Clear Sky Science · fr
Estimation et édition d’éclairage neural à vue unique pour affichage dynamique de champs lumineux
Pourquoi votre monde virtuel devrait correspondre à votre salon
Quiconque a porté un casque de réalité virtuelle ou mixte l’a remarqué : un objet numérique peut sembler étrangement déplacé, avec un éclairage et des ombres qui ne correspondent pas tout à fait à la pièce dans laquelle vous vous trouvez. Cet article s’attaque à ce problème. Les auteurs présentent une méthode permettant aux casques de « comprendre » l’éclairage de votre environnement réel à partir d’une seule vue caméra, puis d’utiliser cette connaissance pour que les objets virtuels donnent l’impression d’appartenir réellement à votre monde — sans nécessiter de sondes lumineuses spéciales, de captures élaborées ou de recalibrages lourds.
Rendre la lumière en espace plus facile à gérer
En physique et en infographie, l’apparence d’une scène est gouvernée par son « champ lumineux » complet : l’ensemble des rayons lumineux qui traversent l’espace dans toutes les directions. Reconstruire précisément ce champ exige normalement beaucoup de données, nécessitant de nombreuses images et des mesures soignées. Les techniques 3D modernes comme les champs de radiance neuronaux peuvent encoder des scènes dans des réseaux neuronaux, mais elles « figent » généralement l’éclairage présent lors de la capture. Cela signifie que la scène virtuelle paraît correcte seulement dans ces conditions lumineuses d’origine et se dégrade lorsque l’éclairage réel change. Les auteurs cherchent à dépasser cette limitation en trouvant une description compacte de l’illumination réelle à partir de données minimales, puis en l’utilisant pour rééclairer de manière flexible une scène 3D neurale.
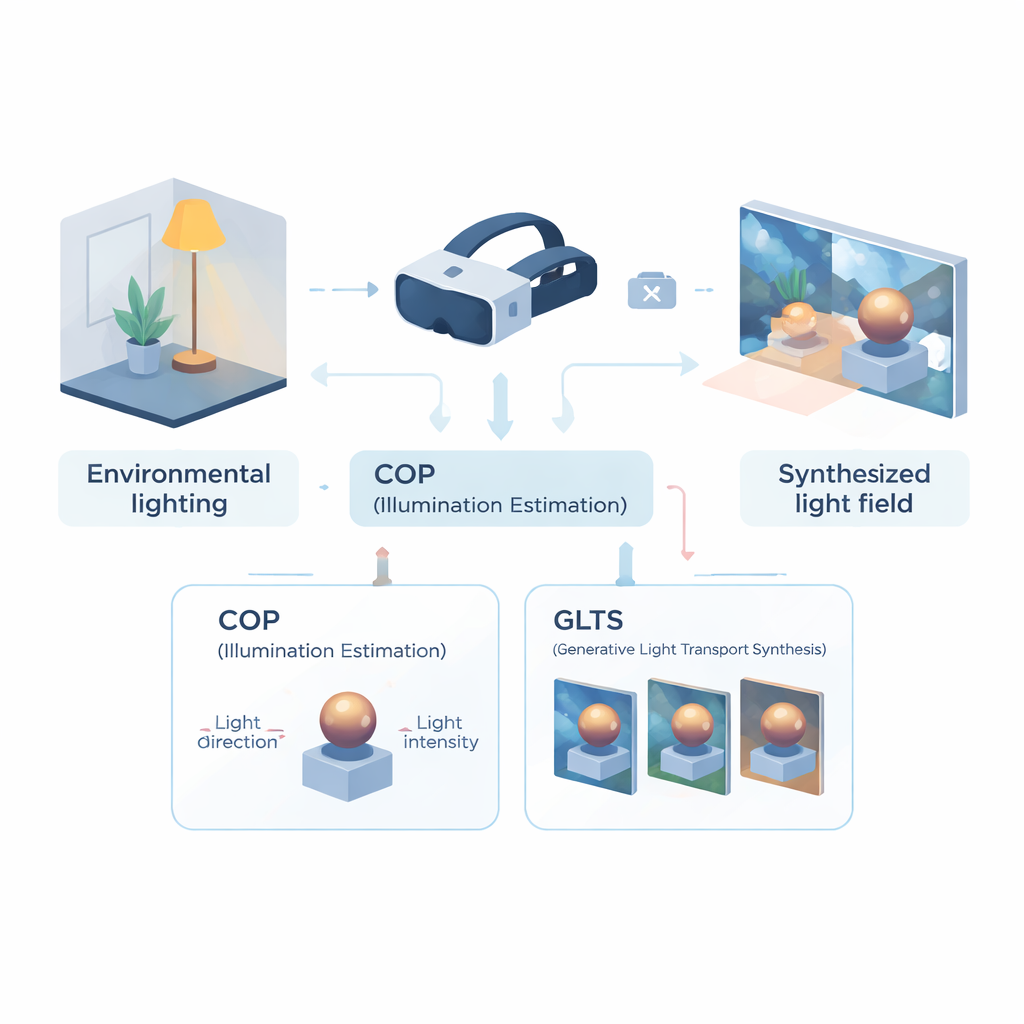
Apprendre au casque à lire la pièce
La première partie du dispositif est un module de perception optique computationnelle (COP), conçu pour extraire l’éclairage à partir d’une seule vue caméra. Plutôt que de reconstruire l’intégralité du champ lumineux, le COP se concentre sur la source lumineuse dominante : sa direction et son intensité. Un réseau neuronal multi-échelle analyse l’image d’entrée à la recherche d’indices physiquement significatifs — reflets brillants, gradients d’ombrage et ombres — tandis qu’une étape d’interpolation spéciale corrige la manière non linéaire dont les caméras compressent la luminosité. Cela fournit des estimations numériques d’intensité et de direction de la lumière qui sont plus fidèles à l’énergie réelle présente dans la scène. Une seconde étape, appelée interprète sémantique, affine ensuite ces valeurs et produit une description textuelle courte de l’éclairage (par exemple, que la lumière vient d’en haut et de la droite). Cette combinaison de nombres et de mots rend l’estimation plus stable et plus simple à exploiter dans les étapes suivantes.
Repeindre les objets sous une nouvelle lumière
Munie de cette description compacte de l’illumination, la seconde partie — synthèse générative du transport lumineux (GLTS) — prend le relais. GLTS part d’une représentation 3D neuronale existante d’un objet ou d’une scène, rendue une fois sous l’éclairage ancien figé. Guidé par la direction et l’intensité lumineuse inférées ainsi que par la description textuelle, un réseau génératif « repeint » cette vue pour que les hautes lumières et les ombres correspondent au nouvel environnement. Pour que le résultat reste à la fois réaliste et fidèle à l’objet, GLTS combine deux types de guidage : un contrôle global issu des paramètres d’éclairage et des détails fins extraits directement de l’image observée. Grâce à un entraînement spécialisé qui se concentre uniquement sur la manière dont un objet réagit à différents éclairages, le modèle apprend à déplacer les réflexions et à adoucir les bords d’ombre de façon physiquement plausible plutôt que d’appliquer un filtre de style générique.
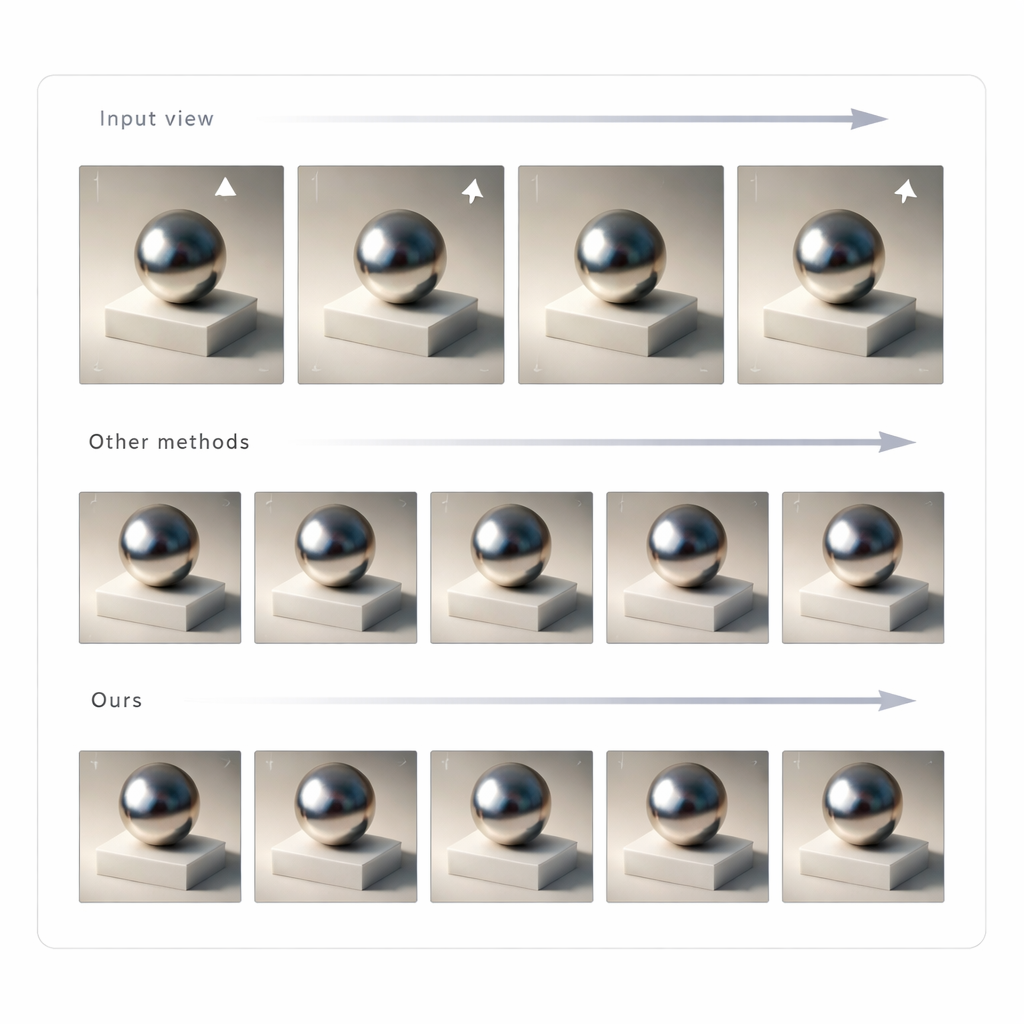
Construire un champ lumineux 3D cohérent à partir de multiples vues
Changer une image unique ne suffit pas pour une réalité mixte convaincante ; l’éclairage doit rester cohérent lorsque vous bougez la tête. Pour y parvenir, les auteurs utilisent GLTS pour générer un ensemble d’images rééclairées depuis de nombreux points de vue, puis traitent ces images comme cibles pour reconstruire la scène 3D. Un processus d’optimisation conjoint ajuste simultanément la représentation 3D neuronale et les positions des caméras virtuelles afin que le rendu du nouveau modèle reproduise toutes les vues synthétisées. Cette étape corrige les distorsions subtiles introduites par le réseau génératif et produit un actif 3D cohérent dont l’apparence reste stable et crédible quel que soit l’angle. L’équipe a comparé sa méthode à plusieurs approches de rééclairage de pointe et a constaté qu’elle offrait une meilleure concordance avec les images de référence et des ombres et réflexions d’aspect plus naturel, évaluées à la fois par des métriques au niveau des pixels et par des mesures basées sur la perception.
Ce que cela signifie pour les casques de demain
Pour les non-spécialistes, l’idée principale est que ce travail montre comment les futurs appareils VR, AR et de réalité mixte pourraient adapter le contenu virtuel à l’éclairage réel à partir d’un simple coup d’œil rapide via la caméra du casque. Plutôt que des configurations de capture laborieuses ou la réentraînement de modèles sur mesure pour chaque nouvelle scène, le système estime les conditions lumineuses principales, régénère l’apparence que la scène devrait avoir sous ces conditions et reconstruit une représentation 3D cohérente. Le résultat : des objets virtuels dont la luminosité, la brillance et les ombres réagissent à votre environnement comme le feraient des objets réels, ouvrant la voie à des expériences de réalité mixte qui ressemblent moins à des graphiques superposés et davantage à des ajouts authentiques au monde physique.
Citation: Hong, X., Xie, J., Sheng, J. et al. Single-view neural illumination estimation and editing for dynamic light field display. Light Sci Appl 15, 147 (2026). https://doi.org/10.1038/s41377-026-02234-4
Mots-clés: éclairage réalité mixte, champs lumineux neuronaux, re-éclairage à vue unique, affichages de réalité virtuelle, imagerie computationnelle