Clear Sky Science · fr
Réseaux neuronaux physiques entraînés avec une optimisation sensible à l’acuité
Pourquoi cela compte pour l’avenir du matériel IA
Alors que l’intelligence artificielle devient plus puissante, ce ne sont de plus en plus pas les algorithmes astucieux qui la limitent, mais les puces qui les exécutent. Une voie prometteuse consiste à construire les réseaux neuronaux directement dans du matériel physique en utilisant la lumière, l’électronique analogique ou d’autres systèmes à base d’ondes. Cet article présente une nouvelle façon d’entraîner ces « réseaux neuronaux physiques » afin qu’ils restent précis même lorsque le monde réel est imparfait — lorsque les dispositifs sont légèrement mal fabriqués, que la chaleur provoque des dérives ou que des composants se désalignent.
Des cerveaux numériques aux machines physiques
L’IA moderne s’exécute généralement sur du matériel numérique comme des processeurs graphiques, où l’entraînement repose sur l’algorithme de rétropropagation pour régler des millions de poids numériques. Les réseaux neuronaux physiques cherchent à déporter ce calcul dans des matériaux et des dispositifs réels — tels que des puces photoniques, des maillages d’interféromètres ou des dispositifs optiques diffractifs — dont le comportement imite naturellement les mathématiques des réseaux neuronaux. Parce que ces systèmes traitent l’information là où elle est stockée, ils peuvent être beaucoup plus rapides et économes en énergie que les puces conventionnelles. Mais les entraîner est difficile : soit on entraîne un modèle numérique en espérant qu’il corresponde au matériel, soit on entraîne directement sur le dispositif. Ces deux approches posent problème lorsque les dispositifs réels diffèrent des modèles idéaux ou dérivent avec le temps.
Deux façons imparfaites d’enseigner aux réseaux physiques
La première approche, dite entraînement in silico, apprend tous les paramètres sur un modèle informatique puis les copie dans le matériel. Cela ne fonctionne bien que si le modèle mathématique correspond presque exactement au dispositif fabriqué, ce qui est rarement le cas une fois les variations de fabrication, le bruit électrique et les effets thermiques pris en compte. La seconde approche, l’entraînement in situ, intègre le dispositif physique directement dans le processus d’apprentissage en mesurant les sorties à chaque ajustement des paramètres. Si cela évite les erreurs de modélisation, cela crée d’autres problèmes : obtenir les informations de gradient est difficile et coûteux, l’entraînement devient spécifique à l’appareil et les paramètres obtenus ne peuvent généralement pas être transférés sur une autre puce nominalement identique. Dans les deux cas, de petits changements après le déploiement — comme un léger changement de température ou un désalignement — peuvent réduire drastiquement la précision et imposer des réentraînements coûteux.
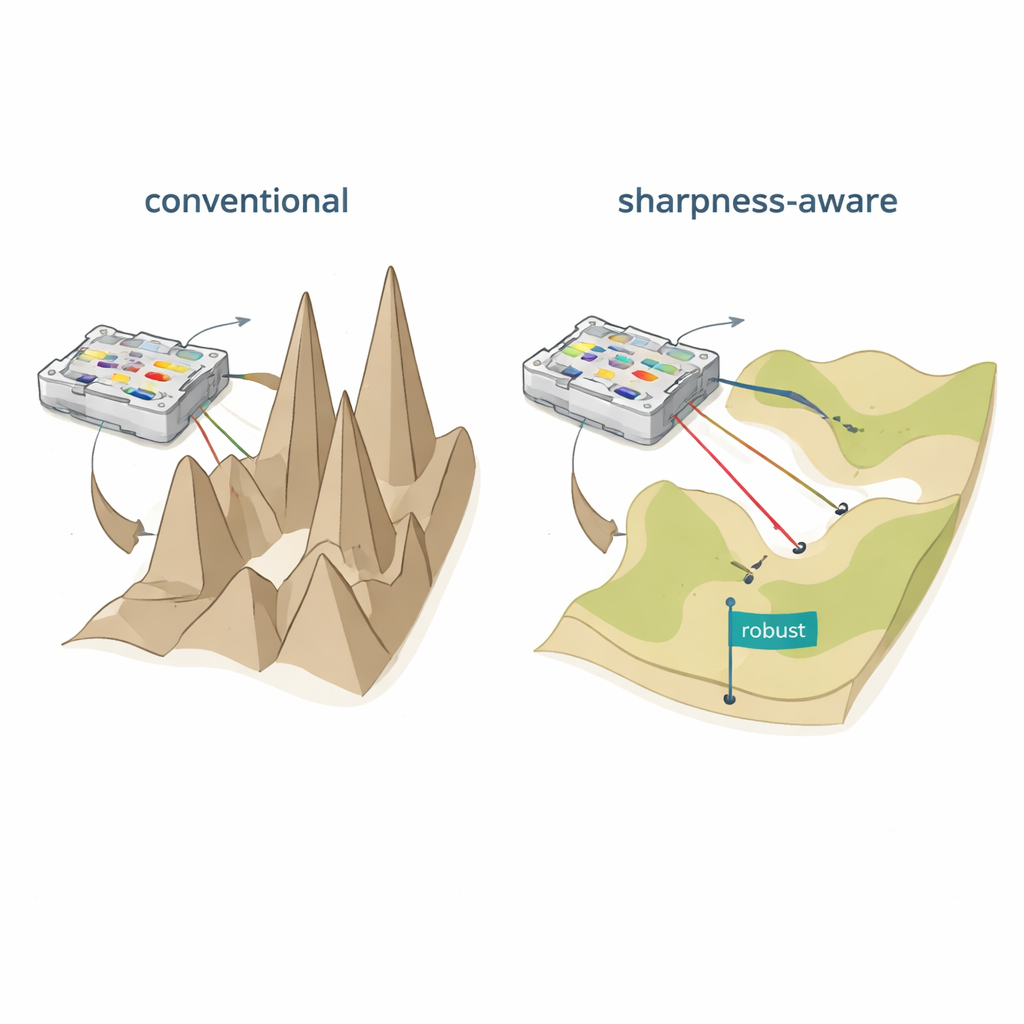
Aplatir le paysage d’apprentissage
Les auteurs proposent l’entraînement sensible à l’acuité (SAT), inspiré d’une idée de l’apprentissage automatique appelée minimisation sensible à l’acuité. Plutôt que de ne rechercher que des réglages donnant une faible erreur sur les données d’entraînement, SAT vise aussi des régions où l’erreur évolue lentement lorsque les paramètres physiques sous-jacents sont légèrement perturbés. En termes géométriques, l’entraînement traditionnel trouve souvent une vallée profonde mais étroite dans le « paysage de perte », où de minuscules variations de courants, de phases ou de positions font s’effondrer les performances. SAT recherche délibérément des vallées larges et plates où les performances restent élevées malgré de telles perturbations. Mathématiquement, il ajoute un terme à l’objectif d’entraînement qui pénalise les régions vives et fortement courbées de l’espace des paramètres, et il approxime cette pénalité de façon efficace en utilisant deux étapes de gradient soigneusement choisies plutôt que des calculs coûteux de dérivées secondes.
Démontrer la robustesse sur différentes plateformes optiques
Pour montrer que SAT n’est pas lié à un seul dispositif, les auteurs l’appliquent à trois plateformes optiques distinctes. Sur des banques de poids à résonateurs microrings — de minuscules boucles de silicium qui orientent la lumière à différentes longueurs d’onde — ils montrent que les systèmes entraînés avec SAT conservent une grande précision de classification même lorsque la température dérive de plusieurs degrés Celsius, alors que l’entraînement standard et les méthodes d’injection de bruit échouent spectaculairement. Ils étendent cela à des tâches plus exigeantes comme la classification d’images sur CIFAR-10, la compression et la reconstruction d’images, et la génération d’images, où SAT maintient des performances stables alors que les méthodes conventionnelles se dégradent sous des variations thermiques modestes. Dans des simulations de maillages d’interféromètres de Mach–Zehnder, les modèles entraînés avec SAT tolèrent beaucoup mieux des erreurs de fabrication réalistes et, point crucial, les paramètres entraînés sur un dispositif peuvent être transférés à d’autres puces présentant des imperfections différentes sans perte de précision. Enfin, dans une configuration optique diffractive en espace libre utilisant un écran OLED, des lentilles et un modulateur spatial de lumière, SAT améliore la tolérance aux désalignements physiques comme la rotation, les décalages de pixels et la mise à l’échelle, bien que la relation exacte entre ces désalignements et les paramètres du réseau ne soit pas modélisée explicitement.
Une voie pratique vers une IA physique fiable
En termes simples, ce travail montre comment entraîner des réseaux neuronaux matériels de façon à « pardonner » les singularités inévitables des dispositifs réels. En orientant l’apprentissage vers des régions plates et stables du paysage d’erreur, l’entraînement sensible à l’acuité rend les réseaux neuronaux physiques à la fois plus précis et plus robustes aux variations de fabrication, aux changements de température et aux désalignements mécaniques. Parce qu’il peut être utilisé avec ou sans modèles physiques détaillés et qu’il fonctionne sur plusieurs types de matériel optique, SAT offre une recette pratique pour passer des démonstrations en laboratoire à des systèmes d’IA physiques rapides et économes en énergie utilisables dans le monde réel.
Citation: Xu, T., Luo, Z., Liu, S. et al. Physical neural networks using sharpness-aware training. Nat Commun 17, 1766 (2026). https://doi.org/10.1038/s41467-026-68470-9
Mots-clés: réseaux neuronaux physiques, informatique photonique, entraînement robuste, optimisation sensible à l’acuité, matériel neuromorphique