Clear Sky Science · fr
L’apprentissage automatique révèle trois couches de complexité alimentaire
Pourquoi des aliments plus intelligents comptent
Chaque bouchée dissimule un monde de complexité : des milliers de molécules invisibles, des interactions emmêlées entre ingrédients et les façons uniques dont le cerveau de chacun réagit aux goûts et aux odeurs. Cet article explique comment l’apprentissage automatique moderne aide les scientifiques à démêler cette complexité. En reliant analyses chimiques, capteurs d’usine et même images cérébrales, les chercheurs espèrent concevoir des aliments plus savoureux, plus sains et plus fiables — et mieux adapter les produits à ce que différents consommateurs apprécient réellement.
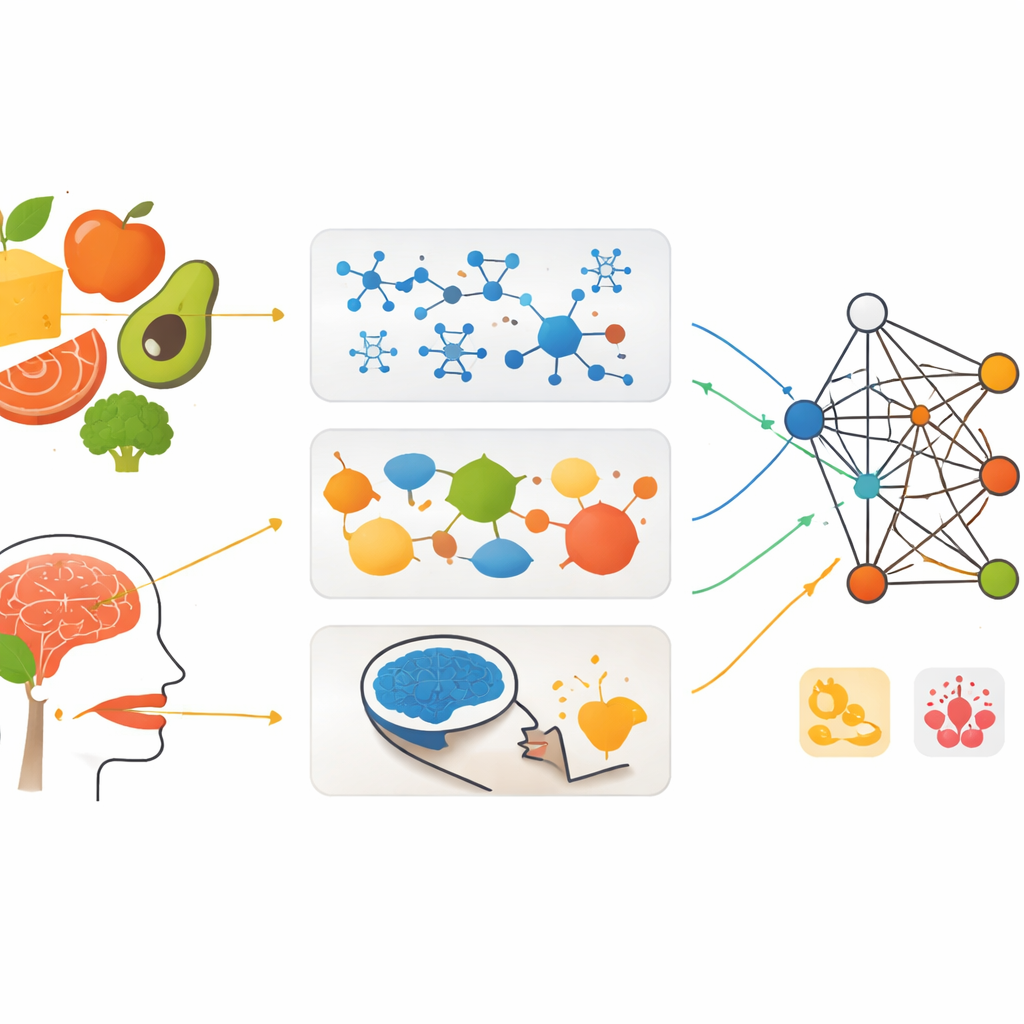
Explorer les blocs de construction cachés des aliments
Au niveau le plus fondamental, les aliments sont constitués de dizaines de milliers de composés distincts. Beaucoup sont de petites molécules d’arôme et de goût ; d’autres influencent la nutrition, la sécurité ou la durée de conservation. Seule une fraction de ces molécules a été étudiée en détail, si bien que les scientifiques ignorent souvent lesquelles créent une saveur ou un effet sur la santé donné. L’apprentissage automatique contribue à combler ces lacunes en détectant des motifs entre la structure d’une molécule et son comportement. Les algorithmes peuvent être entraînés sur des données connues pour prédire si de nouvelles molécules auront un goût sucré ou amer, sentiront le fruité ou le fumé, ou interagiront avec des récepteurs humains de façon bénéfique ou néfaste. Les modèles d’apprentissage profond qui traitent les molécules comme des réseaux d’atomes sont particulièrement puissants, révélant des liens structure–saveur difficiles à identifier manuellement.
Comment les ingrédients interagissent
Un aliment ne se comporte que rarement comme la simple somme de ses parties. Sucres, acides, graisses et arômes peuvent s’amplifier ou s’atténuer mutuellement, modifiant la texture, la libération d’arôme et l’équilibre des saveurs. Pour étudier ces interactions, les scientifiques collectent des « empreintes » détaillées des aliments à l’aide d’instruments tels que la chromatographie en phase gazeuse et liquide ou la spectrométrie de mobilité ionique, qui séparent et détectent des mélanges chimiques complexes. Les nez et langues électroniques vont plus loin en utilisant des réseaux de capteurs pour capturer le motif global d’odeur ou de goût d’un échantillon. Alimenter ces signaux riches dans des modèles d’apprentissage automatique permet aux chercheurs de classifier la qualité d’un produit, détecter la détérioration ou la fraude, et estimer les profils de saveur plus rapidement et de façon plus objective que les panels de dégustation traditionnels. Les méthodes de fusion de données combinent ensuite plusieurs sources — empreintes chimiques, signaux de capteurs, images couleur et composition de base — en modèles unifiés qui saisissent mieux la façon dont les ingrédients agissent ensemble.
Comment notre cerveau perçoit la saveur
Le parcours d’un aliment ne s’arrête pas à la langue ; il se poursuit dans le cerveau. Les personnes diffèrent grandement dans la façon dont elles perçoivent un même aliment en raison de la génétique, de la culture et des expériences passées. De nouveaux outils d’imagerie cérébrale, tels que l’électroencéphalographie (EEG), la spectroscopie fonctionnelle proche infrarouge et l’IRM fonctionnelle, peuvent suivre la réaction de différentes régions du cerveau lorsque des sujets goûtent ou sentent quelque chose. Les modèles d’apprentissage automatique entraînés sur ces signaux peuvent distinguer des goûts de base comme sucré, acide ou umami, reconnaître des odeurs spécifiques et même estimer à quel point quelqu’un trouve une odeur agréable. En combinant des méthodes rapides comme l’EEG avec des techniques d’imagerie qui localisent l’activité dans le cerveau, les chercheurs commencent à construire des cartes de perception des saveurs plus riches et individualisées.
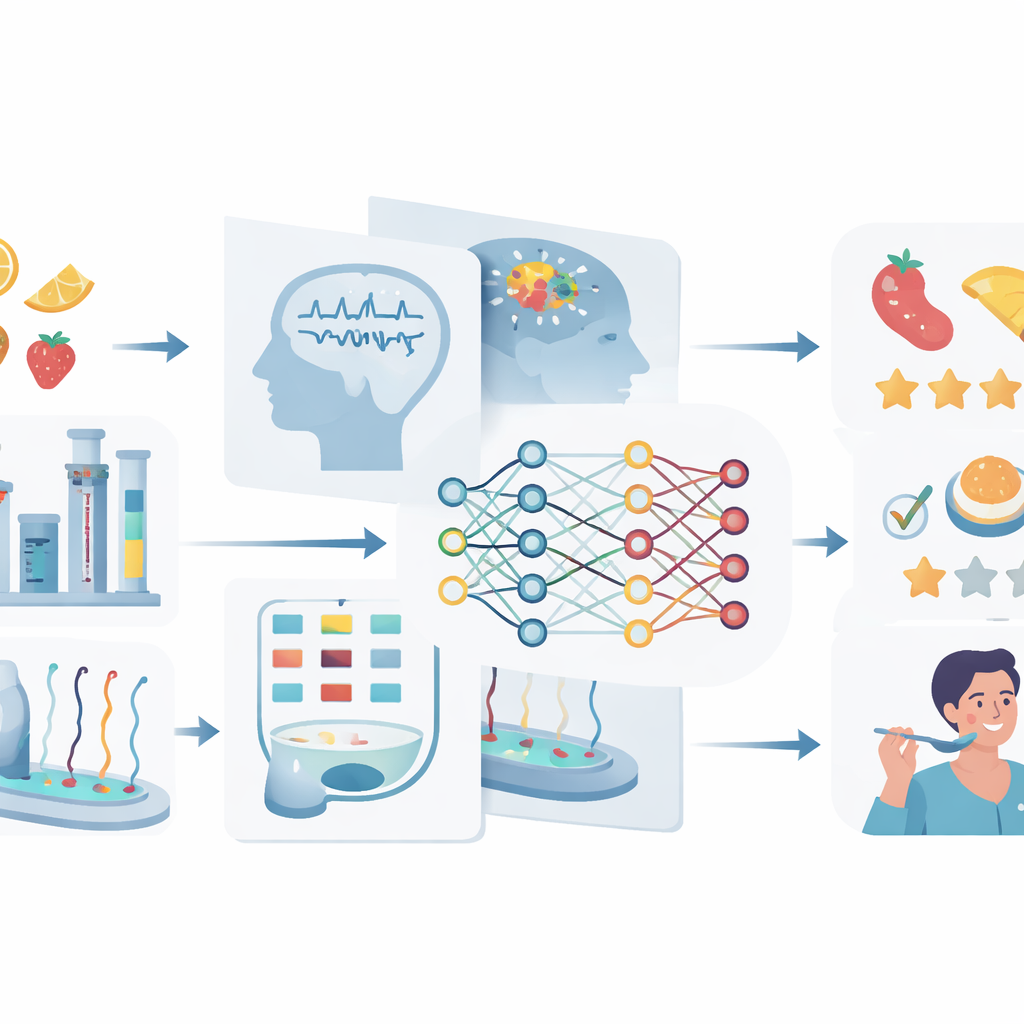
Rassembler de nombreux flux de données
Parce qu’aucune méthode unique ne peut saisir tous les aspects d’un aliment, l’article souligne l’importance de mêler plusieurs types de données. À une extrémité se trouvent des bases moléculaires qui répertorient nutriments, additifs et composés d’arôme. Au milieu se trouvent des mesures d’aliments entiers issues d’instruments de laboratoire et de capteurs intelligents. À l’autre extrémité se trouvent des données centrées sur l’humain comme des notes de dégustation, des avis consommateurs et des signaux cérébraux. Les stratégies de fusion de données joignent ces éléments à différents stades : les signaux bruts peuvent être fusionnés tôt, des caractéristiques extraites peuvent être combinées en cours de traitement, ou des modèles séparés peuvent être fusionnés au stade décisionnel. Lorsqu’elles sont soigneusement nettoyées, standardisées et partagées selon des règles communes, de telles données multimodales permettent aux systèmes d’apprentissage automatique de relier ce qu’il y a dans l’aliment, la façon dont il est transformé, et la sensation finale éprouvée en le consommant.
Ce que cela signifie pour les repas de demain
Les auteurs concluent que l’apprentissage automatique fournit une nouvelle boîte à outils pour comprendre l’aliment de la molécule à l’esprit. Concrètement, il peut aider les scientifiques à prédire quelles combinaisons d’ingrédients seront savoureuses, sûres et stables avant de passer des mois en cuisine ou en usine pilote. Il peut aussi relier des mesures objectives d’instruments et de capteurs aux expériences subjectives d’un public diversifié, guidant une conception alimentaire plus inclusive et personnalisée. Pour réaliser pleinement cette vision, le domaine a besoin de bases de données plus grandes et mieux organisées, de modèles plus faciles à interpréter et d’une collaboration plus étroite entre scientifiques de l’alimentation, chimistes, data scientists et neuroscientifiques. Si ces objectifs sont atteints, les aliments de demain pourraient être développés plus rapidement, adaptés plus précisément aux préférences et à la santé individuelle, et évalués de manière plus fiable que jamais.
Citation: Ke, Q., Zhang, J., Huang, X. et al. Machine learning unveils three layers of food complexity. npj Sci Food 10, 87 (2026). https://doi.org/10.1038/s41538-026-00730-w
Mots-clés: apprentissage automatique en science alimentaire, prédiction des saveurs alimentaires, nez et langue électroniques, réponses cérébrales au goût, données alimentaires multimodales