Clear Sky Science · fr
Base de données sur les nanoparticules lipidiques pour la modélisation structure-fonction et la conception axée sur les données pour la délivrance d'acides nucléiques
Pourquoi de minuscules bulles lipidiques comptent pour les médicaments de demain
Les nanoparticules lipidiques sont de minces bulles à base de lipides qui transportent en toute sécurité des instructions génétiques—comme les vaccins à ARNm—jusqu'à nos cellules. Elles ont été déterminantes pour les vaccins contre la COVID‑19, mais les chercheurs ne comprennent pas encore complètement comment leur composition chimique détaillée gouverne leur efficacité. Cet article présente une nouvelle ressource en ligne, la Lipid Nanoparticle Database (LNPDB), créée pour rassembler des données dispersées en un seul lieu afin que les scientifiques puissent concevoir de manière systématique des médicaments géniques meilleurs et plus sûrs.
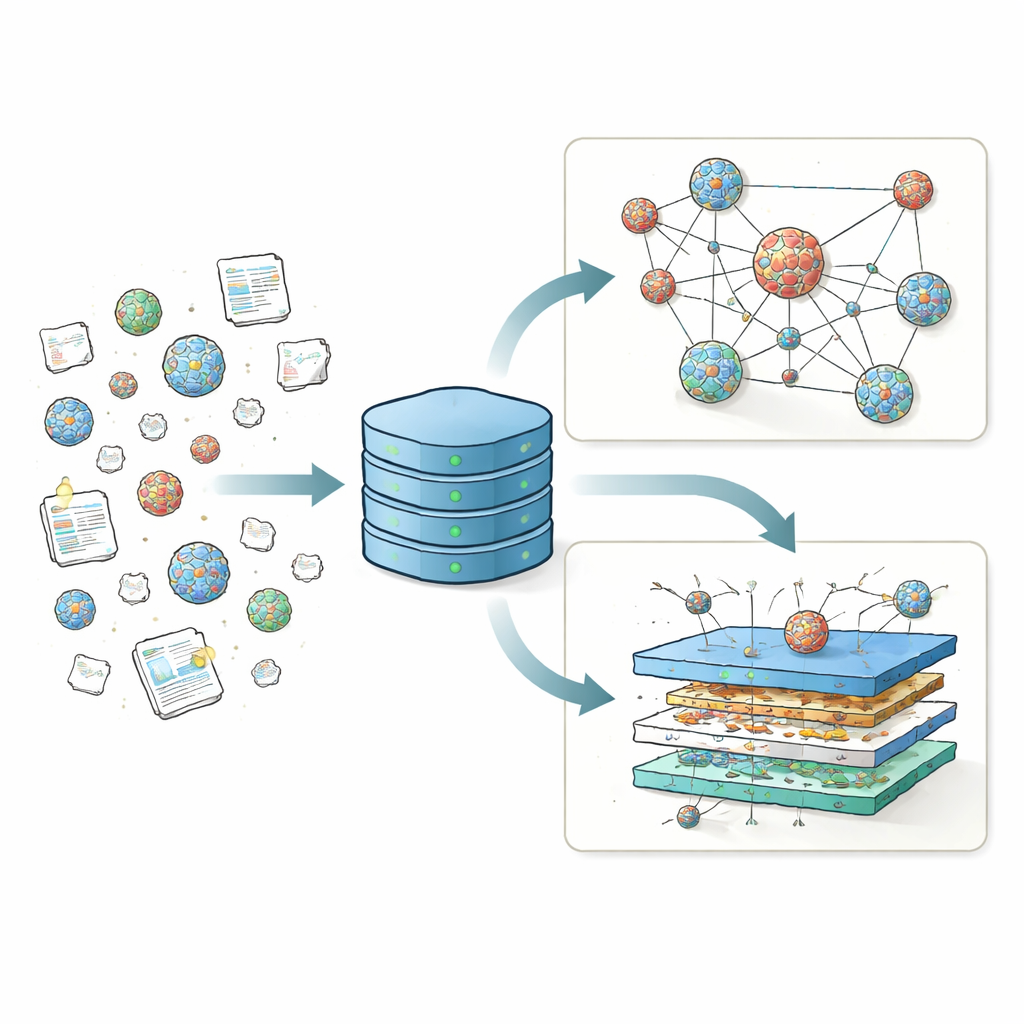
Rassembler des résultats disséminés en un seul endroit
Pendant des années, différents laboratoires ont testé des milliers de recettes de nanoparticules lipidiques (LNP), en modifiant le lipide principal chargé, les lipides auxiliaires, le cholestérol et les lipides constituant le revêtement protecteur pour déterminer quelles combinaisons délivrent le matériel génétique le plus efficacement. Mais ces résultats ont été publiés dans de nombreux formats à travers des dizaines d'articles, rendant difficiles les comparaisons entre études ou l'identification de tendances globales. Contrairement à la science des protéines, soutenue par une base centrale comme la Protein Data Bank qui a alimenté des outils tels qu'AlphaFold, le domaine des LNP ne disposait pas d'un dépôt unifié pour ses données de structure et de performance. LNPDB comble cette lacune en collectant des informations détaillées sur 19 528 formulations de LNP issues de 42 études et d'un fournisseur commercial, et en standardisant la façon dont les ingrédients, les conditions d'essai et les résultats de chaque particule sont encodés.
Ce que contient la nouvelle base de données
Chaque entrée LNP dans LNPDB est décrite selon trois axes principaux : composition, expérience et simulation. Les champs de composition enregistrent quels lipides ont été utilisés, combien d'atomes d'azote contient le lipide chargé principal, et les ratios de mélange exacts entre les quatre composants de base : lipide ionisable, lipide auxiliaire, cholestérol et un lipide à polyéthylène glycol (PEG). Les champs expérimentaux capturent quel type de cargaison génétique a été délivré—souvent de l'ARNm codant pour une protéine rapporteur—où elle a été envoyée (par exemple, des cellules en culture, le foie, les poumons ou le muscle), comment les particules ont été préparées et comment le succès a été mesuré. Enfin, les champs de simulation fournissent des fichiers prêts à l'emploi décrivant le comportement physique de chaque molécule lipidique avec suffisamment de précision pour exécuter des simulations informatiques à l'échelle atomique de membranes lipidiques. Ensemble, ces descripteurs standardisés transforment un patchwork de criblages individuels en un paysage cohérent qui peut être recherché, filtré et enrichi par la communauté.
Apprendre aux ordinateurs à repérer de meilleures recettes de délivrance
Une utilisation immédiate de LNPDB est d'améliorer les modèles d'apprentissage automatique qui prédisent quelles formulations délivreront le matériel génétique le plus efficacement. Les auteurs ont réentraîné leur modèle d'apprentissage profond existant, appelé LiON, avec le jeu de données étendu de LNPDB, doublant plus que le nombre d'exemples qu'il avait vus auparavant. LiON apprend des motifs reliant les structures chimiques des lipides ionisables, la composition des composants auxiliaires et le contexte d'essai à la performance de chaque formulation. Grâce à des données plus riches, les prédictions de LiON concordent mieux avec les résultats expérimentaux pour la plupart des jeux de test et surpassent un modèle concurrent nommé AGILE sur plusieurs jeux de données indépendants. Cela suggère qu'un ensemble d'entraînement large, diversifié et en croissance continue est essentiel pour construire des outils de conception à usage général pour les futurs médicaments à base de LNP.
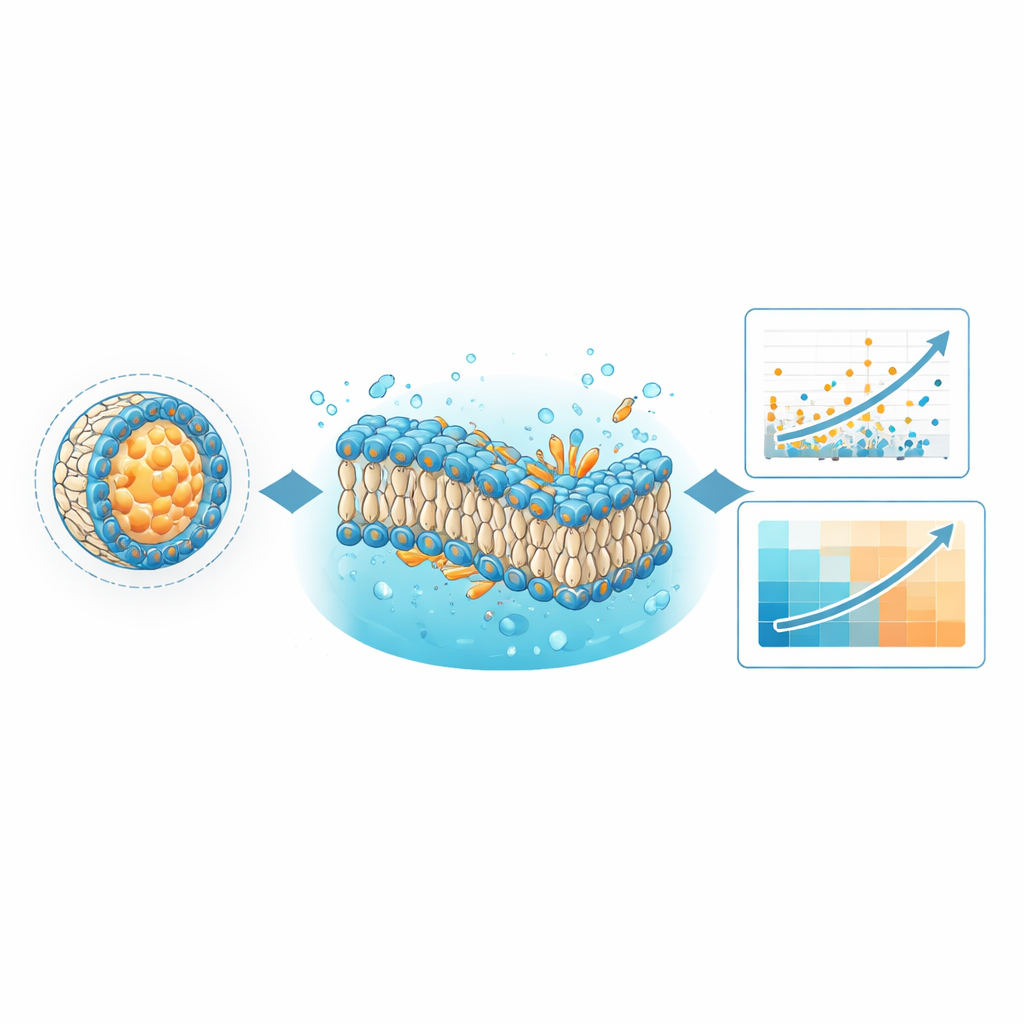
Observer des membranes modèles pour découvrir des règles cachées
La base de données est également conçue pour un type de calcul très différent : les simulations physico‑chimiques de dynamique moléculaire. En utilisant les fichiers de simulation fournis avec LNPDB, l'équipe a construit des membranes simplifiées représentant des formulations LNP sélectionnées et a observé leur comportement sur des microsecondes de temps simulé. Ils ont posé deux questions : les bicouches lipidiques modélisées restent‑elles intactes, et quelle forme globale les lipides clés adoptent‑ils au sein de la membrane ? Les simulations ont révélé que les formulations dont les membranes restaient stables avaient plus de chances de réussir expérimentalement. Elles ont aussi quantifié une caractéristique appelée « paramètre de compactage critique », qui reflète si un lipide a une forme plutôt conique ou conique inversée dans la membrane. Dans plusieurs bibliothèques testées, les lipides dont la forme favorisait une courbure négative—pensée pour aider les particules à fusionner avec et perturber les membranes endosomales—ont montré une délivrance plus efficace, parfois en corrélation avec la performance mieux que le modèle d'apprentissage profond lui‑même.
Une nouvelle base pour une nanomédecine plus intelligente
Pour un non‑spécialiste, le message principal est que ce travail construit une « carte » partagée et évolutive montrant comment les ingrédients et la structure de ces minuscules bulles lipidiques se rapportent à leur capacité à délivrer des thérapies génétiques. En rassemblant des dizaines de milliers d'expériences passées, en permettant des modèles prédictifs puissants et en fournissant des outils pour simuler le comportement des particules au niveau moléculaire, LNPDB pose les bases d'une conception plus rationnelle plutôt que d'un tâtonnement par essais‑erreurs. Avec le temps, cette approche axée sur les données pourrait accélérer la création de vaccins plus efficaces, de traitements d'édition génétique et d'autres thérapies à base d'acides nucléiques, tout en aidant les chercheurs à comprendre pourquoi certaines recettes de nanoparticules fonctionnent—et d'autres non.
Citation: Collins, E., Ji, J., Kim, SG. et al. Lipid Nanoparticle Database towards structure-function modeling and data-driven design for nucleic acid delivery. Nat Commun 17, 2464 (2026). https://doi.org/10.1038/s41467-026-68818-1
Mots-clés: nanoparticules lipidiques, délivrance d'ARNm, nanomédecine, apprentissage automatique, dynamique moléculaire