Clear Sky Science · fr
Reconnaissance d’images culturelles multimodale basée sur un réseau de fusion quantique et classique
Pourquoi il est important d’apprendre aux ordinateurs à reconnaître les trésors anciens
Les trésors culturels conservés dans les musées et les archives sont de plus en plus photographiés et mis en ligne, mais la plupart de ces images sont mal étiquetées ou ne le sont pas du tout. Cela complique la tâche des visiteurs, des enseignants et des chercheurs qui cherchent des objets précis, et limite la profondeur avec laquelle le public peut explorer l’héritage partagé de l’humanité. Cet article explore une nouvelle manière de reconnaître et de trier automatiquement ces images en combinant deux idées qui se rencontrent rarement : les collections muséales et l’informatique quantique.
Des réserves poussiéreuses aux collections numériques
Les musées détiennent aujourd’hui des millions d’objets, des bronzes et laques aux robes brodées. Nombre d’institutions se pressent de numériser ces collections pour que toute personne disposant d’une connexion Internet puisse les consulter. Mais une fois les images en ligne, il faut les classer dans les bonnes catégories — par exemple émaux, jade, soie ou brocart — pour qu’elles soient vraiment utiles. Les outils d’intelligence artificielle conventionnels ne regardent généralement que les pixels de chaque image. Ils ignorent les riches descriptions écrites que les conservateurs et les historiens joignent aux objets, alors que ces légendes mentionnent souvent des matériaux, des couleurs et des motifs qui ne sont pas évidents à l’œil. À mesure que les collections grandissent, les algorithmes classiques peinent aussi en termes de vitesse, de consommation d’énergie et de complexité.
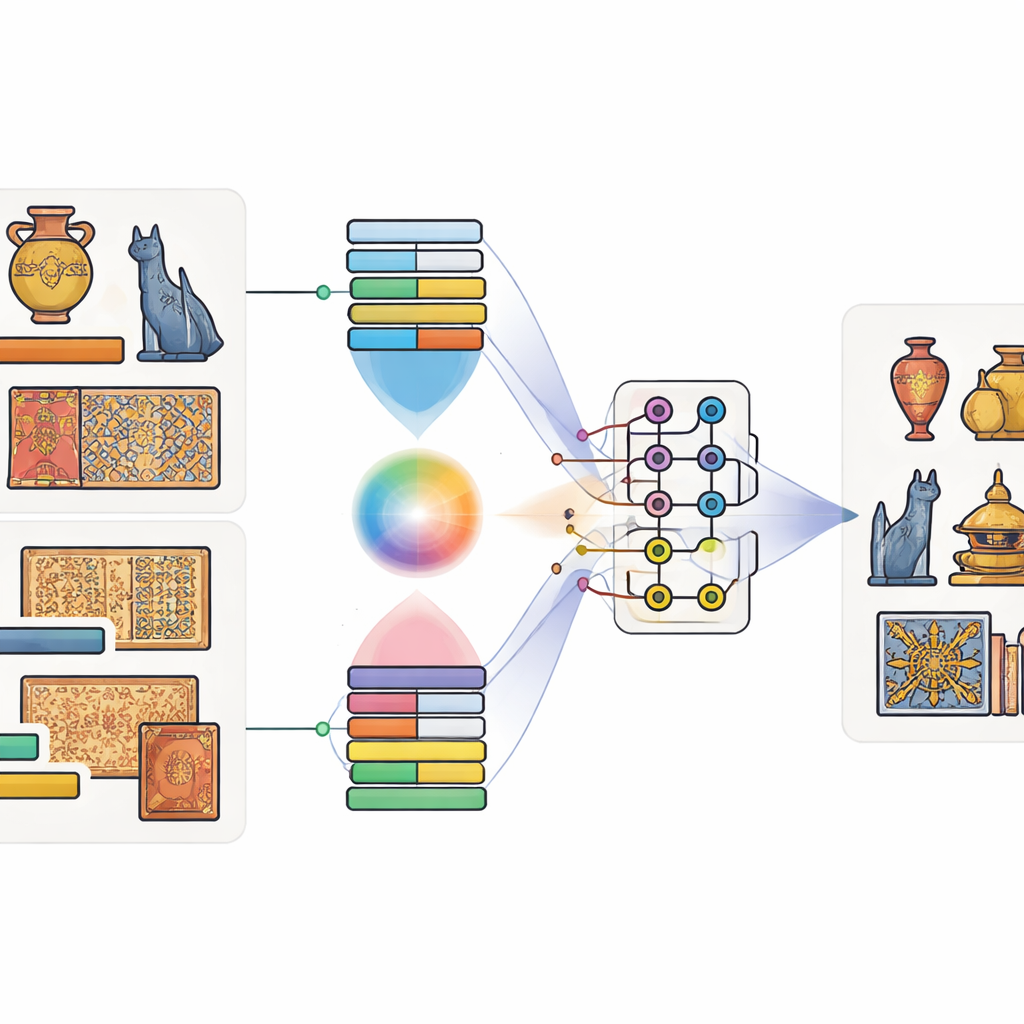
Associer images et mots, bits et qubits
Les auteurs proposent un modèle qu’ils appellent Modèle de Fusion Multimodale Quantique-Classique. « Multimodale » signifie simplement qu’il prend en compte plusieurs types d’informations à la fois — ici l’image d’un artefact et sa légende. D’abord, des outils éprouvés entraînés sur d’énormes jeux de données sont utilisés : un réseau profond pour capter formes et textures, et un modèle de langage pour saisir le sens de la légende. Un mécanisme d’attention particulier apprend ensuite quelles régions de l’image correspondent le plus souvent à quels mots. Par exemple, lorsqu’une légende évoque un “dragon doré”, le modèle apprend à se focaliser sur les zones de couleur or en forme de dragon. Cela produit une description conjointe qui mêle vision et langage.
Laisser les circuits quantiques mélanger les signaux
Une fois les caractéristiques image-et-texte extraites, le modèle les injecte dans un petit circuit quantique simulé. Comme le matériel quantique actuel ne dispose que d’un nombre limité de qubits, les auteurs compressent l’information à l’aide d’un procédé qui encode de nombreuses valeurs classiques dans les amplitudes de quelques qubits. Dans la partie quantique, ils conçoivent un circuit en deux étapes qui applique à plusieurs reprises des rotations sur des qubits individuels puis les enchevêtre — rendant leurs états interdépendants. Cette structure vise à révéler des relations subtiles entre motifs visuels et indices textuels qui pourraient autrement passer inaperçues. Après ce traitement quantique, l’état des qubits est mesuré et reconverti en nombres ordinaires, ensuite transmis à un classifieur final qui prédit la catégorie de l’objet.
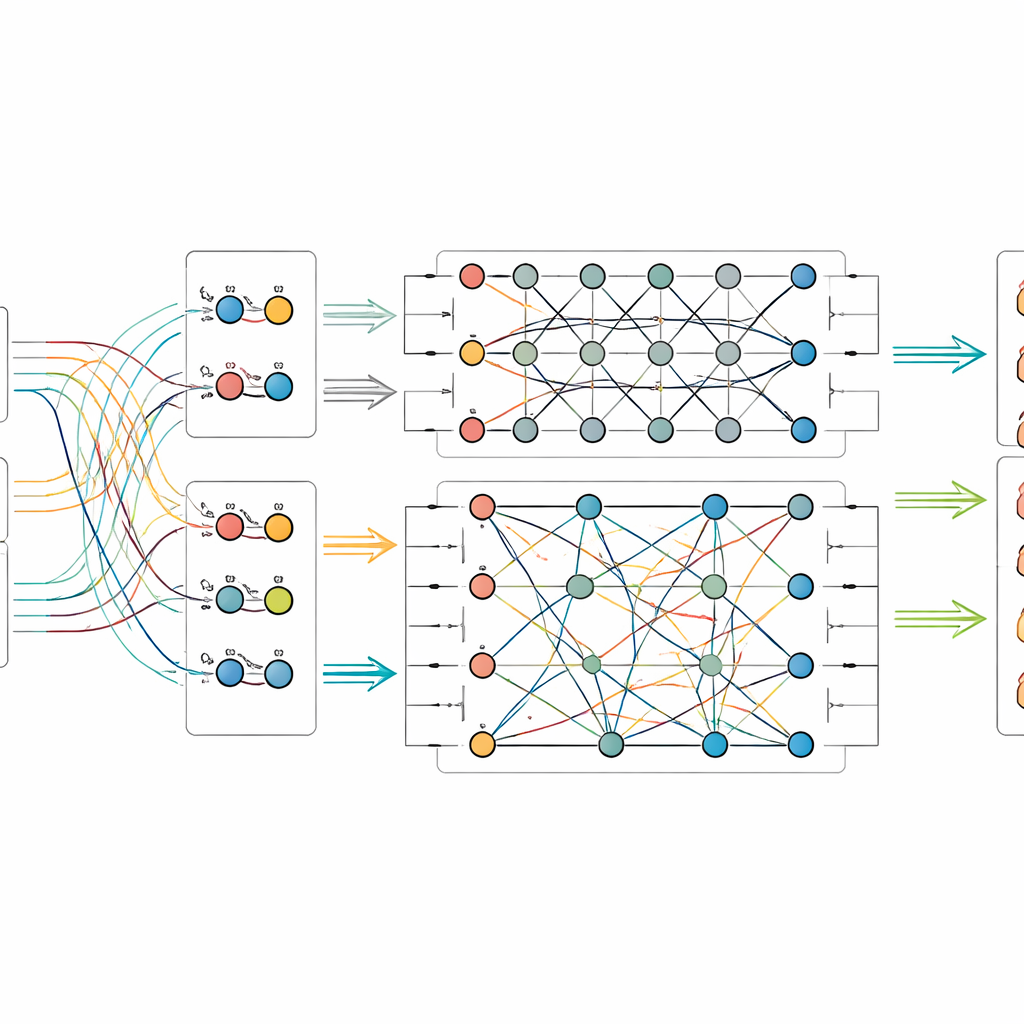
Tester la nouvelle approche
Pour vérifier si leur méthode apporte des bénéfices réels, les chercheurs ont constitué deux nouveaux jeux de données issus du Palais Impérial : l’un d’artefacts physiques comme émaux, ouvrages en or et argent, laque, bronze et jade, l’autre centré sur les textiles tels que soie, satin, brocart et le style de tissage complexe connu sous le nom de kesi. Chaque image est accompagnée d’une légende officielle et d’une étiquette fiable issue des registres du musée. Ils ont comparé leur modèle de fusion quantique–classique à une gamme de rivaux solides, y compris des systèmes purement image, purement texte et d’autres techniques combinant les deux. Sur les deux jeux de données, le nouveau modèle a obtenu les meilleurs scores en précision et mesures connexes, dépassant même des méthodes multimodales avancées et des approches inspirées du quantique. D’autres expériences ont montré comment ses performances dépendent du nombre de qubits et de la profondeur du circuit, et qu’il reste robuste même lorsque des types courants de bruit quantique sont introduits en simulation.
Ce que cela pourrait signifier pour les futurs visiteurs de musées
Pour les non-spécialistes, le message principal est que la combinaison d’images, de textes et d’un traitement inspiré du quantique peut rendre les ordinateurs meilleurs pour distinguer différents types d’objets culturels. Bien que les parties quantiques tournent actuellement sur des simulateurs plutôt que sur des machines quantiques à grande échelle, l’étude suggère une voie vers des outils plus efficaces et expressifs à mesure que le matériel progresse. Concrètement, de tels systèmes pourraient aider les musées et les archives à trier automatiquement les nouvelles contributions, nettoyer les anciens enregistrements et faciliter la recherche de termes comme « vases rituels en jade » ou « robes brodées de dragons » et à les retrouver réellement. Ce travail laisse entrevoir que l’informatique quantique pourrait devenir une nouvelle voie utile pour comprendre et préserver le patrimoine culturel à l’ère numérique.
Citation: Fan, T., Wang, H., Zhao, Y. et al. Multimodal cultural heritage image recognition based on quantum and classical multimodal fusion network. npj Herit. Sci. 14, 160 (2026). https://doi.org/10.1038/s40494-026-02419-5
Mots-clés: images du patrimoine culturel, apprentissage automatique quantique, fusion multimodale, numérisation des musées, reconnaissance d’images