Clear Sky Science · fr
Accélérateurs neuronaux nanophotoniques conçus par inversion pour un calcul optique ultra‑compact
Pourquoi il est important de miniaturiser les ordinateurs faits de lumière
L’intelligence artificielle moderne s’appuie sur d’immenses infrastructures électroniques qui consomment énormément d’énergie et dégagent de la chaleur. Cette étude explore une voie très différente : utiliser de minuscules motifs de lumière sur une puce, plutôt que des flux d’électrons, pour effectuer des parties du calcul des réseaux neuronaux. Les auteurs montrent qu’en « sculptant » la lumière à l’échelle nanométrique, ils peuvent construire des accélérateurs optiques ultra‑compacts capables de reconnaître des chiffres manuscrits et des images médicales tout en occupant beaucoup moins d’espace et, en principe, en consommant beaucoup moins d’énergie que l’électronique actuelle.
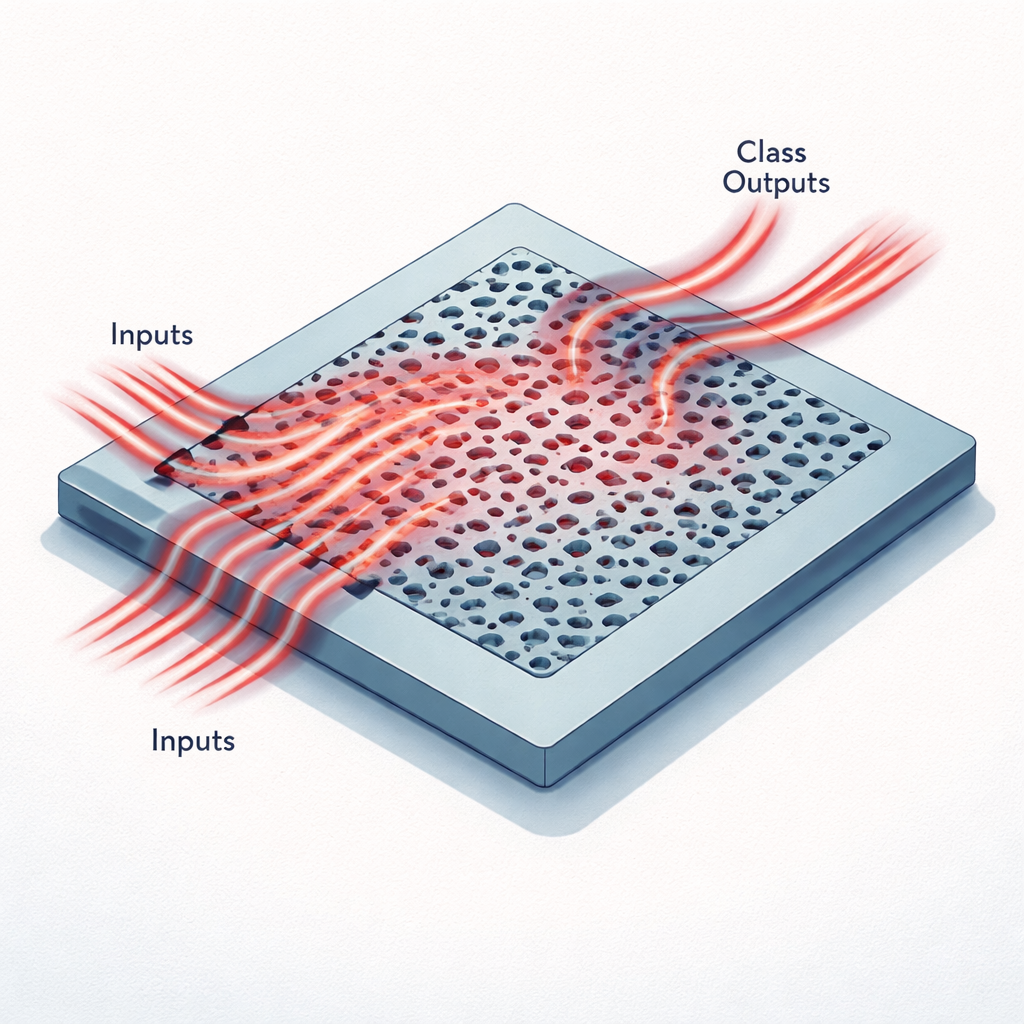
Des puces minuscules qui réfléchissent avec la lumière
Au lieu de fils et de transistors, ces accélérateurs utilisent une plaque de silicium plane structurée avec des trous et des canaux plus petits que la longueur d’onde de la lumière infrarouge. Les données d’une image sont d’abord compressées en un petit ensemble de nombres, qui sont ensuite encodés sous forme d’intensité lumineuse entrant dans plusieurs guides d’ondes étroits à une seule longueur d’onde télécom. Lorsque cette lumière pénètre dans la région structurée, elle est diffusée, interfère avec elle‑même et est redirigée vers une poignée de guides de sortie. Chaque sortie correspond à une classe possible, comme l’un des dix chiffres du jeu de données MNIST ou l’une des six catégories du jeu d’images médicales appelé MedNIST. La répartition de la puissance optique en sortie joue le même rôle que la dernière couche d’un réseau neuronal numérique.
Laisser les algorithmes dessiner le plan optique
Concevoir une telle structure à la main serait presque impossible, car chaque petit « voxel » de matériau peut modifier la propagation de la lumière. Les chercheurs utilisent donc une approche de conception par inversion : ils partent d’un motif aléatoire de silicium et de verre, simulent la propagation de la lumière en trois dimensions, puis ajustent le motif pour réduire une fonction de perte qui mesure les erreurs de classification. Ils tirent parti de la linéarité des équations de Maxwell — les lois qui régissent la lumière — pour rendre cet entraînement efficace. Plutôt que de simuler chaque image d’entraînement séparément, ils simulent chaque canal d’entrée une fois, puis reconstruisent les champs pour toutes les images comme combinaisons linéaires de ces champs précalculés. Une technique mathématique appelée méthode adjointe fournit alors des gradients exacts qui indiquent à l’algorithme comment modifier chaque voxel pour améliorer les performances.

Des classificateurs d’images compacts sur un grain de sable
Grâce à cette stratégie, l’équipe a conçu deux accélérateurs neuronaux nanophotoniques sur une plateforme standard silicium‑sur‑isolant. L’un, d’à peine 20 par 20 micromètres, classe des chiffres manuscrits du jeu MNIST ; l’autre, de 30 par 20 micromètres, classe des images médicales de MedNIST. En simulation, ces dispositifs minuscules ont atteint des précisions de 97,8 % et 99,1 % respectivement. Des versions fabriquées des mêmes conceptions, testées avec de vrais lasers et détecteurs, ont atteint 89 % de précision pour MNIST et 90 % pour MedNIST — des chiffres remarquables compte tenu de la taille minuscule des puces. Les structures optiques intègrent environ 160 000 à 240 000 paramètres entraînables dans des surfaces plus petites qu’un grain de poussière, ce qui correspond à environ 400 millions de paramètres par millimètre carré.
Conçus pour la rapidité, l’efficacité et l’échelle
Étant donné que les dispositifs sont passifs — il n’y a pas de pièces mobiles ni d’éléments reprogrammables pendant l’inférence — ils ne nécessitent pas d’accord continu une fois fabriqués. Les « poids » du réseau neuronal sont câblés dans la géométrie de la nanostructure, de sorte que le calcul se fait à la vitesse de la lumière avec un traitement essentiellement en mémoire : la lumière entre avec les données encodées et ressort déjà mélangée en scores de classe. La méthode d’entraînement est également conçue pour être évolutive. Chaque étape d’optimisation nécessite seulement un nombre fixe de simulations physiques complètes déterminé par le nombre d’entrées et de sorties, et non par la taille du jeu de données, et ces simulations peuvent être réparties sur plusieurs unités de traitement graphique. Les auteurs expliquent en outre comment plusieurs de ces cœurs optiques pourraient être empilés avec des photodétecteurs entre eux, un peu comme des couches dans un réseau neuronal profond, et comment le multiplexage en longueur d’onde ou en temps pourrait augmenter le débit.
Ce que cela signifie pour le matériel d’IA futur
En termes simples, ce travail montre qu’il est possible de « faire pousser » des pièces sur mesure de verre et de silicium qui se comportent comme des couches spécialisées de réseaux neuronaux, le tout dans une surface suffisamment petite pour en loger des centaines ou des milliers sur une seule puce. Alors que les ordinateurs entièrement optiques sont encore à venir, ces accélérateurs nanophotoniques conçus par inversion pourraient décharger certaines des parties les plus énergivores des charges de travail d’IA des processeurs électroniques. Combinés à des modulateurs rapides, des détecteurs et une conception système ingénieuse, ils ouvrent la voie à des matériels compacts et peu énergivores où la lumière, plutôt que l’électricité seule, réalise une grande partie du travail lourd en apprentissage automatique.
Citation: Sved, J., Song, S., Li, L. et al. Inverse-designed nanophotonic neural network accelerators for ultra-compact optical computing. Nat Commun 17, 1059 (2026). https://doi.org/10.1038/s41467-026-68648-1
Mots-clés: réseaux neuronaux photoniques, nanophotonique, informatique optique, accélérateurs matériels, conception par inversion