Clear Sky Science · fr
Cartographie complète des dynamiques et des interactions des modifications de l’ARN via l’apprentissage profond et le séquençage direct d’ARN par nanopore
Les signes de ponctuation cachés de l’ARN
Les molécules d’ARN de nos cellules ne sont pas de simples chaînes de A, C, G et U. Elles sont ornées de dizaines de petites marques chimiques qui agissent comme des signes de ponctuation, aidant à contrôler quels gènes sont activés, comment les protéines sont produites et comment les cellules réagissent au stress et aux maladies. Pourtant, jusqu’à présent, les chercheurs ont surtout pu étudier ces marques une par une, ce qui rend difficile la compréhension de leur fonctionnement conjoint à l’échelle du génome. Cet article présente ORCA, un système d’apprentissage profond qui lit les molécules d’ARN natives directement et construit une carte globale et multi‑couches de ces marques chimiques et de leurs interactions.
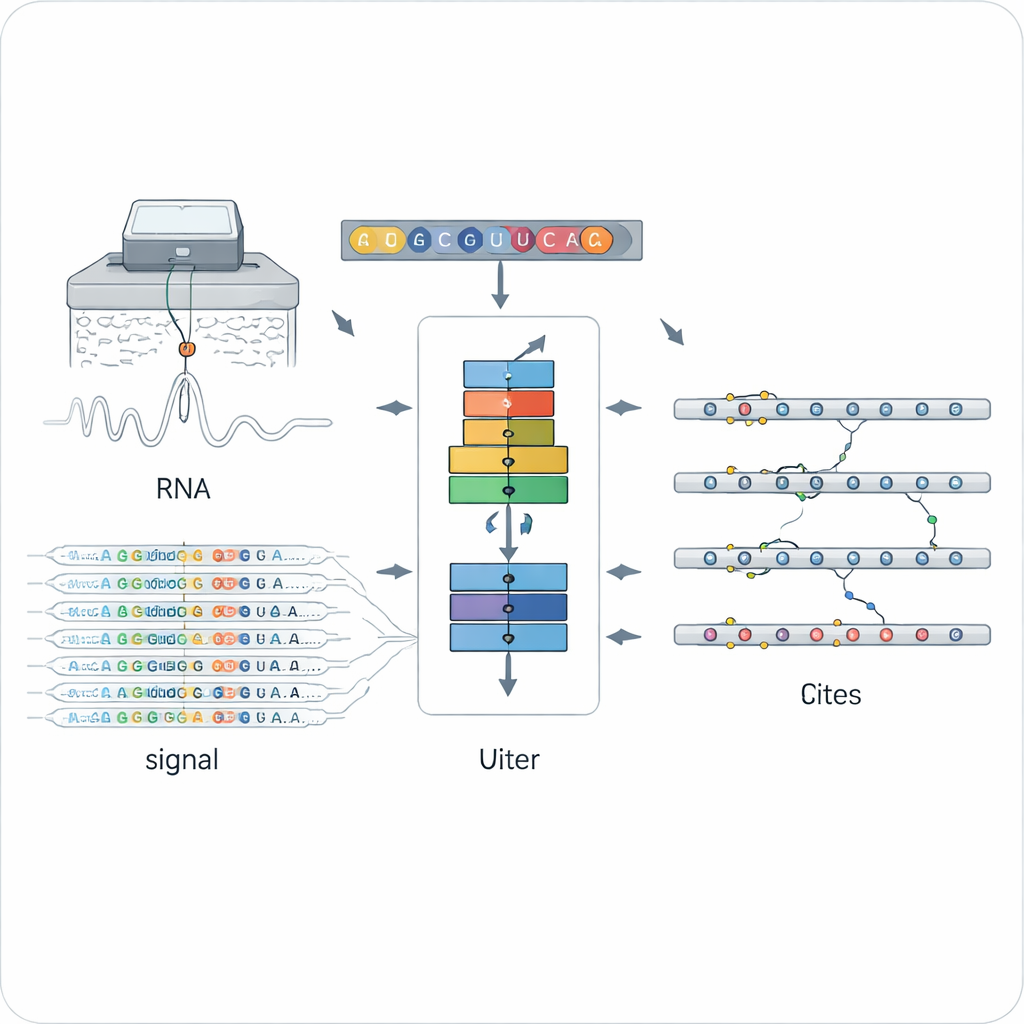
Une nouvelle façon de lire les marques chimiques sur l’ARN
Les méthodes traditionnelles pour détecter les modifications de l’ARN reposent généralement sur des anticorps spécifiques ou des traitements chimiques adaptés à un seul type de marque, comme le populaire N6‑méthyladénosine (m6A). Cela les rend puissantes mais limitées : chaque méthode ne détecte qu’un type de marque, souvent dans un protocole expérimental particulier. Le séquençage direct d’ARN par nanopore a ouvert une autre voie en faisant passer des molécules d’ARN individuelles à travers un minuscule pore et en mesurant les variations de courant électrique qui dépendent de la structure chimique exacte de chaque base. Les lettres modifiées et non modifiées déforment le signal et le basecalling de manières subtilement différentes, mais interpréter ces données bruitées et de haute dimensionnalité pour de multiples types de modifications a été un défi majeur.
Apprendre à un réseau neuronal à repérer n’importe quelle marque
ORCA (Omni‑RNA modification Characterization and Annotation) relève ce défi en deux étapes. D’abord, il se concentre sur une petite fenêtre autour de chaque position de l’ARN et agrège à la fois le signal électrique brut et le schéma des erreurs de séquençage sur de nombreuses lectures. Parce qu’une fraction seulement des copies d’ARN porte une marque donnée, les sites véritablement modifiés présentent des distributions de signal plus asymétriques et des erreurs de basecalling plus fréquentes à cette position. ORCA utilise un réseau neuronal récurrent profond entraîné avec une stratégie « adversariale » de sorte qu’il apprenne des motifs généraux distinguant les sites modifiés des sites non modifiés, sans se focaliser sur un type chimique connu particulier. Cela permet à ORCA d’attribuer à chaque site un score de modification et une fraction estimée de molécules modifiées.
Apprendre l’identité de chaque marque
Dans la seconde étape, ORCA apprend à étiqueter le type de marque chimique présent. Les auteurs fournissent au modèle un ensemble de sites à haute confiance issus de bases de données publiques, où des expériences conventionnelles ont déjà identifié le m6A, la 5‑méthylcytosine (m5C), la pseudouridine (Ψ), l’inosine, la 2′‑O‑méthylation et plusieurs marques plus rares. ORCA compresse les motifs de signal, le contexte de séquence et les courts « motifs » autour de chaque site en une carte de dimension inférieure, puis s’affine pour prédire le type de modification et la base exacte concernée. Il est crucial que des sites non annotés soient aussi utilisés comme exemples de « fond », ce qui aide le modèle à éviter de forcer des marques inconnues dans des catégories inappropriées. Une fois entraîné, ORCA peut transférer ces étiquettes apprises à des dizaines de milliers de sites auparavant non annotés à travers le transcriptome.
Voir plusieurs modifications à la fois
En appliquant ORCA à des cellules humaines et de souris, les auteurs montrent qu’il égalise ou dépasse l’exactitude des meilleurs outils pour des marques spécifiques comme le m6A, le m5C et la Ψ, mais qu’il peut aussi détecter des marques sur lesquelles il n’a jamais été explicitement entraîné. Par exemple, même lorsque les données de m6A ont été exclues de l’entraînement, ORCA a retrouvé la plupart des sites de m6A mesurés indépendamment et les a correctement distingués de motifs séquentiels similaires non modifiés. Il en a fait de même pour les groupes 2′‑O‑méthyl, les sites d’édition en inosine et une grande variété de modifications chimiques sur l’ARN ribosomique, y compris de nombreuses marques rares mesurées par spectrométrie de masse. Globalement, ORCA élargit considérablement le catalogue connu des sites de modification de l’ARN, avec des augmentations multiples du nombre d’annotations pour le m5C, la Ψ, le m7G et d’autres marques de faible abondance comparé aux bases de données existantes.
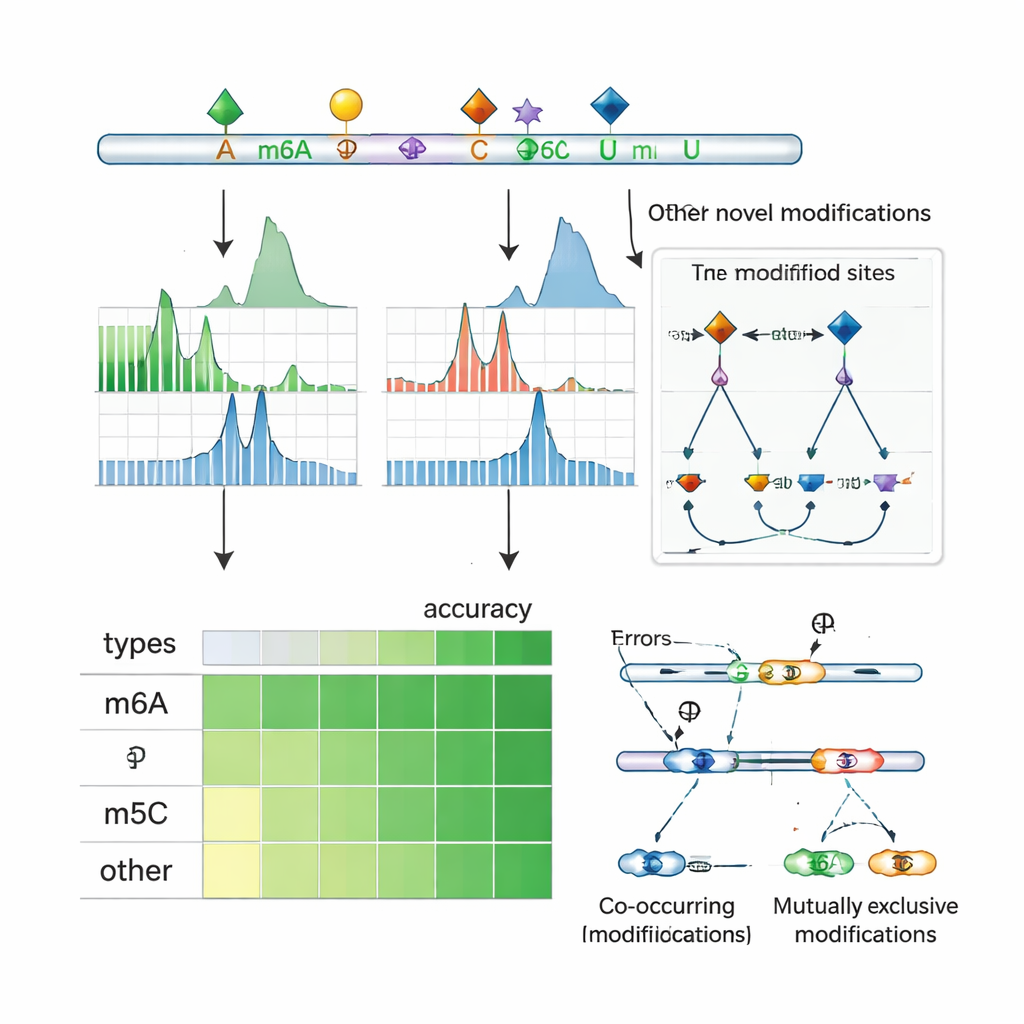
Dénicher les interactions et le contrôle de l’épissage
Parce que le séquençage nanopore lit des molécules d’ARN entières, ORCA peut examiner quelles marques apparaissent ensemble sur le même transcrit et lesquelles tendent à s’exclure mutuellement. Les auteurs regroupent les marques proches le long des ARN et utilisent un modèle probabiliste pour déduire si des paires de sites sont souvent co‑modifiées ou mutuellement exclusives sur des molécules uniques. Ils observent une co‑occurrence fréquente du m6A avec le m5C et d’autres marques, ainsi que de nombreuses régions où un site est modifié seulement lorsque le site voisin ne l’est pas. Dans des lignées cellulaires humaines, ces motifs se situent souvent près d’exons inclus ou exclus de manière alternative et chevauchent des sites de liaison pour des régulateurs d’épissage et des protéines « lectrices » qui reconnaissent l’ARN modifié. Pour certains gènes, ORCA révèle que certains variants d’épissage sont enrichis pour un motif de marques donné, tandis que des variants alternatifs portent un motif différent, reliant l’ornementation chimique locale de l’ARN à la façon dont les messages sont coupés et recousus.
Pourquoi c’est important pour la biologie et la médecine
En combinant le séquençage direct d’ARN avec un apprentissage profond flexible, ORCA transforme un signal électrique complexe en une carte riche et multi‑couches des marques chimiques à travers le transcriptome. Pour les non‑spécialistes, le résultat clé est que les chercheurs peuvent désormais voir non seulement où se produisent les modifications individuelles de l’ARN, mais aussi combien de marques différentes décorent la même molécule et comment ces combinaisons se rapportent à la régulation des gènes, en particulier l’épissage de l’ARN. Ce cadre rend possible l’étude de l’« épigénétique » de l’ARN dans de nombreux types cellulaires et conditions sans concevoir une nouvelle expérience pour chaque marque, ouvrant la voie à des découvertes sur la contribution de ces petits ajustements chimiques au développement, aux fonctions cérébrales et aux maladies telles que le cancer et les troubles neurologiques.
Citation: Dong, H., Gao, Y., Cai, Z. et al. Comprehensive mapping of RNA modification dynamics and crosstalk via deep learning and nanopore direct RNA-sequencing. Nat Commun 17, 1722 (2026). https://doi.org/10.1038/s41467-026-68419-y
Mots-clés: Modifications de l’ARN, Séquençage nanopore, Apprentissage profond, Épitranscriptome, Épissage alternatif