Clear Sky Science · fr
Progrès et défis du stockage de données dans des acides nucléiques non canoniques
Pourquoi le stockage de données dans des molécules importe
Chaque photo, message et film que nous créons doit être conservé quelque part, et aujourd’hui ce « quelque part » consiste surtout en d’immenses entrepôts de disques durs qui consomment beaucoup d’électricité et s’usent en quelques décennies. Cet article explore une approche très différente : utiliser des molécules génétiques spécialement conçues comme de minuscules bandes magnétiques. En modifiant les blocs de construction familiers de l’ADN et de l’ARN, les scientifiques cherchent à obtenir un stockage d’information plus dense, plus robuste et plus sûr que n’importe quelle puce électronique ou disque magnétique.
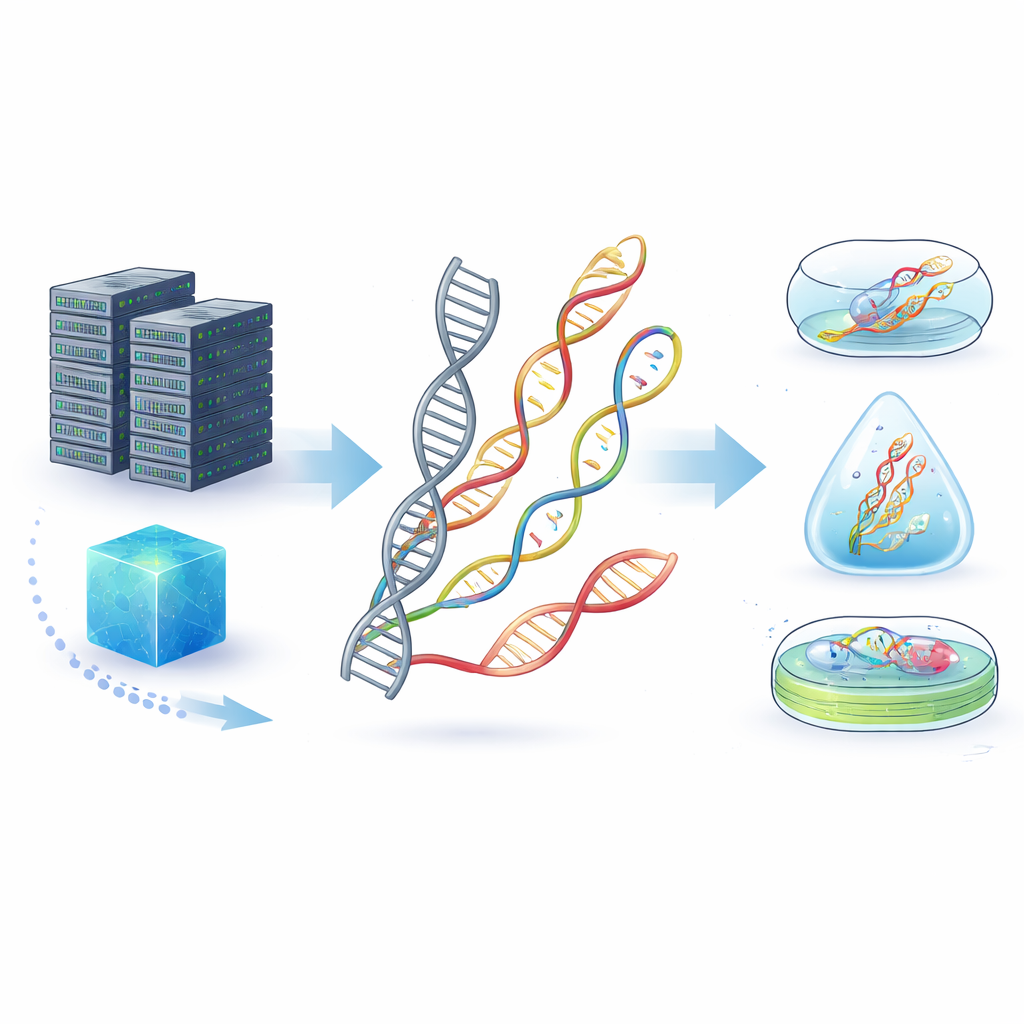
De l’ADN fragile à de nouvelles molécules résistantes
L’ADN naturel est déjà un support de stockage impressionnant, emballant d’énormes quantités d’information dans un espace microscopique et pouvant survivre des dizaines de milliers d’années dans des fossiles. Mais dans des conditions quotidiennes — chaleur, humidité, produits chimiques divers ou enzymes qui dégradent l’ADN — il peut se détériorer rapidement. Les auteurs présentent les « acides nucléiques non canoniques » (ncNA) : des molécules apparentées à l’ADN et à l’ARN dont les bases, les sucres ou le squelette ont été chimiquement modifiés, voire inversés, pour leur conférer de nouvelles propriétés. Ces changements peuvent rendre les molécules plus difficiles à dégrader par les enzymes, plus résistantes aux acides ou aux bases, et mieux à même de survivre à des environnements réels hostiles que l’ADN ordinaire.
Ajouter de nouvelles lettres à l’alphabet génétique
Une des idées les plus puissantes de la revue est d’élargir l’alphabet génétique au-delà des quatre lettres habituelles A, T, G et C. Les chimistes ont créé des paires de bases supplémentaires qui tiennent encore dans des doubles hélices mais n’existent pas à l’état naturel. Avec 8, 12 lettres ou plus, chaque position le long du brin peut coder davantage de bits d’information, augmentant la capacité de stockage bien au-delà de ce que l’ADN standard peut offrir. Certaines de ces nouvelles bases sont conçues pour s’apparier par des interactions hydrophobes plutôt que par les liaisons hydrogène habituelles, montrant que les règles de l’appariement naturel peuvent être contournées tout en gardant l’information lisible.
Reconstruire le squelette moléculaire
Outre la modification des « lettres », les chercheurs revisitent aussi le sucre et l’épine dorsale qui maintiennent un brin génétique. Remplacer le sucre habituel par des alternatives comme la thréose ou l’hexitol, ou substituer les liaisons phosphate chargées par des liaisons neutres ou contenant du soufre, peut modifier radicalement le comportement du brin. Nombre de ces ncNA présentent une stabilité remarquable dans des conditions chaudes, acides ou riches en enzymes où l’ADN naturel se décomposerait rapidement. Certaines versions en image miroir, telles que l’ADN L, sont invisibles pour les enzymes et les défenses immunitaires normales, ce qui les rend prometteuses pour un stockage ultra-sécurisé et des messages cachés, bien qu’elles soient actuellement coûteuses et difficiles à synthétiser et à lire.
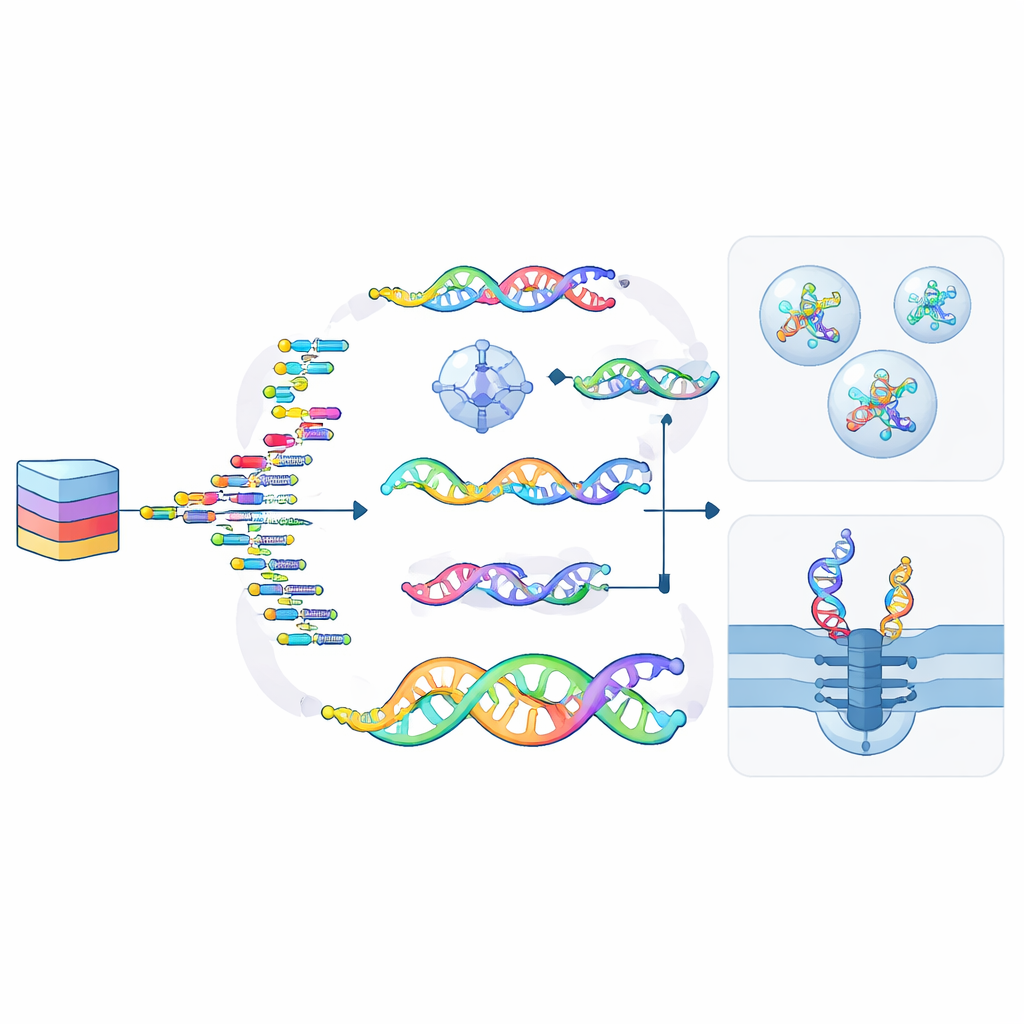
Comment les données sont écrites, conservées et lues
La conversion de fichiers numériques en forme moléculaire suit un cycle en quatre étapes : encodage, écriture, conservation et lecture. Les bits sont d’abord traduits en séquences ou en structures, qui sont ensuite synthétisées sous forme de brins ncNA par des méthodes chimiques ou des enzymes spécialement conçues. Ces brins peuvent être stockés hors des cellules — encapsulés dans du verre, de la silice ou des polymères — ou à l’intérieur de cellules et même de plantes modifiées, où les mécanismes naturels de réparation peuvent aider à les entretenir. La lecture des données peut utiliser des séquenceurs d’ADN familiers, des dispositifs nanopore avancés qui détectent chaque unité en la faisant passer par un petit trou, ou des microscopes qui reconnaissent des formes dans des nanostructures repliées. Parce que de nombreux ncNA ne peuvent pas encore être séquencés directement, ils sont souvent reconvertis en ADN ordinaire avant la lecture, une étape que la recherche actuelle cherche à simplifier et à améliorer.
Nouvelles possibilités : calcul, sécurité et écriture parallèle
L’article souligne que les ncNA font plus que stocker des données : ils peuvent aussi les traiter. Des circuits logiques et des réseaux neuronaux basés sur l’ADN existent déjà, et l’ajout d’alphabets chimiquement distincts facilite l’exécution de nombreuses opérations en parallèle sans interférences indésirables. Certaines modifications agissent comme de l’encre invisible, permettant d’occulter de l’information dans des brins ou des structures que seules des enzymes ou des conditions spéciales peuvent révéler. D’autres, comme des adduits chimiques réversibles ou des motifs de groupes méthyle, se comportent comme des caractères mobiles sur une presse : ils peuvent imprimer des données sur des brins existants en parallèle, les effacer et les réécrire sans reconstruire entièrement la molécule.
Défis à venir et ce que la réussite représenterait
Malgré les promesses, les auteurs insistent sur le fait que le stockage sur acides nucléiques non canoniques en est encore à un stade précoce. Produire des brins longs et sans erreur est coûteux et techniquement exigeant, et nombre des chimies les plus prometteuses ne sont pas encore compatibles avec des technologies de lecture rapides et abordables. Des questions importantes de sécurité et d’éthique se posent également quant à l’introduction de molécules hautement stables et partiellement artificielles dans des systèmes vivants. Néanmoins, la revue trace une feuille de route où une synthèse plus rapide, une encapsulation plus intelligente et des lecteurs nanopore améliorés par intelligence artificielle pourraient rendre le stockage basé sur les ncNA pratique dans les décennies à venir. Si cela se réalise, nous pourrions un jour sauvegarder notre civilisation numérique non pas sur des disques rotatifs, mais dans de minuscules brins robustes de molécules conçues sur mesure.
Citation: Wang, Y., Pei, Y., Tang, L. et al. Advances and challenges in non-canonical nucleic acids data storage. Nat Commun 17, 2354 (2026). https://doi.org/10.1038/s41467-026-68708-6
Mots-clés: Stockage de données sur ADN, acides nucléiques non canoniques, mémoire moléculaire, paires de bases artificielles, séquençage par nanopore