Clear Sky Science · fr
Mécanismes computationnels neuronaux d’un seul neurone pour le codage des objets visuels dans le lobe temporal humain
Comment le cerveau sait ce que nous regardons
Chaque fois que vous jetez un coup d’œil à une rue animée, votre cerveau identifie instantanément quelles formes sont des personnes, quelles sont des voitures et quels sont des panneaux, même si elles sont partiellement cachées ou mal éclairées. Cet article pose une question apparemment simple : comment le cerveau humain transforme-t-il l’afflux de détails visuels bruts qui arrive à nos yeux en idées stables comme « chien » ou « tasse » que nous pouvons reconnaître, mémoriser et nommer ?
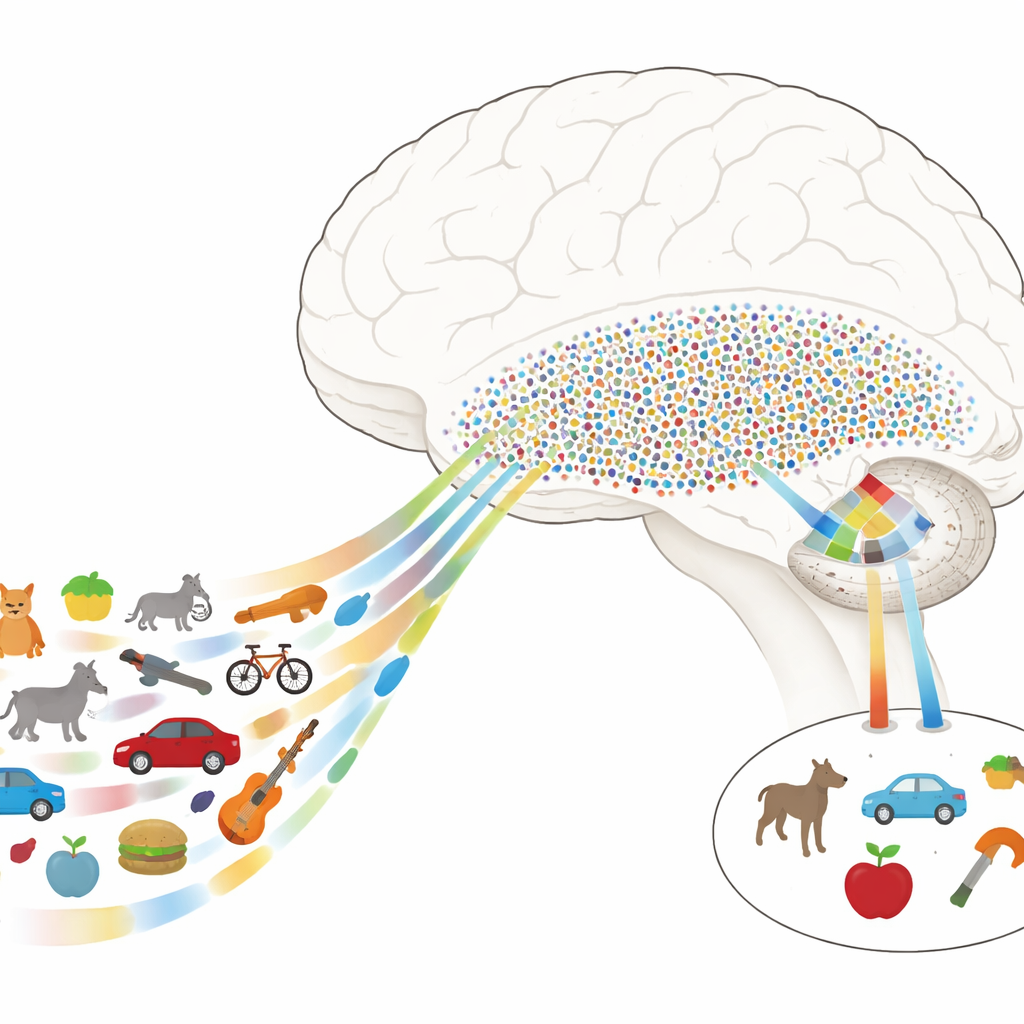
Des images détaillées aux choses qui ont du sens
Les scientifiques savent que la reconnaissance des objets repose largement sur une chaîne de régions situées à la face inférieure du cerveau, appelée voie visuelle ventrale. Les stades précoces traitent des caractéristiques simples comme les contours et les textures, tandis que les stades ultérieurs s’intéressent davantage aux objets entiers et à leur signification. Chez l’humain, un tronçon clé de cette voie est le cortex temporal ventral (CTV), et juste en aval se trouve le lobe temporal médial (LTM), essentiel pour la mémoire. Le mystère a été de comprendre comment le cerveau passe des descriptions détaillées, quasi photographiques du CTV aux codes clairsemés et conceptuels du LTM qui permettent à quelques neurones de représenter de nombreuses vues différentes d’un même objet.
Une carte neuronale de l’espace des objets
Les auteurs ont enregistré l’activité électrique directement dans le cerveau de patients épileptiques qui avaient déjà des électrodes implantées pour des raisons médicales. Pendant que les patients effectuaient une tâche simple, ils ont vu des centaines d’images naturelles appartenant à de nombreuses catégories — animaux, outils, aliments, véhicules, plantes, et plus encore. Dans le CTV, les chercheurs ont observé que les réponses pouvaient être décrites comme des combinaisons de quelques directions de caractéristiques clés, ou « axes », par exemple à quel point quelque chose paraît naturel versus fabriqué, ou animé versus inanimé. En combinant mathématiquement ces axes, ils ont construit un « espace de caractéristiques neuronal » dans lequel chaque image occupe une position, et des objets similaires se regroupent même s’ils diffèrent par des détails de bas niveau.
De grilles de caractéristiques denses à des pôles conceptuels clairsemés
Dans cet espace de caractéristiques neuronal, le CTV agit comme une grille dense : de nombreux sites participent à la représentation de chaque objet, codant des différences visuelles fines. En revanche, les neurones enregistrés un par un dans le LTM se comportaient très différemment. Plutôt que de suivre des caractéristiques individuelles, bon nombre de ces cellules répondaient fortement seulement aux objets tombant dans des régions particulières de l’espace de caractéristiques du CTV. Chaque neurone avait en pratique un « champ récepteur » non pas dans l’espace physique, mais dans cette carte abstraite des propriétés des objets. Les objets situés à l’intérieur de la région préférée d’un neurone partageaient souvent des traits perceptifs (par exemple des formes arrondies ou des teintes verdâtres) et des significations de plus haut niveau (telles qu’être des êtres vivants ou des outils), amenant ce neurone à émettre des décharges de manière rare mais sélective.
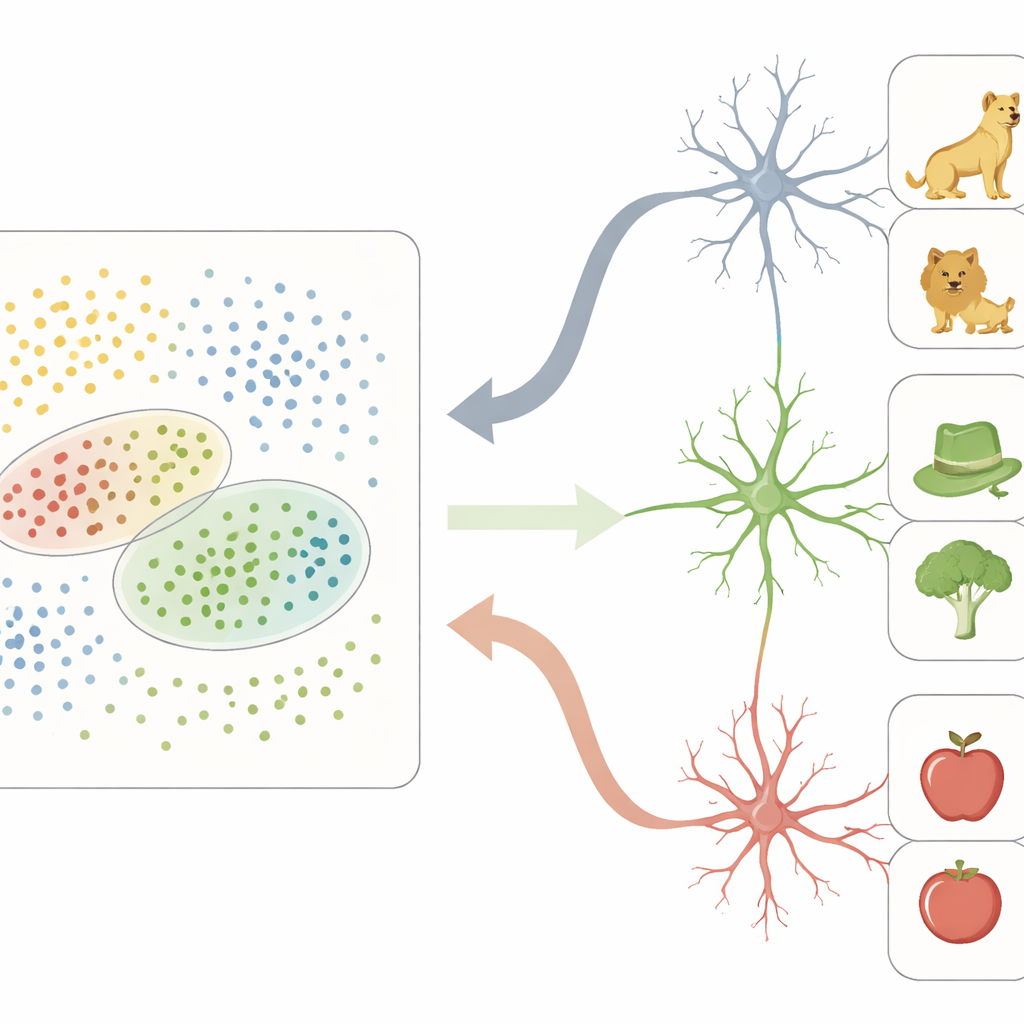
Relier la vision et la mémoire
Pour montrer que ce n’est pas qu’un artifice mathématique, l’équipe a examiné comment ces régions cérébrales interagissent en temps réel. Ils ont constaté que les sites du CTV portant de forts signaux d’axes de caractéristiques étaient particulièrement synchronisés avec des sites du LTM sensibles aux catégories, notamment dans certaines ondes rythmiques du cerveau. L’information avait tendance à circuler du CTV vers le LTM à des fréquences plus basses associées au traitement feedforward, tandis que le feedback du LTM vers le CTV se manifestait à des fréquences légèrement plus élevées. De façon cruciale, lorsqu’un neurone du LTM était accordé à une région spécifique de l’espace des caractéristiques, ses pointes s’alignaient sur des rythmes rapides du CTV, et ce couplage était plus fort pour les images mêmes que ce neurone codait. Un second ensemble d’expériences utilisant une collection d’images différente a confirmé que la carte de caractéristiques du CTV et l’accord des neurones du LTM aux régions étaient stables entre les jeux de stimuli.
Pourquoi cela compte pour la vision et la mémoire quotidiennes
Au total, ces résultats étayent un récit computationnel concret : le CTV disperse les objets visuels le long d’axes de caractéristiques significatifs, formant un paysage riche et continu, et le LTM place de petits « pointeurs » sélectifs sur des régions de ce paysage. Cette transformation convertit un code-image détaillé et distribué en un code-concept clairsemé, plus facile à stocker, à récupérer et à combiner avec d’autres souvenirs. Pour un non-spécialiste, la conclusion est que reconnaître un chien par une nuit pluvieuse n’est pas une simple recherche dans une base de données, mais le résultat d’un processus en couches et coopératif où une partie du cerveau construit une carte structurée des apparences et une autre apprend à marquer et à lire des régions de cette carte comme des idées distinctes et durables.
Citation: Cao, R., Zhang, J., Zheng, J. et al. Computational single-neuron mechanisms of visual object coding in the human temporal lobe. Nat Commun 17, 2234 (2026). https://doi.org/10.1038/s41467-026-68954-8
Mots-clés: reconnaissance d’objets, cortex temporal ventral, lobe temporal médial, codage neural, mémoire visuelle