Clear Sky Science · fr
Un basecaller à double contexte pour le séquençage direct d’ARN par nanopore
Pourquoi décoder les lettres de l’ARN est important
Chaque cellule de votre corps lit et réécrit en permanence des messages écrits en ARN, la copie active de nos gènes. Les nouvelles machines « nanopore » peuvent lire directement des molécules d’ARN individuelles, ouvrant la voie pour comprendre comment les gènes sont activés, comment les ARN sont épissés, et comment les marques chimiques sur l’ARN influencent la santé et la maladie. Mais il y a un hic : ces appareils mesurent en réalité de minuscules courants électriques, qui doivent ensuite être traduits — « basecallés » — en lettres familières A, C, G et U. Si cette traduction est erronée, l’histoire biologique qu’on en déduit peut être fortement déformée. Cet article présente Coral, un nouveau système d’intelligence artificielle qui rend cette traduction beaucoup plus précise.
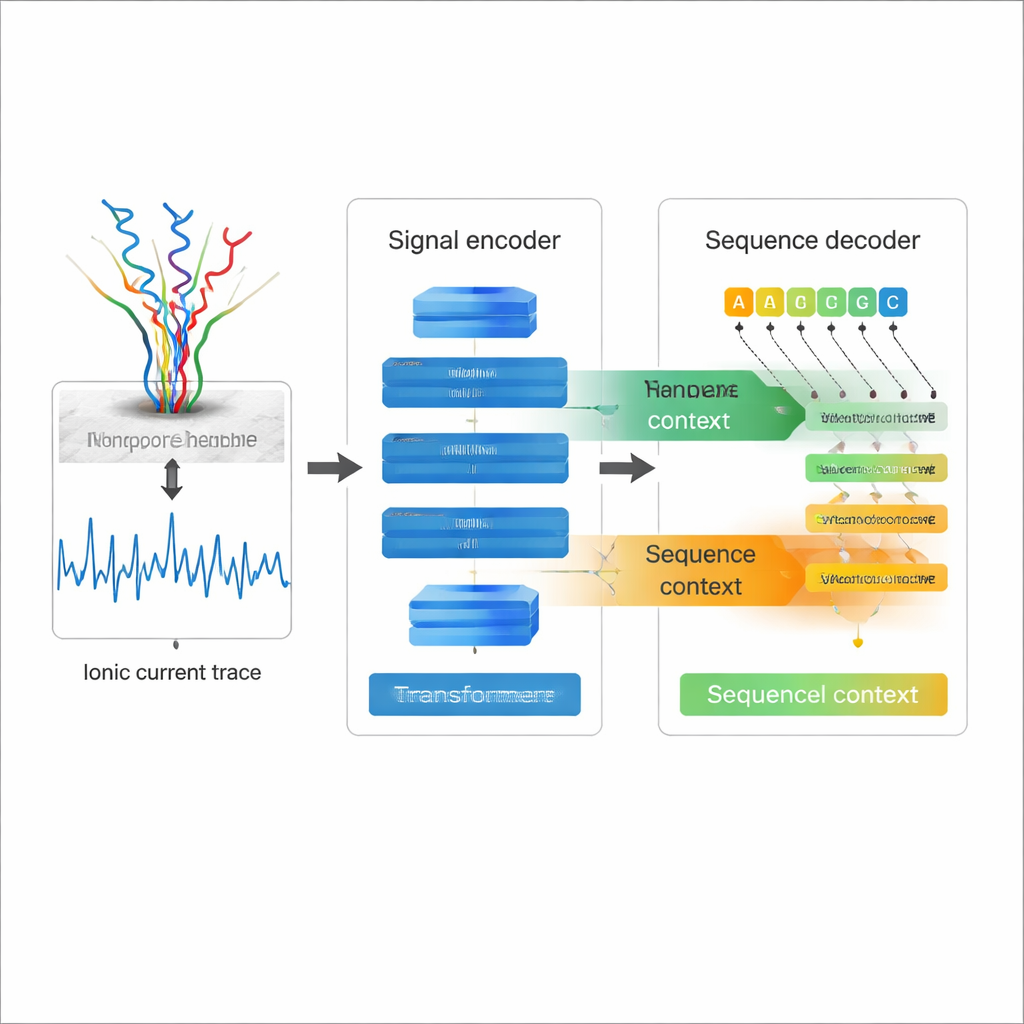
Lire l’électricité au lieu des lettres
Le séquençage direct d’ARN par nanopore fonctionne en faisant passer un brin d’ARN à travers un trou moléculaire — un nanopore — tout en mesurant comment le courant électrique change à mesure que chaque nucléotide passe. Ces traces de courant ondulantes contiennent l’information sur la séquence d’ARN et ses modifications chimiques. Le séquençage ARN traditionnel convertit l’ARN en ADN puis l’amplifie, des étapes qui peuvent introduire des biais et effacer de nombreuses marques chimiques naturelles. Le séquençage direct d’ARN évite ces problèmes, mais son prix a été jusqu’ici un taux d’erreur relativement élevé lors de la conversion des traces de courant en séquences, en particulier pour des motifs difficiles comme des répétitions de bases et des structures ARN complexes. Un meilleur basecalling est essentiel si les chercheurs veulent faire confiance aux détails fins de ces longues lectures d’ARN.
Un traducteur plus intelligent qui utilise deux types de contexte
La plupart des basecallers nanopore existants considèrent le signal électrique comme la source principale d’information et décodent chaque position presque indépendamment, ce qui limite leur capacité à exploiter la structure même de la séquence d’ARN. Coral adopte une approche différente. Il utilise une architecture encodeur–décodeur basée sur un Transformer, dans l’esprit des modèles de langage modernes. D’abord, un réseau encodeur composé de convolutions et de couches d’auto-attention digère le signal de courant brut en une description compacte de l’évolution du signal dans le temps. Ensuite, un décodeur prédit chaque nouvelle base d’ARN une étape après l’autre, regardant simultanément en arrière les bases déjà écrites et latéralement le signal encodé. Deux types d’attention — au sein de la séquence ARN croissante et entre la séquence et le signal — permettent à Coral de pondérer à la fois le contexte électrique et le contexte de séquence pour décider quelle lettre vient ensuite.
Des séquences plus précises et moins de molécules manquées
Les auteurs ont comparé Coral à plusieurs basecallers de référence, y compris les outils commerciaux d’Oxford Nanopore, sur de l’ARN humain et d’autres organismes et sur plusieurs chimies nanopore. Sur six espèces et avec des kits de séquençage ARN plus anciens, Coral a atteint une précision médiane de lecture typique autour de 97 %, nettement supérieure aux méthodes concurrentes. Avec le dernier kit ARN, sa précision a dépassé 99 %. Coral a produit moins de mésappariements, d’insertions et de délétions, et a fourni des lectures plus longues, mieux alignées et avec moins de séquences impossibles à cartographier. Il a été particulièrement performant pour gérer de courtes séries de bases répétées — très fréquentes dans les données réelles — qui constituent une source d’erreurs courante pour d’autres outils. En capturant de manière plus fiable de plus longues portions de séquence correcte, Coral a également excellé à prédire de courts motifs de séquence (k‑mers) et est resté robuste même lorsque des étapes de décodage antérieures contenaient de petites erreurs.
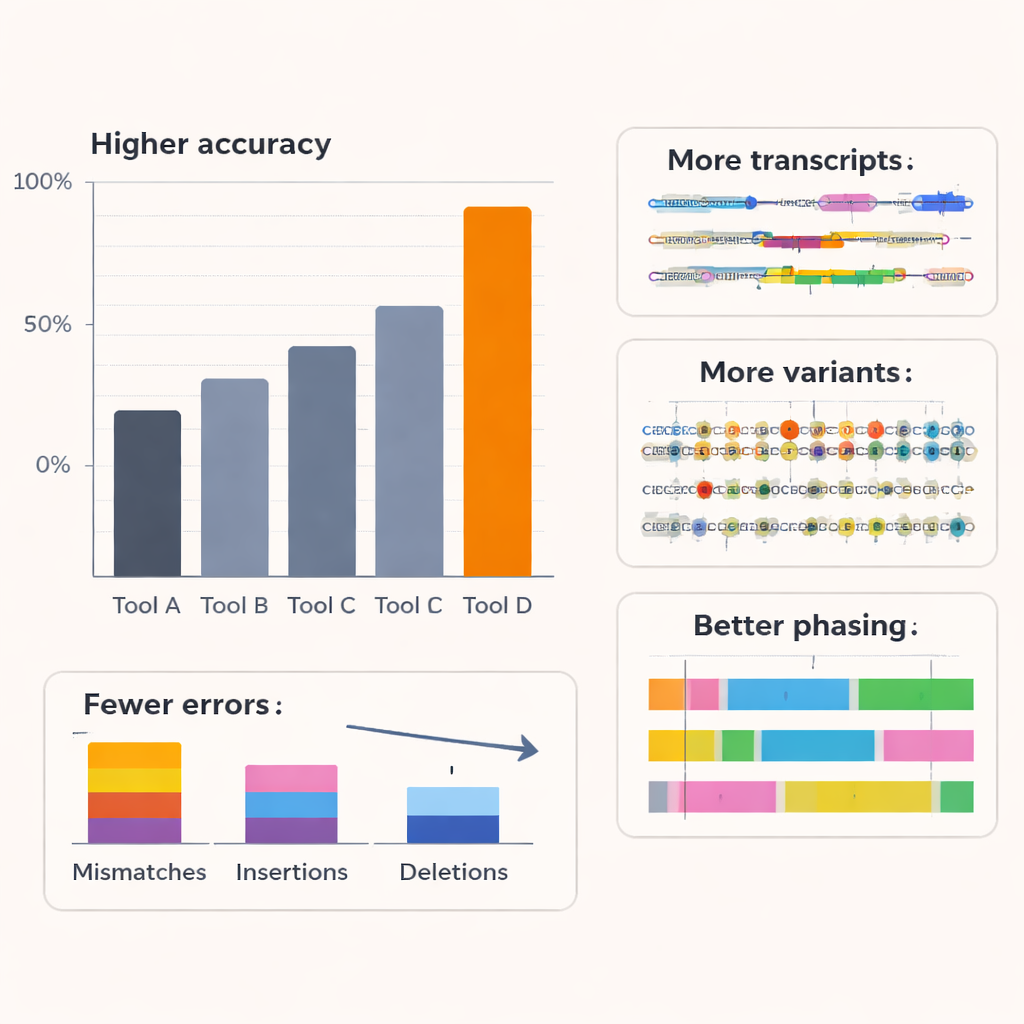
Voir davantage de détails cachés du transcriptome
Un meilleur basecalling n’est utile que s’il conduit à une meilleure biologie. Pour tester cela, l’équipe a examiné comment les sorties de Coral affectaient les analyses en aval dans des lignées cellulaires humaines. En utilisant un outil spécialisé pour reconstruire des isoformes d’ARN complètes — les différentes versions épissées de chaque gène — ils ont constaté que les lectures de Coral révélaient davantage de structures de transcrits connues et de nombreuses isoformes supplémentaires à faible abondance que d’autres basecallers avaient manquées. De nombreux transcrits spécifiques à Coral étaient corroborés par des données indépendantes de lectures courtes, indiquant qu’ils sont réels plutôt que des artefacts. Coral a aussi détecté plus de transcrits de référence artificiels à concentrations connues dans une expérience de spike‑in et en a estimé l’abondance avec plus de précision. Au‑delà de la découverte de transcrits, Coral a amélioré la détection d’événements de fusion de gènes dans une lignée de cancer du sein et augmenté le nombre et la fiabilité des gènes montrant une expression allèle‑spécifique, où une copie parentale d’un gène est plus active que l’autre.
Variants génétiques et lignées familiales plus clairs
Parce que les longues lectures d’ARN peuvent couvrir des variants génétiques éloignés, elles sont des outils puissants pour déterminer quels variants voyagent ensemble sur la même copie chromosomique — un processus appelé phasage d’haplotype. En utilisant un échantillon humain bien étudié avec une carte de variants de référence, les auteurs ont montré que les lectures de meilleure qualité de Coral conduisaient à une détection plus précise des variations mononucléotidiques et à bien moins d’erreurs de phasage : les erreurs de switch et les taux d’incohérence globaux au sein des blocs phasés ont diminué d’environ trois quarts par rapport aux autres méthodes, tandis qu’un nombre nettement plus élevé de variants a pu être phasé. Des études de simulation faisant varier la précision de lecture sous‑jacente ont confirmé que, une fois le basecalling proche d’environ 95 % de précision, les performances en découverte d’isoformes, expression allèle‑spécifique et phasage s’améliorent nettement puis se stabilisent. Coral se situe dans cette zone à fort bénéfice, ce qui suggère qu’il capture la majeure partie de l’information biologiquement pertinente présente dans les signaux nanopore bruyants.
Ce que cela signifie pour la recherche ARN future
Pour les non‑spécialistes, le message clé est que Coral agit comme un traducteur bien plus fiable entre le langage électrique des séquenceurs nanopore et le langage génétique de l’ARN. En exploitant mieux le contexte à la fois dans le signal et dans la séquence croissante, il produit des lectures plus propres qui révèlent davantage de variantes de transcrits, repèrent des gènes de fusion rares et suivent avec plus de confiance l’origine parentale des variants. Le logiciel est open‑source, de sorte que les chercheurs peuvent l’adapter à de nouveaux organismes, chimies, ou même pour étudier les marques chimiques sur l’ARN lui‑même. À mesure que la technologie nanopore continue de s’améliorer, des outils comme Coral aideront à transformer les traces de courant brutes en cartes détaillées et fiables du monde de l’ARN à l’intérieur des cellules.
Citation: Xie, S., Ding, L., Yu, Y. et al. A dual context-aware basecaller for nanopore direct RNA sequencing. Nat Commun 17, 1851 (2026). https://doi.org/10.1038/s41467-026-68566-2
Mots-clés: séquençage ARN par nanopore, basecalling, modèle Transformer, isoformes de l’ARNm, phasage d’haplotype