Clear Sky Science · fr
Le rôle des répétitions de faible complexité dans les interactions ARN–ARN et un cadre d’apprentissage profond pour la prédiction de duplex
Séquences ARN « collantes » qui façonnent le comportement cellulaire
À l’intérieur de chaque cellule, les molécules d’ARN se rencontrent en permanence, formant des partenariats éphémères qui participent au contrôle des gènes exprimés, à la fabrication des protéines et au développement cellulaire. Cette étude montre que nombre de ces rencontres ARN–ARN ne sont pas aléatoires : elles sont guidées par de courtes séquences simples et fortement répétées qui agissent comme du Velcro moléculaire. Les chercheurs ont aussi développé un outil d’intelligence artificielle capable de repérer les endroits où de telles paires d’ARN sont susceptibles de se former, ouvrant de nouvelles voies pour explorer le fonctionnement des cellules en santé et en maladie.
Répétitions simples aux effets puissants
L’ARN est souvent décrit comme un messager qui transporte l’information génétique de l’ADN vers les protéines, mais il sert aussi d’échafaudage, de régulateur et de guide. Une grande partie de ces fonctions dépend de l’appariement de deux brins d’ARN. En combinant des données de plusieurs vastes études expérimentales sur cellules humaines et murines, les auteurs montrent que les régions d’ARN qui s’engagent réellement dans ces appariements sont fortement enrichies en ce qu’ils appellent des répétitions de faible complexité. Ce sont des tronçons construits à partir de motifs courts — par exemple des séries de bases G et C — répétés encore et encore. Plutôt que d’être des « déchets » du génome, ces séquences répétitives apparaissent comme des sites d’ancrage privilégiés où un ARN peut se fixer à de nombreux autres, formant des hubs d’interaction denses à l’échelle du transcritome. 
Hubs ARN pour le développement et la régulation
Lorsque l’équipe a examiné quels gènes portent ces sites de contact riches en répétitions, un motif frappant est apparu : beaucoup codent pour des protéines qui contrôlent le développement et l’identité cellulaire, comme des facteurs de transcription. Même dans des lignées cellulaires cancéreuses qui ne se différencient pas activement, les ARN associés à des programmes développementaux étaient fortement impliqués dans des contacts fondés sur des répétitions. Les auteurs se sont aussi intéressés à des ARN non codants longs (lncRNA), molécules qui ne codent pas de protéines mais régulent souvent leur expression. Par exemple, les cibles du lncRNA TINCR et celles d’un autre lncRNA important pour la formation des neurones moteurs, Lhx1os, présentaient toutes deux une surabondance de répétitions complémentaires. Dans ces cas, des répétitions simples sur le lncRNA correspondent à des répétitions complémentaires dans leurs ARN partenaires, permettant des appariements stables qui peuvent contribuer à régler les niveaux ou la traduction de gènes développementaux clés.
Quand les protéines et les enzymes d’édition interviennent
Ces contacts ARN pilotés par des répétitions n’agissent que rarement seuls. Les auteurs ont superposé des cartes de liaison protéique à leurs données d’interaction et ont constaté que de nombreux sites de contact porteurs de répétitions sont également reconnus par des protéines liant l’ARN impliquées dans le contrôle de la traduction, la dégradation de l’ARN et la formation de granules cytoplasmiques tels que les corps P et les granules de stress. Une protéine en particulier, STAU1, qui peut déclencher la destruction de ses ARN cibles, se lie fréquemment aux duplex formés via des répétitions de faible complexité. L’inhibition de STAU1 conduit à des niveaux plus élevés d’ARN impliqués dans ces duplex, en particulier ceux portant des répétitions, ce qui suggère que l’appariement médié par les répétitions peut marquer des transcrits pour une dégradation contrôlée. Les mêmes régions riches en répétitions attirent aussi des enzymes d’édition de l’ARN comme ADAR1, qui modifient chimiquement certaines bases au sein d’ARN double brin, laissant entendre que les répétitions de faible complexité contribuent à positionner des sites d’édition qui ajustent finement le comportement des ARN.
Apprendre à un réseau neuronal à lire les contacts ARN
Les logiciels classiques tentent de prédire la liaison ARN–ARN principalement sur la base de la stabilité thermodynamique — c’est-à-dire de l’énergie nécessaire pour former ou rompre un duplex. Bien que utiles, ces modèles manquent souvent des interactions réelles observées en cellule, notamment entre ARN longs. Pour dépasser ces règles énergétiques simples, les auteurs ont entraîné un modèle d’apprentissage profond nommé RIME qui utilise des embeddings de type « modèles de langage » : des représentations numériques des séquences ARN capturant des motifs appris à partir d’immenses collections de données de nucléotides. RIME se voit présenter des paires de segments ARN et apprend à classer si elles interagissent, en s’appuyant sur de nombreux appariements réels issus d’expériences de réticulation au psoralène comme exemples positifs et sur des paires non interactives soigneusement construites comme négatifs. 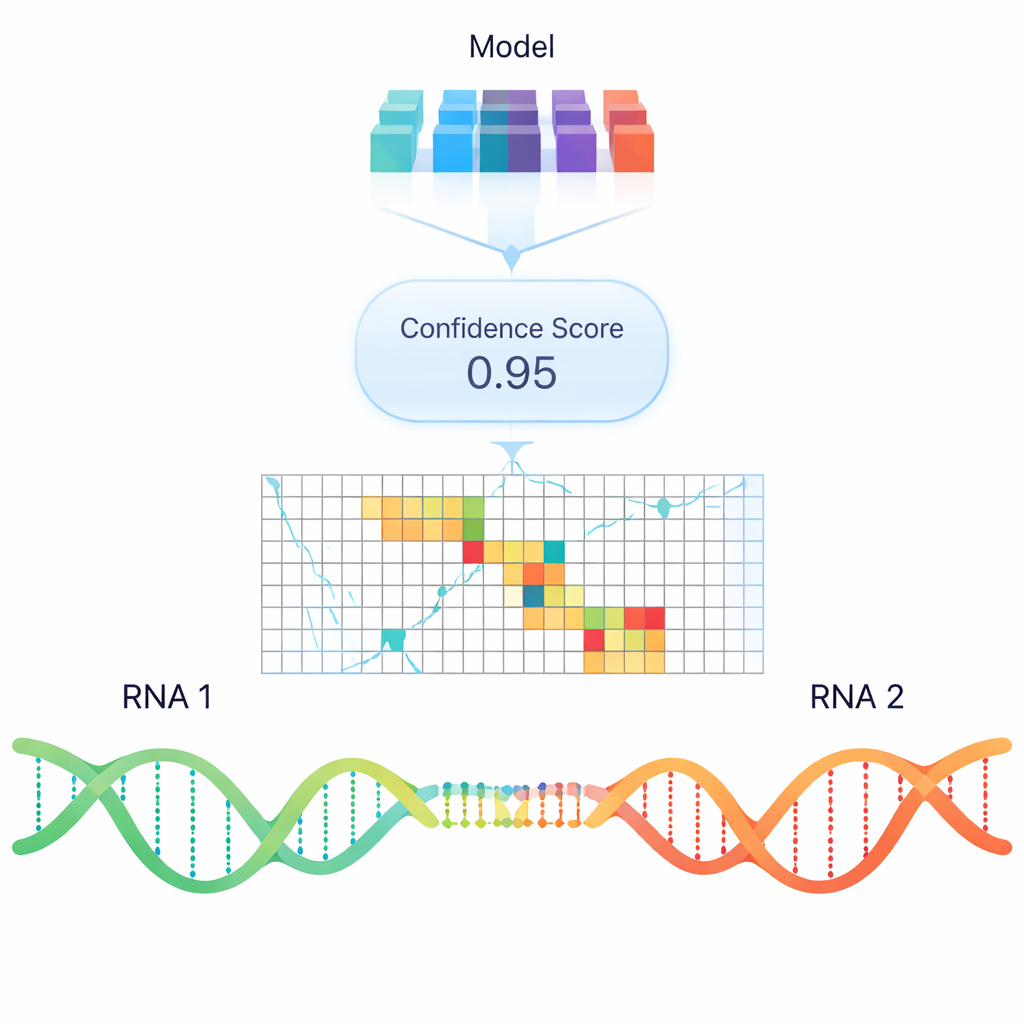
Prédictions plus avisées et nouveaux indices biologiques
Lorsqu’il est comparé aux principaux outils basés sur la thermodynamique et à une autre méthode neuronale, RIME se révèle systématiquement meilleur pour distinguer les vrais contacts ARN–ARN des leurres, en particulier pour les interactions expérimentales à haute confiance. Il ne se contente pas de prédire si deux ARN vont s’apparier : il met souvent en évidence les régions exactes impliquées, et il apprend naturellement que les répétitions de faible complexité sont des prédicteurs puissants de contact. Remarquablement, le même modèle, entraîné uniquement sur des interactions entre ARN distincts, fonctionne également bien pour prédire des appariements internes au sein d’une seule molécule d’ARN, en accord avec des expériences structurales et des algorithmes de repliement classiques. Pour des régulateurs non codants comme TINCR, NORAD et SMaRT, RIME redécouvre avec succès des sites d’interaction fonctionnels connus et suggère des régions candidates supplémentaires.
Pourquoi c’est important
Pour le lecteur non spécialiste, le message clé est que de courts tronçons répétitifs dans l’ARN — autrefois faciles à écarter comme du bruit sans intérêt — agissent comme des points de connexion centraux dans le réseau d’interactions ARN de la cellule. Ils favorisent la rencontre des ARN, attirent des protéines régulatrices et des enzymes d’édition, et sont largement utilisés dans des voies qui contrôlent le développement cellulaire et la réponse au stress. Le nouveau modèle RIME offre aux chercheurs un moyen puissant de scruter les génomes à la recherche de ces partenariats ARN–ARN, y compris ceux qui peuvent mal tourner dans des maladies neurologiques et autres affections liées à l’expansion de répétitions. En substance, ce travail montre que comprendre — et prédire — comment de simples répétitions ARN s’assemblent peut révéler des couches cachées de la régulation génique.
Citation: Setti, A., Bini, G., Pellegrini, F. et al. The role of low-complexity repeats in RNA–RNA interactions and a deep learning framework for duplex prediction. Nat Commun 17, 1637 (2026). https://doi.org/10.1038/s41467-026-68356-w
Mots-clés: Interactions ARN–ARN, Répétitions de faible complexité, ARN non codant long, Apprentissage profond, Régulation génique