Clear Sky Science · fr
Identification d’informations visuelles et Q&R sur les héritiers du patrimoine culturel immatériel en utilisant un cadre amélioré Graph-Retrieval
Faire entrer les traditions cachées dans l’ère numérique
À travers la Chine, des maîtres d’opéra traditionnel, de découpage de papier, de théâtre d’ombres et d’autres arts vivants préservent des savoir-faire transmis depuis des générations. Pourtant, une grande partie de l’information sur ces héritiers n’existe que sous forme de fichiers et d’images dispersés en ligne, ce qui rend difficile pour le grand public — ou même pour les chercheurs — de trouver des informations fiables. Cet article présente un nouveau cadre informatique qui lit automatiquement les « cartes de visite visuelles » des héritiers du patrimoine culturel immatériel (PCI) puis utilise des modèles de langage avancés pour répondre à des questions et générer des rapports lisibles à leur sujet.
Des fiches illustrées aux connaissances structurées
De nombreuses institutions culturelles publient désormais des fiches numériques qui combinent texte, mise en page et graphiques simples pour présenter chaque héritier : nom, art, lieu, biographie, etc. Les humains peuvent les parcourir en un coup d’œil, mais les ordinateurs ont du mal car les fiches proviennent de régions diverses, adoptent des designs variés et contiennent souvent du texte manquant ou endommagé. Les auteurs constituent un grand jeu de données de 5 237 de ces fiches pour des héritiers du PCI chinois, chacune étiquetée avec soin selon dix types d’information clés, comme le numéro du projet, le nom du projet, la région, le genre, l’unité de travail et une courte description. Ils utilisent d’abord la reconnaissance optique de caractères (OCR) pour lire le texte et enregistrer la position de chaque fragment sur la fiche, puis emploient de grands modèles de langage pour aider à standardiser les étiquettes avant que des experts humains ne les vérifient.
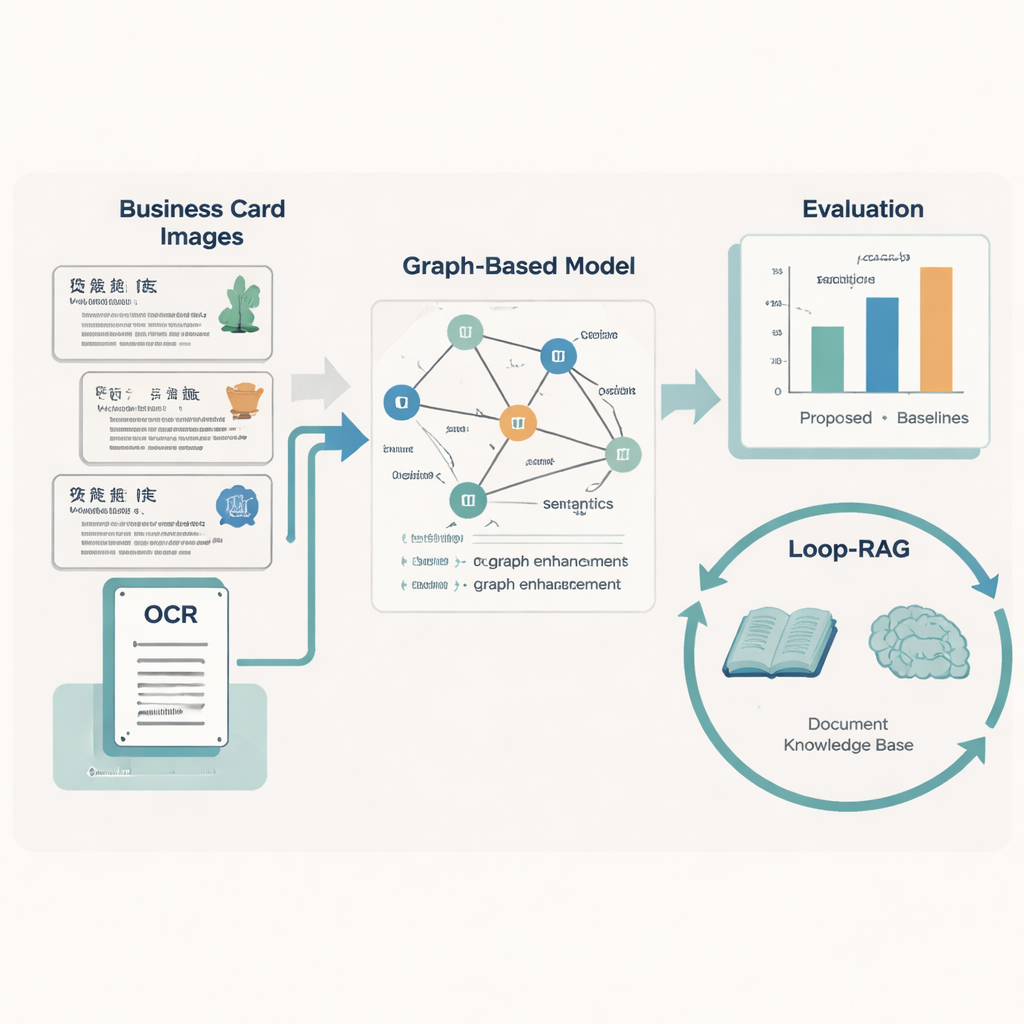
Apprendre aux machines à lire la mise en page et le sens
Pour transformer chaque fiche en données propres et structurées, l’équipe conçoit un modèle « Graph-Retrieval » qui imite la manière dont les humains utilisent à la fois les mots et la mise en page. Chaque fragment de texte sur une fiche devient un nœud dans un graphe, et les relations spatiales entre fragments — à gauche, à droite, au-dessus, en dessous — forment les arêtes. Un composant linguistique basé sur RoBERTa et un LSTM bidirectionnel apprend le sens du texte, soutenu par un dictionnaire personnalisé de près de 5 000 termes spécifiques au PCI afin de traiter correctement les noms d’artisanats inhabituels ou les expressions locales. Par-dessus cela, un réseau de neurones graphes diffuse l’information entre nœuds voisins, améliorant les prédictions sur ce que représente chaque fragment de texte (par exemple, décider si un toponyme est une région ou une unité de travail).
Rendre le système robuste aux imperfections du monde réel
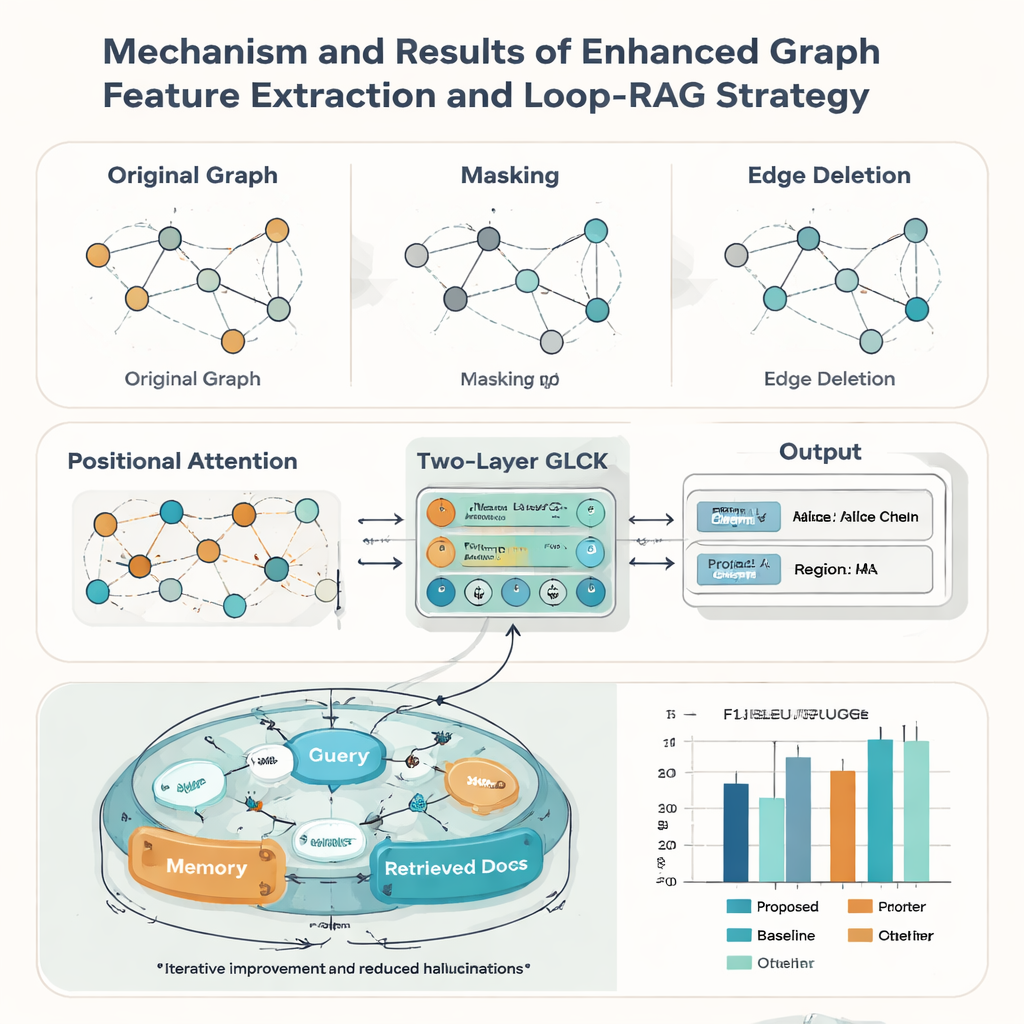
Les documents du patrimoine sont rarement parfaits : les fiches peuvent être usées, recadrées ou mal numérisées. Pour y faire face, les auteurs renforcent leur modèle de graphe avec trois idées empruntées à l’augmentation de données. Ils masquent aléatoirement certains nœuds afin que le système apprenne à inférer l’information manquante à partir du contexte ; ils suppriment aléatoirement certaines arêtes pour qu’il tolère les changements de mise en page ; et ils ajoutent un mécanisme d’attention positionnelle qui saisit l’« ordre de lecture » global des éléments sur une fiche. Ensemble, ces astuces aident le modèle à se généraliser à de nombreux styles et qualités de documents. Dans des tests face à neuf méthodes concurrentes bien connues, la nouvelle approche obtient le meilleur score F1 macro-moyen (0,928) sur le jeu de données de fiches PCI et domine également sur cinq bancs d’essai publics de documents, ce qui suggère qu’elle est utile au-delà des seules applications patrimoniales.
Des questions mieux répondues grâce à une récupération itérative
Reconnaître le texte ne suffit pas ; la seconde contribution de l’article est une stratégie Loop-RAG (Loop Retrieval-Augmented Generation) qui fonctionne avec de grands modèles de langage tels que GPT-4, Llama et ChatGLM. Les systèmes traditionnels augmentés par récupération vont chercher des documents de contexte une fois puis génèrent une réponse, ce qui peut rester incomplet ou erroné. En revanche, Loop-RAG ajoute une boucle interne qui vérifie à répétition si le modèle de langage dispose d’informations suffisantes pour la réponse en cours et, si ce n’est pas le cas, déclenche une nouvelle recherche ciblée dans une base de connaissances vectorisée du PCI. Une boucle externe étudie ensuite de nombreuses interactions passées pour apprendre quelles voies de récupération et quels styles d’amorces fonctionnent le mieux, réduisant progressivement les recherches inutiles et les erreurs factuelles.
Des dossiers bruts aux récits culturels fiables
En utilisant ce cadre combiné, le système peut automatiquement créer de courts rapports sur un héritier — résumant son art, sa région, ses œuvres représentatives et son statut — et répondre à des milliers de questions factuelles sur des personnes et des pratiques. Mesuré par des scores de qualité linguistique standard tels que BLEU, METEOR et ROUGE, Loop-RAG avec GPT-4 surpasse à la fois les modèles de langage simples et les configurations de récupération plus élémentaires, tout en atteignant la meilleure précision (F1 jusqu’à 0,941) en question-réponse, même lorsque seuls quelques exemples sont fournis. Pour un lecteur non spécialiste, cela signifie que de futures plateformes patrimoniales pourraient offrir des explications interactives et fiables sur demande concernant les arts traditionnels, transformant des dossiers numériques dispersés en récits riches et navigables qui contribuent à maintenir la visibilité et la valeur des traditions vivantes.
Citation: Wang, R., Zhang, X., Liu, Q. et al. Visual information identification and Q&A of intangible cultural heritage inheritors by using enhanced Graph-Retrieval framework. npj Herit. Sci. 14, 113 (2026). https://doi.org/10.1038/s40494-026-02384-z
Mots-clés: patrimoine culturel immatériel, extraction d’informations, réseaux de neurones graphes, génération augmentée par récupération, humanités numériques