des huiles alimentaires