Clear Sky Science · fr
Un modèle linguistique génomique atténue les artefacts de chimères dans le séquençage direct de l’ARN par nanopore
Pourquoi nettoyer les lectures d’ARN est important
Nos cellules lisent constamment les instructions génétiques inscrites dans l’ARN, et les nouvelles technologies de séquençage permettent désormais aux scientifiques d’observer ce processus avec un niveau de détail sans précédent. L’un des outils les plus puissants, le séquençage direct de l’ARN par nanopore, peut lire des molécules d’ARN entières en une seule fois — mais il introduit aussi des artefacts qui peuvent donner l’impression que des gènes sont brisés et recousus d’une manière qui n’existe pas dans la réalité. Cette étude présente DeepChopper, un outil logiciel qui fonctionne un peu comme un modèle linguistique pour les génomes, corrigeant ces erreurs pour que les chercheurs puissent avoir confiance dans les données d’ARN.
Quand le séquenceur invente de fausses fusions de gènes
Les machines nanopore modernes tirent des brins d’ARN individuels à travers de minuscules pores et lisent leur séquence directement. Cela présente de grands avantages par rapport aux méthodes plus anciennes, comme la conservation des modifications chimiques et la capture de transcrits de longueur complète en une seule lecture. Mais le procédé repose aussi sur de petits fragments auxiliaires appelés adaptateurs, collés aux molécules d’ARN lors de la préparation des bibliothèques. Parfois, deux ou plusieurs molécules d’ARN sont accidentellement reliées entre elles par ces adaptateurs, créant ce qui ressemble à des chimères — des molécules hybrides qui paraissent fusionner différents gènes. Les outils d’analyse standard peuvent interpréter à tort ces résidus techniques comme des événements biologiques réels, par exemple des fusions de gènes liées au cancer ou des schémas d’épissage inhabituels, ce qui conduit à des conclusions trompeuses.
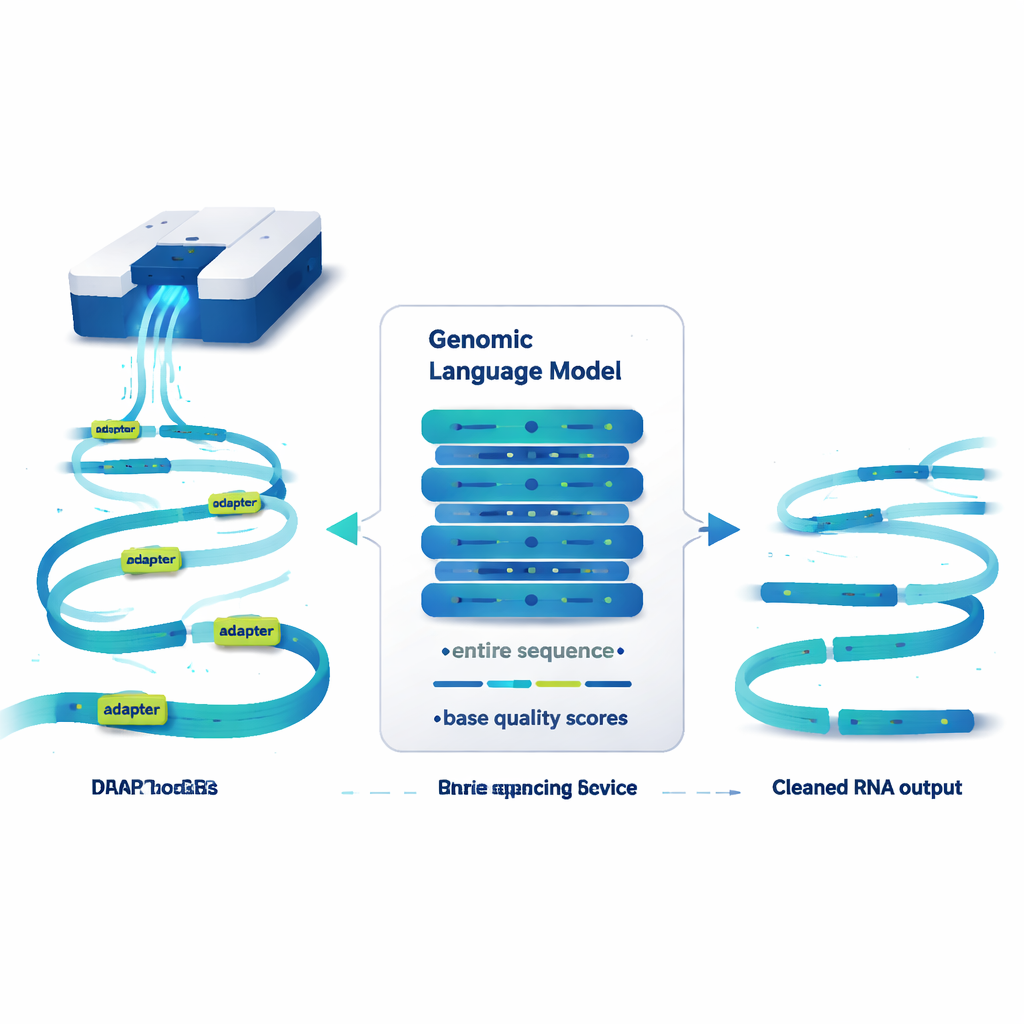
Un modèle linguistique qui lit les génomes, pas des phrases
DeepChopper traite les séquences génétiques un peu comme du texte et applique des idées issues des grands modèles linguistiques. Au lieu de mots, il lit les séquences d’ARN lettre par lettre, avec un score de qualité pour chaque lettre indiquant la fiabilité de la lecture. Construit sur une architecture compacte appelée HyenaDNA, il peut analyser jusqu’à 32 000 bases à la fois — suffisamment pour couvrir pratiquement n’importe quelle molécule d’ARN humaine. Pour chaque position, DeepChopper estime si la base fait partie d’une séquence d’ARN authentique ou d’un adaptateur. Une étape de raffinement lisse ensuite ces prédictions afin que les adaptateurs soient marqués comme des blocs continus plutôt que comme des points isolés.
Couper les mauvaises jonctions sans jeter les données
Une fois que DeepChopper a repéré des adaptateurs à l’intérieur d’une lecture, il fait quelque chose de crucial : au lieu de jeter la lecture entière, il « coupe » aux emplacements des adaptateurs et conserve les fragments réels. Ainsi, une fusion artificielle de deux ARN peut être redivisée en ses parties d’origine. Testé sur des millions de lectures nanopore provenant de plusieurs lignées cellulaires cancéreuses humaines et de cellules souches, DeepChopper a largement surpassé les outils existants d’élimination d’adaptateurs, qui n’avaient pas été conçus pour ce contexte de séquençage direct d’ARN. Il a reconnu correctement les adaptateurs avec plus de 99 % de précision et de rappel sur des jeux de données synthétiques, et il s’est montré scalable sur des jeux de plus de 20 millions de lectures en utilisant des processeurs graphiques.
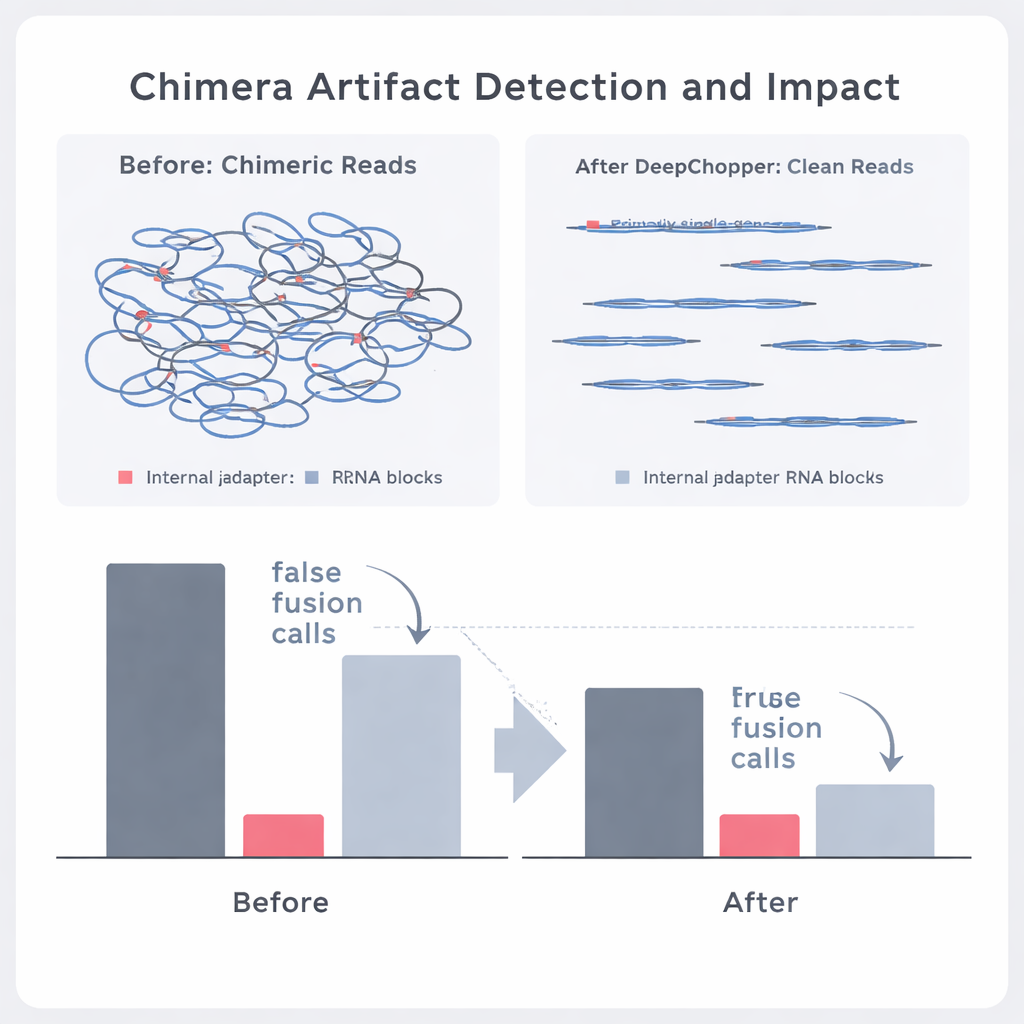
Séparer les vraies fusions de gènes des mirages de séquençage
Les auteurs ont ensuite testé si DeepChopper pouvait distinguer les événements biologiques genuins des artefacts dans des données réelles de cancer. En comparant les lectures d’ARN direct avec des jeux de données correspondants produits par des méthodes indépendantes (comme le séquençage cDNA direct sur les plateformes Oxford Nanopore et PacBio), ils ont pu annoter quelles chimères apparentes étaient soutenues par d’autres technologies et lesquelles ne l’étaient pas. DeepChopper a réduit les alignements chimériques non soutenus de 62 à 91 %, tout en enrichissant fortement la fraction confirmée par d’autres méthodes. Il a aussi réduit d’environ 90 % le nombre d’appels suspectés de fusions de gènes, en particulier ceux impliquant des gènes ribosomiques qui se sont avérés être des artefacts fréquents. Parallèlement, les véritables événements de fusion confirmés par le séquençage d’ARN à lectures courtes ont été préservés.
Une meilleure chimie aide — mais les artefacts persistent
Oxford Nanopore a récemment publié un kit de séquençage mis à jour (RNA004) conçu en partie pour réduire les artefacts techniques. DeepChopper a été appliqué « tel quel » aux données issues de cette nouvelle chimie et a quand même trouvé qu’une petite mais importante fraction de lectures contenait des adaptateurs internes et des jonctions chimériques. Même sans entraînement supplémentaire, le modèle a réduit les chimères artifactuales d’environ un cinquième ; après un ajustement fin sur ces nouvelles données, il a légèrement mieux performé, tout en préservant les signaux authentiques. Toutes chimies et types cellulaires confondus, la correction de ces artefacts a permis aux outils en aval de détecter beaucoup plus de transcrits complets et alternatifs, offrant une vision plus nette du paysage de l’ARN cellulaire.
Ce que cela signifie pour les futures études d’ARN
Pour les non-spécialistes, le message clé est que toute connexion d’ARN surprenante rapportée par un séquenceur n’est pas nécessairement de la biologie réelle — certaines proviennent d’erreurs techniques introduites par la technologie elle-même. DeepChopper agit comme un correcteur hautement entraîné pour les données d’ARN nanopore, repérant les séquences d’adaptateurs caractéristiques qui relient des molécules non apparentées et les coupant avec une précision au nucléotide. Le résultat est des cartes plus propres et plus fiables des molécules d’ARN présentes dans une cellule et de leur organisation. À mesure que les laboratoires s’appuieront de plus en plus sur le séquençage d’ARN à longues lectures pour étudier le cancer, les maladies du cerveau et d’autres pathologies complexes, des outils comme DeepChopper seront essentiels pour transformer des lectures brutes bruyantes en connaissances biologiques fiables.
Citation: Li, Y., Wang, TY., Guo, Q. et al. Genomic language model mitigates chimera artifacts in nanopore direct RNA sequencing. Nat Commun 17, 1864 (2026). https://doi.org/10.1038/s41467-026-68571-5
Mots-clés: séquençage d’ARN par nanopore, lectures chimériques, artefacts de fusion de gènes, modèle linguistique génomique, DeepChopper