Clear Sky Science · fr
Trois questions ouvertes sur la transférabilité des scores polygéniques
Pourquoi prédire la santé à partir de l’ADN est plus difficile qu’il n’y paraît
Médecins et chercheurs espèrent de plus en plus utiliser des « scores polygéniques » basés sur l’ADN pour estimer le risque d’une personne de développer des affections courantes comme le diabète, les maladies cardiaques ou l’asthme. Mais ces scores fonctionnent souvent bien uniquement chez des personnes qui ressemblent aux volontaires des études d’origine, généralement d’ascendance européenne. Cet article s’interroge sur les raisons pour lesquelles ces prédictions ne « voyagent » pas de façon fiable vers des populations ayant des origines génétiques ou des conditions de vie différentes, et sur ce que cela implique pour une utilisation équitable des scores de risque génétique en médecine.
Ce que promettent les scores polygéniques — et où ils échouent
Les scores polygéniques agrègent les effets minuscules de nombreux variants génétiques répartis dans le génome en un seul nombre destiné à prédire un trait, comme la taille ou la tension artérielle. Ils sont construits à partir d’imposantes études d’association pangénomique (GWAS) reliant des marqueurs d’ADN à des traits chez des centaines de milliers de volontaires. Cependant, lorsqu’on applique ces scores à de nouveaux groupes de personnes, leur précision varie de manière spectaculaire. En général, la qualité de la prédiction décline plus le nouveau groupe diffère génétiquement ou socialement des participants de la GWAS initiale. C’est ce qu’on appelle le problème de transférabilité : un score efficace dans un contexte peut induire en erreur dans un autre, et risquer d’accroître les inégalités en santé s’il est utilisé sans précaution.
Au-delà de l’ascendance : la distance sur la carte génétique
Pour examiner ce problème, les auteurs ont utilisé les données de l’UK Biobank, qui comprennent des informations génétiques et de santé de plus de 400 000 personnes. Ils ont construit des scores polygéniques pour 15 traits fortement héritables, comme la taille, le poids, les numérations cellulaires sanguines et les taux de cholestérol, à partir d’un large groupe principalement composé de Britanniques blancs. Ensuite, ils ont testé la capacité de ces scores à prédire les traits chez 69 500 autres participants présentant une grande diversité d’origines génétiques. Plutôt que de classer les personnes en larges catégories d’ascendance, l’équipe a placé chaque individu le long d’une échelle continue de « distance génétique » : à quelle distance le profil d’ADN de chaque personne se situe par rapport à la moyenne des volontaires de la GWAS, lorsqu’on le projette sur une carte génétique basée sur des composantes principales.
La puissance prédictive faiblit — mais pas de façon simple ni équitable
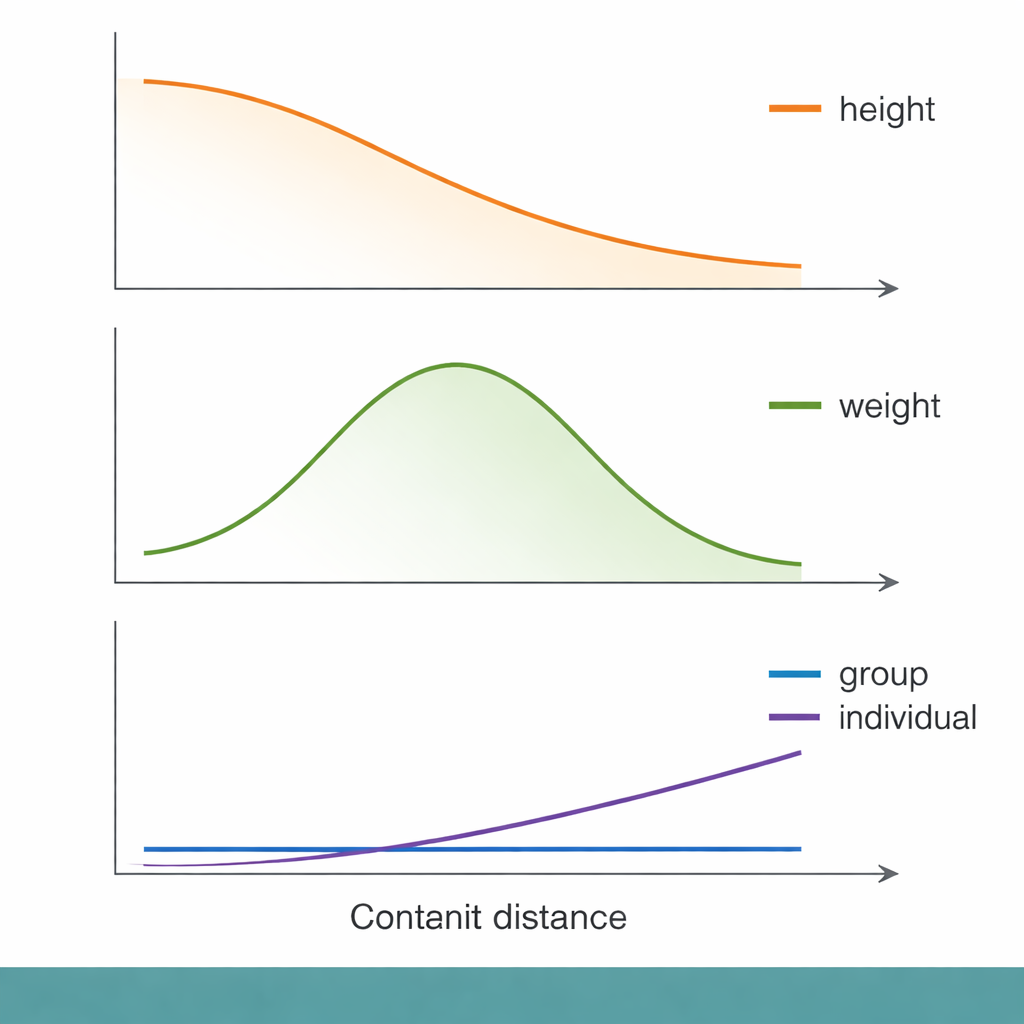
Sur cette échelle de distance génétique, certains schémas familiers sont apparus. Pour la taille, par exemple, la précision de la prédiction au niveau des groupes diminuait de façon régulière à mesure que les personnes s’éloignaient génétiquement du groupe de la GWAS. Pour autant, quand les chercheurs ont analysé au niveau individuel, la distance génétique n’expliquait qu’une infime fraction de la variabilité de la qualité des prédictions. Des mesures socioéconomiques, comme l’indice de privation de Townsend (un indicateur de désavantage matériel au niveau du quartier), expliquaient la qualité des prédictions à un niveau comparable — voire légèrement supérieur. Autrement dit, les personnes de statut socioéconomique plus bas recevaient des prédictions génétiques moins précises, même au sein de la même tranche de distance génétique, ce qui souligne que le contexte social peut compter autant que l’ADN pour l’utilité d’un score.
Différents traits, histoires différentes, réponses différentes
Tous les traits ne se comportent pas de la même façon. Pour le poids corporel et la masse grasse, la précision de la prédiction culminait en réalité à des distances génétiques intermédiaires avant de décliner, rompant le modèle simple « plus loin = pire ». Les traits liés au système immunitaire, comme les numérations de globules blancs et de lymphocytes, ont montré des comportements particulièrement déroutants. Pour certains de ces traits, la précision de la prédiction au niveau des groupes tombait presque à zéro même pour des personnes qui n’étaient pas très éloignées génétiquement de l’échantillon GWAS. Les auteurs suggèrent que les traits immunitaires peuvent être façonnés par des pressions évolutives qui évoluent rapidement — par exemple des infections passées — et modifient quels variants d’ADN sont importants selon les populations. Dans ces cas, l’architecture génétique elle‑même peut avoir suffisamment changé pour qu’un score établi sur un groupe devienne presque inutile ailleurs.
La manière dont on mesure la performance peut inverser l’interprétation
Le tableau devient encore plus complexe si l’on change la façon de mesurer la « bonne » prédiction. Une grande partie des travaux antérieurs s’est appuyée sur une statistique unique appelée R², qui capture la part de variation d’un trait expliquée par un score au sein d’un groupe. Les auteurs montrent que d’autres métriques peuvent raconter une autre histoire, en particulier pour les maladies. Pour l’asthme, la précision (parmi les cas prédits, combien sont des cas réels) et le rappel (quelle part des cas réels sont détectés) déclinaient toutes deux avec la distance génétique de manière similaire. Mais pour le diabète de type 2, la précision restait assez constante tandis que le rappel augmentait effectivement avec la distance — ce qui signifie que le score identifiait une plus grande part des cas réels dans des groupes plus éloignés, même s’il avait été construit dans un groupe plus proche. Selon qu’une clinique privilégie de repérer tous les patients à haut risque ou d’éviter les faux positifs, on peut tirer des conclusions opposées sur la transférabilité du score.
Ce que cela implique pour l’usage des scores ADN dans la vie réelle
Globalement, l’étude soutient que l’on ne peut pas juger de l’utilité des scores polygéniques en se fondant uniquement sur de larges étiquettes d’ascendance ou un seul chiffre de précision. La qualité de la prédiction individuelle dépend d’un mélange de facteurs : des schémas subtils de similarité génétique, l’histoire évolutive de chaque trait, les environnements et conditions sociales des personnes, et la manière particulière dont le score et sa métrique de performance sont choisis. Pour que les scores polygéniques soient appliqués de manière juste et efficace en médecine, les chercheurs devront développer de meilleures méthodes pour capturer la structure génétique fine, modéliser les influences sociales et environnementales, et adapter les métriques d’évaluation aux décisions du monde réel. D’ici là, les scores de risque génétique doivent être utilisés avec prudence, en gardant à l’esprit les personnes — et les contextes — pour lesquels ils fonctionnent mal autant que ceux pour lesquels ils sont utiles.
Citation: Wang, J.Y., Lin, N., Zietz, M. et al. Three open questions in polygenic score portability. Nat Commun 17, 942 (2026). https://doi.org/10.1038/s41467-026-68565-3
Mots-clés: scores polygéniques, prédiction génétique, inégalités en santé, ascendance génétique, médecine de précision