Clear Sky Science · fr
Le diamant d’ADN formule un modèle décomposable de constellation de lettres composites pour le stockage de données dans l’ADN
Pourquoi les données futures pourraient vivre dans l’ADN
Nos téléphones, entreprises et instruments scientifiques génèrent des données bien plus rapidement que les disques durs et les bandes magnétiques ne peuvent augmenter leur capacité. L’ADN — la même molécule qui porte l’information génétique chez les êtres vivants — peut aussi servir à stocker des fichiers numériques de façon extrêmement compacte et durable. Cet article présente une nouvelle méthode pour encoder encore plus d’information dans des brins d’ADN synthétique tout en restant pratique et fiable à relire, ce qui pourrait rendre le stockage sur ADN moins cher et plus évolutif.
Des quatre lettres de l’ADN à des mélanges plus riches
Le stockage traditionnel sur ADN utilise les quatre bases naturelles — A, T, G et C — pour représenter des bits numériques, un peu comme les zéros et les uns sur un disque. Dans ce schéma, chaque position d’un brin d’ADN peut porter au maximum deux bits d’information, car elle est limitée à l’une des quatre options. Les auteurs prolongent une idée émergente : au lieu de placer une seule base à chaque position, on crée des mélanges contrôlés de bases, appelés lettres composites. Par exemple, une position peut être composée d’un mélange 50:50 de A et T, ou d’un mélange 25:25:25:25 des quatre bases. Lorsque de nombreuses copies de chaque brin sont synthétisées, le séquençage de ces mélanges révèle les proportions de bases et, en retour, un symbole numérique qui peut représenter plus de deux bits.
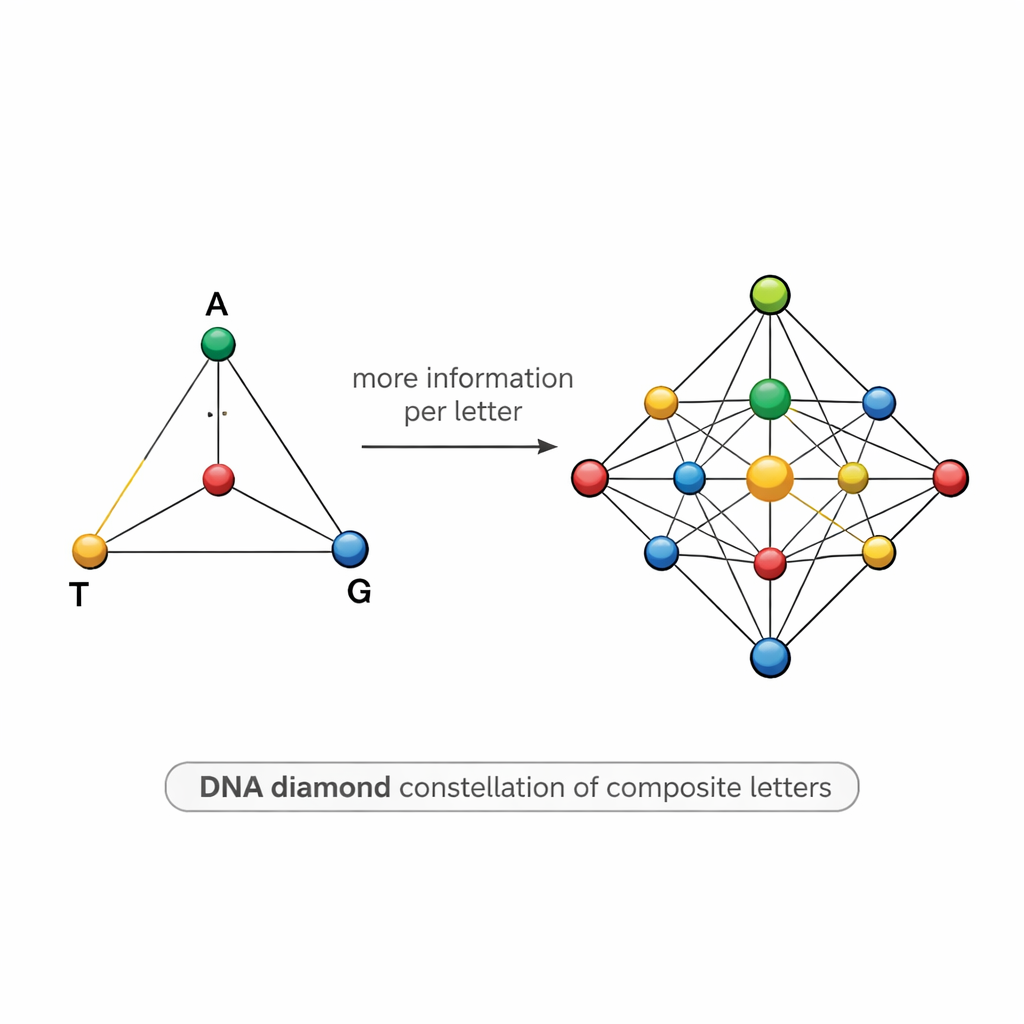
Une carte en forme de diamant des symboles ADN
Concevoir de tels mélanges est délicat. Si deux symboles sont trop similaires — par exemple, l’un est 50 % A et 50 % T et l’autre 55 % A et 45 % T — le bruit du séquençage peut les confondre, provoquant des erreurs et obligeant les chercheurs à séquencer beaucoup plus de copies qu’ils ne le souhaiteraient. Pour y remédier, l’équipe propose un modèle structuré appelé « diamant d’ADN » : un ensemble de 15 lettres composites disposées comme des points sur un tétraèdre dont les sommets sont A, T, G et C. L’ensemble inclut les bases pures aux sommets, des mélanges égaux de deux bases le long des arêtes, des mélanges de trois bases sur chaque face, et un mélange parfaitement homogène des quatre bases au centre. Cette constellation soigneusement choisie élève la quantité théorique d’information par position à environ 3,9 bits, tout en maintenant les symboles suffisamment distincts pour être distingués en pratique.
Décodage plus intelligent avec entropie et indexation
Relire les données depuis l’ADN implique d’inférer quelle lettre composite était prévue à chaque position à partir de mesures bruitées des fréquences de bases. Les auteurs empruntent une stratégie aux télécommunications appelée partitionnement d’ensembles. D’abord, ils évaluent à quel point une position paraît « mélangée », en utilisant une quantité appelée entropie, qui est faible pour les bases pures et plus élevée pour les mélanges complexes. Cela permet d’attribuer rapidement chaque position à l’un des quatre groupes : bases pures, mélanges de deux bases, mélanges de trois bases ou mélange des quatre bases. Ensuite, au sein du groupe choisi, un calcul de vraisemblance plus précis sélectionne la lettre la plus probable. Cette approche en deux étapes réduit la confusion entre symboles et diminue le temps de calcul par rapport aux méthodes antérieures. Pour éviter que des brins ne soient pris les uns pour les autres, chaque fragment d’ADN porte des séquences d’index protégées contre les erreurs à ses deux extrémités, et les lectures de longueur incorrecte — souvent causées par des insertions ou suppressions — sont filtrées avant le décodage.
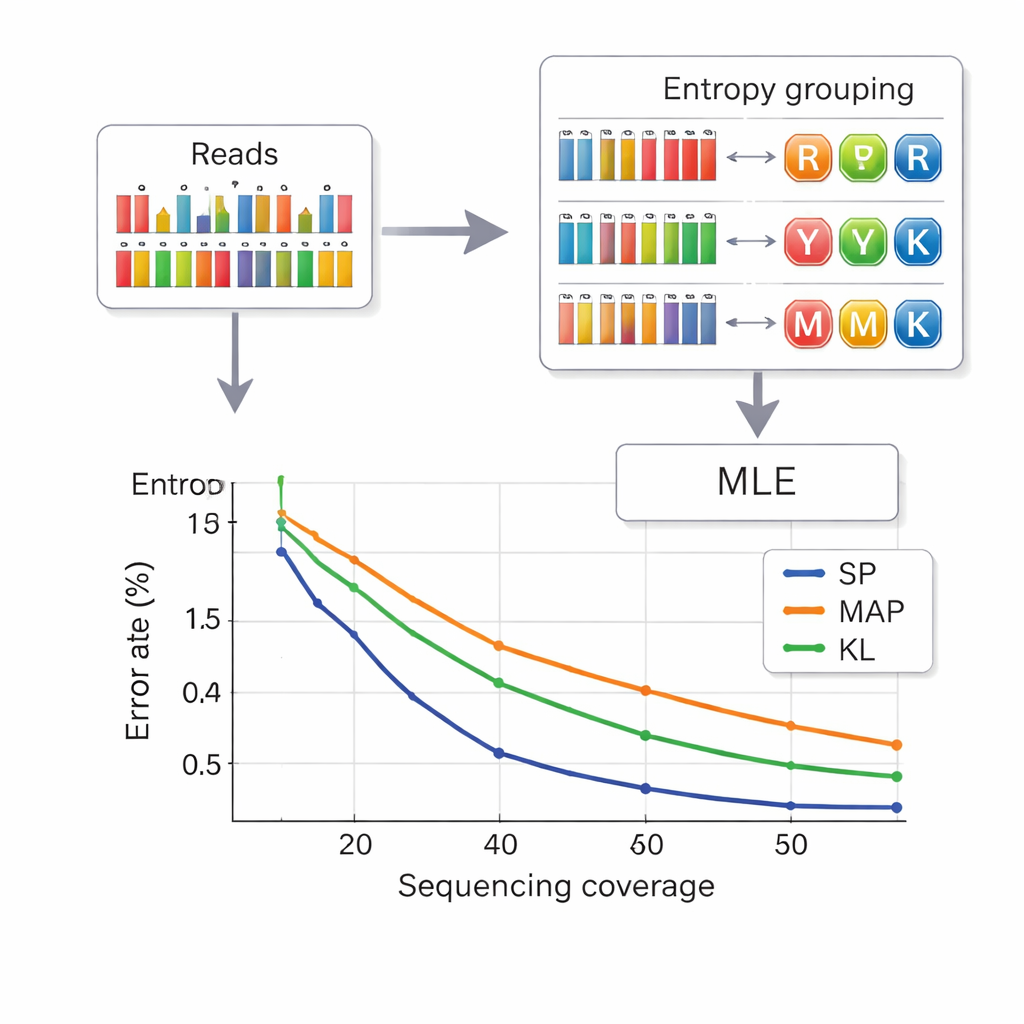
Stocker plus de données avec moins de lectures
Les chercheurs ont testé leur système à la fois sur de petits et grands pools d’ADN, en utilisant des plateformes de synthèse commerciales. Avec un alphabet composite à huit lettres, ils ont atteint une densité utile de 2,5 bits par position d’ADN et ont pu récupérer les fichiers parfaitement avec en moyenne 14 lectures de séquençage par brin — une meilleure densité que les schémas antérieurs à six lettres tout en nécessitant moins de lectures. Avec l’alphabet complet à 15 lettres du diamant d’ADN, ils ont atteint 3,125 bits par position pour les données principales et ont quand même tout récupéré sans erreur avec une couverture de 33x. Des simulations et des expériences ont également montré que leur méthode basée sur l’entropie fonctionne presque aussi bien que l’approche de décodage la plus précise mais plus lente, et nettement mieux que les techniques plus anciennes, surtout à des profondeurs de séquençage plus faibles.
Ce que cela signifie pour la mémoire du futur
Pour un lecteur non spécialiste, le message clé est que les auteurs ont trouvé un moyen d’apprendre « de nouveaux tours » à l’ADN sans inventer de nouvelle chimie : en mélangeant ingénieusement les quatre bases existantes et en les décodant plus intelligemment, ils peuvent stocker davantage de bits par molécule tout en maîtrisant les coûts. Leur alphabet en forme de diamant, combiné à une indexation robuste et à une correction d’erreurs, montre que le stockage de données à haute capacité sur ADN est possible avec un effort de séquençage relativement modeste. À mesure que la synthèse et le séquençage de l’ADN continuent de devenir moins chers, de tels designs pourraient aider à transformer l’ADN d’une curiosité de laboratoire en un support réaliste pour archiver les souvenirs numériques du monde.
Citation: Ge, Q., Ren, M., Qi, T. et al. DNA diamond formulates a decomposable composite letter constellation model for DNA data storage. Nat Commun 17, 1704 (2026). https://doi.org/10.1038/s41467-026-68861-y
Mots-clés: stockage de données ADN, lettres composites, densité d’information, correction d’erreurs, archivage numérique