Clear Sky Science · fr
Un jeu de données d’IRMf 7T d’images synthétiques pour la modélisation hors distribution en vision
Pourquoi c’est important pour comprendre la vision et l’IA
Nos yeux captent chaque jour une grande variété d’images — forêts, visages, panneaux de signalisation ou bruit d’écran. Pourtant, la plupart des études en neurosciences et en intelligence artificielle s’appuient sur une part très étroite de ce monde visuel : des photographies de scènes naturelles. Cet article présente un nouveau type de jeu de données cérébrales qui sort volontairement de cette zone de confort, en utilisant des images synthétiques conçues pour mettre à l’épreuve à la fois nos théories de la vision humaine et les modèles d’IA qui s’en inspirent.
Construire un nouveau banc d’essai visuel
Les auteurs étendent le jeu de données influent Natural Scenes Dataset (NSD), qui a enregistré l’activité cérébrale à très haute résolution avec une IRM 7 tesla pendant que des participants regardaient des dizaines de milliers de photographies. Ce jeu de données original a déjà permis de construire certains des modèles les plus précis sur la façon dont le cortex visuel répond aux images. Mais comme toutes ces images sont des photos relativement ordinaires, il est difficile de savoir si un modèle performant sur le NSD capture vraiment des principes généraux de la vision ou s’il s’est simplement spécialisé à ce régime d’images. Pour répondre à cela, l’équipe a de nouveau scanné les mêmes huit volontaires, en leur montrant cette fois 284 images « synthétiques » qui sortent délibérément du monde photographique habituel.
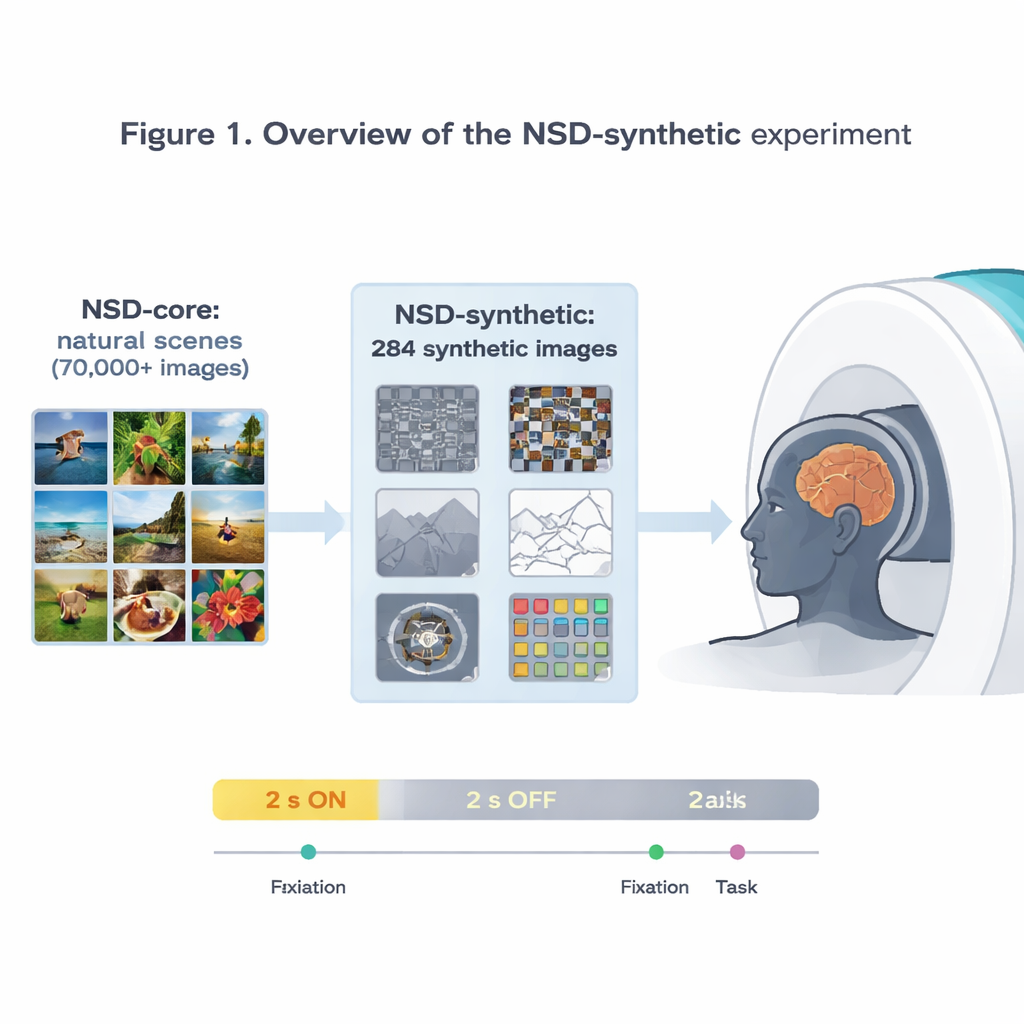
Images étranges, réponses cérébrales fiables
Les images synthétiques couvrent huit familles : différents types de bruit visuel, de simples scènes naturelles et leurs versions altérées (par exemple à l’envers ou en dessin linéaire), des scènes à contraste réduit ou à phase brouillée, des mots isolés placés à divers endroits, des réseaux en spirale qui sondent la sensibilité aux motifs fins, et des taches de bruit très colorées. Pendant que les participants se concentraient soit sur un minuscule point clignotant soit effectuaient une tâche simple de comparaison d’images, les chercheurs ont mesuré l’activité cérébrale toutes les 1,6 secondes. Ils montrent que ces stimuli au look étrange produisent néanmoins des signaux forts et fiables, en particulier dans les zones visuelles précoces qui répondent à des caractéristiques de base comme les contours, le contraste et la couleur. Les motifs d’activité à travers le cortex reflètent les préférences bien connues de régions spécialisées, par exemple une zone sélective aux mots répondant surtout aux mots centrés et une zone sélective aux scènes répondant surtout aux images d’environnements.
Prouver que les données sont vraiment « hors distribution »
Pour que ce nouveau jeu de données mette les modèles au défi, ses réponses cérébrales doivent être réellement différentes de celles évoquées par des photographies naturelles. Les auteurs compressent les motifs d’activité issus à la fois du NSD original et de la session synthétique dans une carte bidimensionnelle qui reflète la similarité des réponses entre images. Dans cet espace, les réponses aux images synthétiques forment des grappes séparées de celles aux photos naturelles, même en tenant compte des différences entre sessions de balayage. De plus, les images synthétiques se regroupent naturellement par type visuel — bruit avec bruit, réseaux avec réseaux, etc. — montrant que le cerveau organise ces stimuli selon leur structure sous-jacente et non seulement leur apparence de surface.
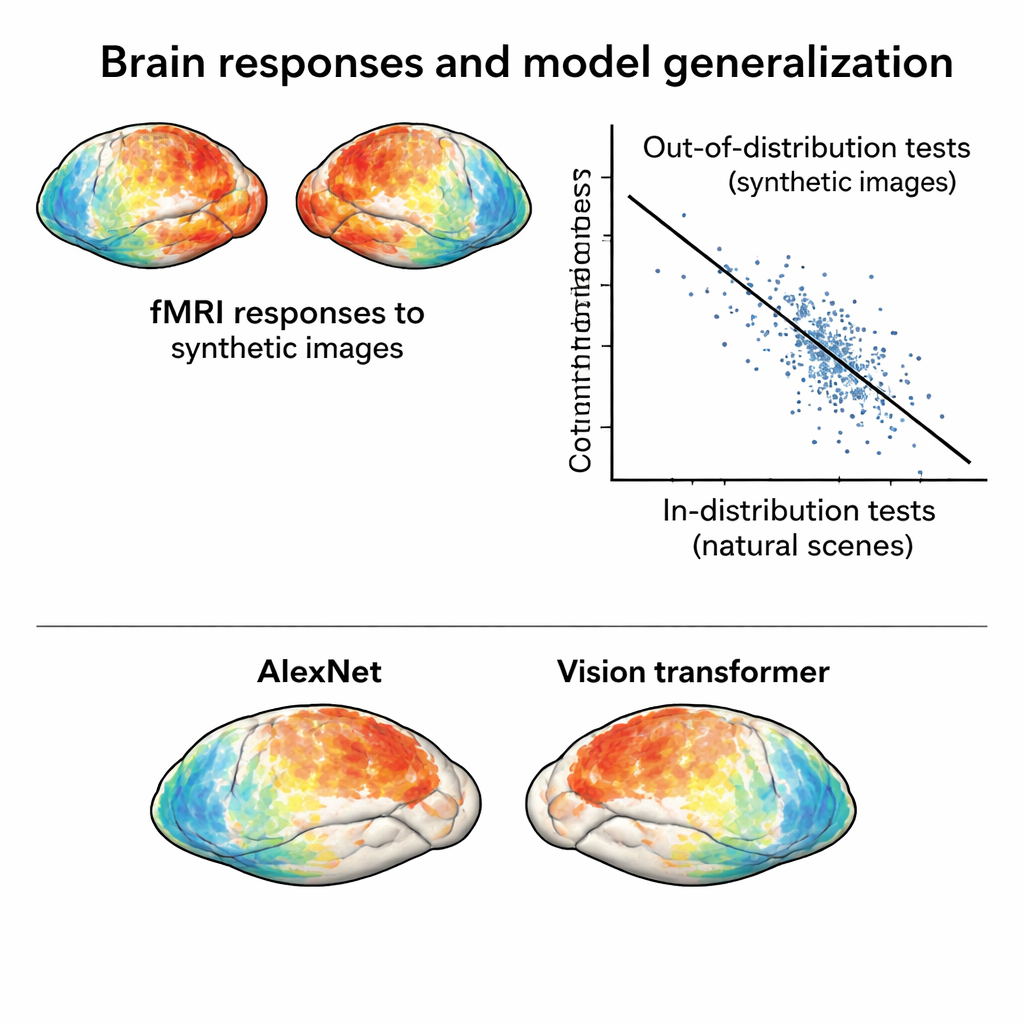
Mettre les modèles cérébraux et d’IA à l’épreuve
Avec ce nouveau jeu de données « hors distribution », l’équipe entraîne des modèles d’encodage standards : des outils mathématiques qui prédisent les réponses cérébrales à partir de caractéristiques d’images extraites par des réseaux neuronaux profonds. Les modèles entraînés uniquement sur les photos naturelles performent bien lorsqu’on les teste sur des photos similaires, mais leur précision chute nettement lorsqu’il s’agit de prédire les réponses aux images synthétiques. Cette baisse n’est pas due à des données bruyantes — les réponses synthétiques sont en réalité très propres — mais à de réelles failles des modèles. Surtout, comparer différentes architectures de réseaux neuronaux dans ces conditions plus strictes révèle des contrastes à peine visibles lors des tests en distribution. Par exemple, un transformeur de vision moderne et un réseau auto-supervisé surpassent tous deux les réseaux convolutionnels classiques face aux images synthétiques, ce qui suggère que la manière dont un modèle est entraîné façonne fortement sa robustesse.
Jusqu’où les modèles peuvent-ils s’éloigner des images familières ?
Les auteurs vont plus loin et traitent la « distance » par rapport aux données d’entraînement comme un continuum, non comme une étiquette binaire. Ils mesurent à quelle distance la réponse cérébrale de chaque image se situe par rapport au nuage de réponses aux scènes naturelles. Plus une image synthétique est éloignée dans cet espace, plus les modèles ont tendance à être moins performants et moins capables d’identifier précisément quelle image une personne a vue à partir de l’activité cérébrale seule. Ils montrent aussi que même parmi les photographies ordinaires, des ensembles de test judicieusement choisis peuvent se comporter comme « légèrement hors distribution » : les modèles performent le mieux sur des images tirées du même groupe que leur jeu d’entraînement, moins bien sur des scènes naturelles éloignées, et le pire sur les stimuli synthétiques. Ce tableau gradué transforme le nouveau jeu de données en un outil pour sonder précisément quels types de structure visuelle les modèles actuels manquent.
Ce que cela signifie pour la recherche future sur le cerveau et l’IA
Pour les non‑spécialistes, le message clé est que de bonnes performances sur des images familières n’assurent pas qu’un modèle d’IA inspiré du cerveau ait véritablement capturé la façon dont nous voyons. En publiant NSD‑synthetic aux côtés du NSD original, les auteurs fournissent une « piste de crash test » publique pour les modèles de vision : un moyen de voir où ils échouent lorsque les images deviennent plus abstraites, plus colorées ou moins naturelles. Parce que le jeu de données est accessible publiquement et étroitement intégré à une ressource existante largement utilisée, il est susceptible de devenir une référence standard pour tester et améliorer les théories de la vision humaine et les réseaux artificiels qui cherchent à l’imiter.
Citation: Gifford, A.T., Cichy, R.M., Naselaris, T. et al. A 7T fMRI dataset of synthetic images for out-of-distribution modeling of vision. Nat Commun 17, 1589 (2026). https://doi.org/10.1038/s41467-026-69345-9
Mots-clés: cortex visuel, jeu de données IRMf, images synthétiques, hors distribution, réseaux neuronaux profonds