Clear Sky Science · fr
Matrices de contact synthétiques pilotées par la mobilité : une solution évolutive pour la modélisation de réponse pandémique en temps réel
Pourquoi les déplacements quotidiens comptent en période de pandémie
Lorsqu’un nouveau virus respiratoire commence à se propager, l’un des plus grands inconnus est la fréquence des contacts rapprochés entre personnes de différents âges. Ces rencontres quotidiennes à l’école, au travail, à la maison ou dans les transports déterminent la vitesse de diffusion de la maladie dans une population. Pourtant, mesurer ces comportements en temps réel, alors que les comportements changent en réponse aux règles et à la peur, est extrêmement difficile. Cette étude pose une question simple mais cruciale : peut‑on utiliser des données de mobilité et de comportement collectées régulièrement, au lieu de grandes enquêtes récurrentes, pour suivre ces contacts changeants assez rapidement afin d’éclairer les décisions en période de pandémie ?
Transformer les données de mobilité en rencontres sociales
Les chercheurs se sont concentrés sur la France durant les deux premières années de la pandémie de COVID‑19, une période marquée par des confinements, des fermetures d’écoles, des couvre‑feux et l’arrivée de nouveaux variants et vaccins. Leur outil central est une « matrice de contact » — un tableau qui enregistre combien de contacts quotidiens les personnes d’un groupe d’âge ont avec celles d’un autre groupe. Avant la pandémie, ces matrices étaient construites à partir de questionnaires détaillés où des volontaires listaient leurs contacts. Pendant la pandémie, l’équipe a plutôt généré des matrices « synthétiques » hebdomadaires en partant des schémas prépandémiques puis en réduisant ou augmentant certains types de contacts selon des indicateurs en temps réel : mobilité au travail fournie par Google, fréquentation scolaire et calendriers de vacances, et enquêtes sur la fréquence à laquelle les gens disaient éviter les contacts physiques.
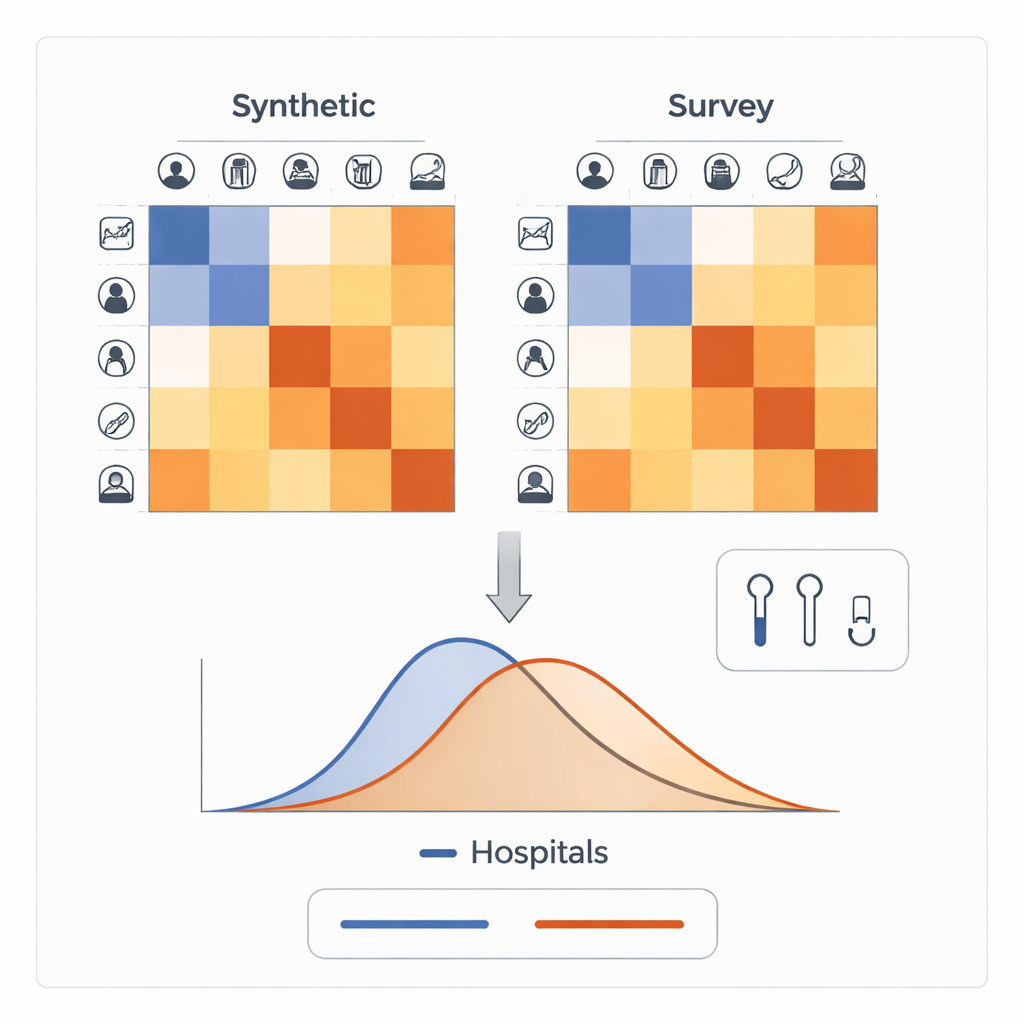
Comparer les contacts synthétiques aux enquêtes du monde réel
Pour vérifier si ces matrices synthétiques étaient fiables, les auteurs les ont comparées à sept vagues de l’enquête SocialCov en France, qui interrogeait directement les personnes sur leurs contacts à différents moments de la pandémie. Globalement, les deux approches montraient des tendances larges similaires : pendant le premier confinement, les contacts ont chuté à environ un quart des niveaux prépandémiques, puis ont lentement augmenté à mesure que les restrictions se relâchaient, sans revenir complètement à la normale à la mi‑2022. Mais des différences clés sont apparues. Les matrices basées sur les enquêtes rapportaient presque deux fois plus de contacts que les matrices synthétiques après le premier confinement, un écart largement porté par les enfants et les adolescents. Pendant les périodes où les écoles étaient ouvertes, les enquêtes suggéraient que les moins de 19 ans avaient trois à quatre fois plus de contacts que dans les estimations synthétiques, alors que les chiffres pour les adultes et les personnes âgées concordaient beaucoup mieux entre les deux méthodes.
Intégrer les deux approches dans un modèle de maladie
Le véritable test n’était pas seulement de compter les contacts, mais de voir quelle source de données reproduisait le mieux le déroulement réel de l’épidémie. L’équipe a alimenté le même modèle de transmission du COVID‑19 pour la France avec trois hypothèses de contact différentes : des matrices synthétiques hebdomadaires, les matrices plus rares basées sur les enquêtes (interpolées dans le temps entre les vagues d’enquête), et une matrice unique fixe prépandémique. Ils ont ensuite ajusté un « facteur correcteur » global au fil des phases successives de la pandémie pour capter des influences non directement présentes dans les matrices, comme le port du masque ou la saisonnalité. Les trois modèles ont pu suivre la courbe globale des admissions à l’hôpital, mais le modèle utilisant les matrices synthétiques présentait les plus faibles erreurs et le meilleur ajustement statistique, en particulier durant les périodes de transition comme les fermetures partielles d’école ou la levée progressive des couvre‑feux.
Ce que révèlent les modèles sur les risques par âge
En regardant de plus près les différents groupes d’âge, les matrices synthétiques ont donné l’image la plus réaliste pour les adolescents, les adultes et les personnes âgées. Avec ces entrées, les hospitalisations prévues par le modèle et les estimations sérologiques des infections passées correspondaient étroitement aux données observées pour ces tranches d’âge. Les matrices issues des enquêtes, en revanche, avaient tendance à surestimer les infections chez les enfants et les adolescents, probablement parce qu’elles comptabilisaient davantage de contacts moins pertinents pour la transmission — par exemple des rencontres brèves ou masquées à l’école. Les matrices synthétiques sous‑estimaient les infections chez les jeunes enfants, montrant que les deux méthodes peinent encore à saisir les contacts enfantins les plus significatifs. Fait important, les auteurs ont constaté qu’aucun remaniement global ne pouvait corriger une structure de contact mal ajustée : qui fréquente qui importait davantage que le simple nombre total de contacts.
Implications pour la réponse aux pandémies futures
Pour le grand public, le message principal est qu’il est possible de suivre les variations des schémas de contact assez rapidement pour des décisions en temps réel sans mener en permanence de vastes enquêtes chronophages. En combinant soigneusement des données de mobilité, des indicateurs de comportement simples et la connaissance des lieux où les contacts ont lieu (domicile, école, travail, loisirs), les équipes de santé publique peuvent construire des matrices de contact synthétiques hebdomadaires flexibles, évolutives et peu coûteuses. Dans cette étude, ces matrices ont surpassé à la fois les matrices d’enquête traditionnelles et les schémas prépandémiques statiques pour expliquer qui était hospitalisé et quand. Les auteurs concluent qu’investir dans des données de mobilité et de comportement stratifiées par âge — et dans des systèmes capables de transformer rapidement ces chiffres en matrices de contact — sera un atout puissant pour des réponses plus agiles et efficaces aux épidémies futures.
Citation: Di Domenico, L., Bosetti, P., Sabbatini, C.E. et al. Mobility-driven synthetic contact matrices as a scalable solution for real-time pandemic response modeling. Nat Commun 17, 1845 (2026). https://doi.org/10.1038/s41467-026-68557-3
Mots-clés: modélisation pandémique, contacts sociaux, données de mobilité, COVID-19 France, transmission structurée par âge