Clear Sky Science · fr
Geo-TCAM : une méthode de légendage de Thangka intégrant le topic modeling et une attention spatiale guidée par la géométrie
L'art ancien rencontre la technologie intelligente
Les peintures Thangka — ces tentures vivement colorées que l'on voit dans de nombreux temples tibétains — regorgent de petits détails et de couches de sens religieux. Pour les visiteurs de musée ou les spectateurs en ligne sans formation spécialisée, une grande partie de ce symbolisme est difficile à appréhender. Cette étude présente Geo‑TCAM, un système d'intelligence artificielle (IA) conçu pour générer automatiquement des descriptions riches et précises des images de Thangka, aidant ainsi les publics du monde entier à mieux comprendre et préserver ce patrimoine culturel unique.
Pourquoi les Thangka sont difficiles pour les ordinateurs
Contrairement aux photos du quotidien, les Thangka sont délibérément denses et symboliques. Une seule peinture peut contenir une divinité centrale, des dizaines de petites figures, des bordures à motifs, ainsi que des gestes de la main, des objets, des couleurs et des postures spécifiques qui portent chacun une signification religieuse. Les programmes classiques de génération de légendes fonctionnent souvent bien pour des scènes simples comme « un chien sur une plage », mais ils peinent ici : ils peuvent identifier le bouddha principal tout en manquant s’il tient un bol ou une épée, mal interpréter sa posture ou le confondre avec une autre divinité d'apparence similaire. Ces erreurs ne sont pas triviales — elles peuvent inverser l'histoire et la doctrine que la peinture cherche à transmettre, sapant ainsi sa valeur éducative et culturelle.
Un nouveau schéma pour décrire les images sacrées
Geo‑TCAM aborde ces problèmes en combinant trois idées : des caractéristiques visuelles multi‑niveaux, des connaissances thématiques sur l'art Thangka et une attention guidée par la géométrie sur des zones clés comme les visages. D'abord, il utilise un réseau profond (ResNet50) pour analyser chaque image à plusieurs niveaux simultanément : les couches intermédiaires saisissent les contours, textures et formes simples, tandis que les couches profondes résument la composition globale. En fusionnant ces niveaux, le modèle peut repérer à la fois des détails fins tels que les ornements et l'agencement général des personnages et de l'arrière‑plan, offrant une compréhension visuelle plus riche que les systèmes antérieurs focalisés sur une seule couche. 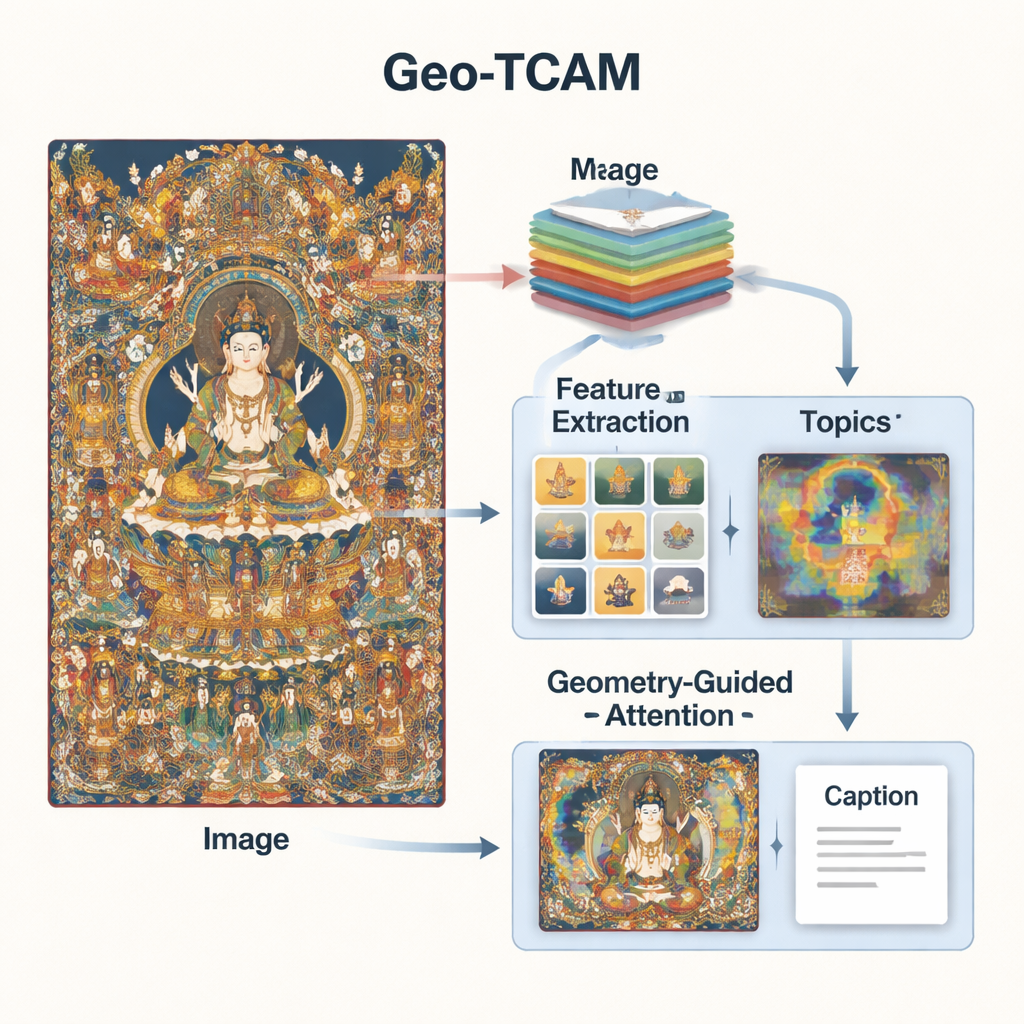
Apprendre au modèle les « thèmes » du Thangka
La vision seule ne suffit pas ; le système a aussi besoin d'une connaissance du langage et des thèmes du Thangka. Pour cela, les chercheurs ont entraîné un modèle de topics sur des milliers de descriptions de Thangka rédigées par des experts. Ce modèle regroupe les mots en quelques thèmes courants — par exemple ceux liés aux bouddhas, aux bodhisattvas, aux trônes de lotus, aux instruments rituels ou aux divinités protectrices. Pour chaque nouvelle image, Geo‑TCAM estime les thèmes les plus pertinents et combine cette information aux caractéristiques visuelles. Un mécanisme d'attention met ensuite en évidence les régions de l'image qui correspondent le mieux aux thèmes probables. En pratique, la connaissance a priori des objets et symboles qui apparaissent souvent ensemble oriente l'IA vers des descriptions plus significatives et culturellement informées.
Laisser l'IA « regarder » là où cela compte
La troisième innovation est un module d'attention spatiale faciale guidée par la géométrie (GFSA). Les compositions de Thangka placent généralement le visage de la figure principale dans des régions relativement prévisibles de la toile. Geo‑TCAM utilise des outils simples de détection de contours pour cibler cette zone ainsi que les mains et la posture environnantes, puis applique un mécanisme d'attention dédié qui amplifie l'influence de ces pixels lors de la génération de la légende. Cette stratégie « localiser d'abord, guider ensuite » aide à éviter une mauvaise identification précoce de la divinité centrale, qui conduirait sinon à une cascade d'erreurs textuelles sur les gestes, attributs et statuts. Les cartes thermiques visuelles montrent qu'avec le GFSA le modèle se concentre plus proprement sur le visage de la figure principale et les objets clés tout en conservant la présence des motifs d'arrière‑plan importants. 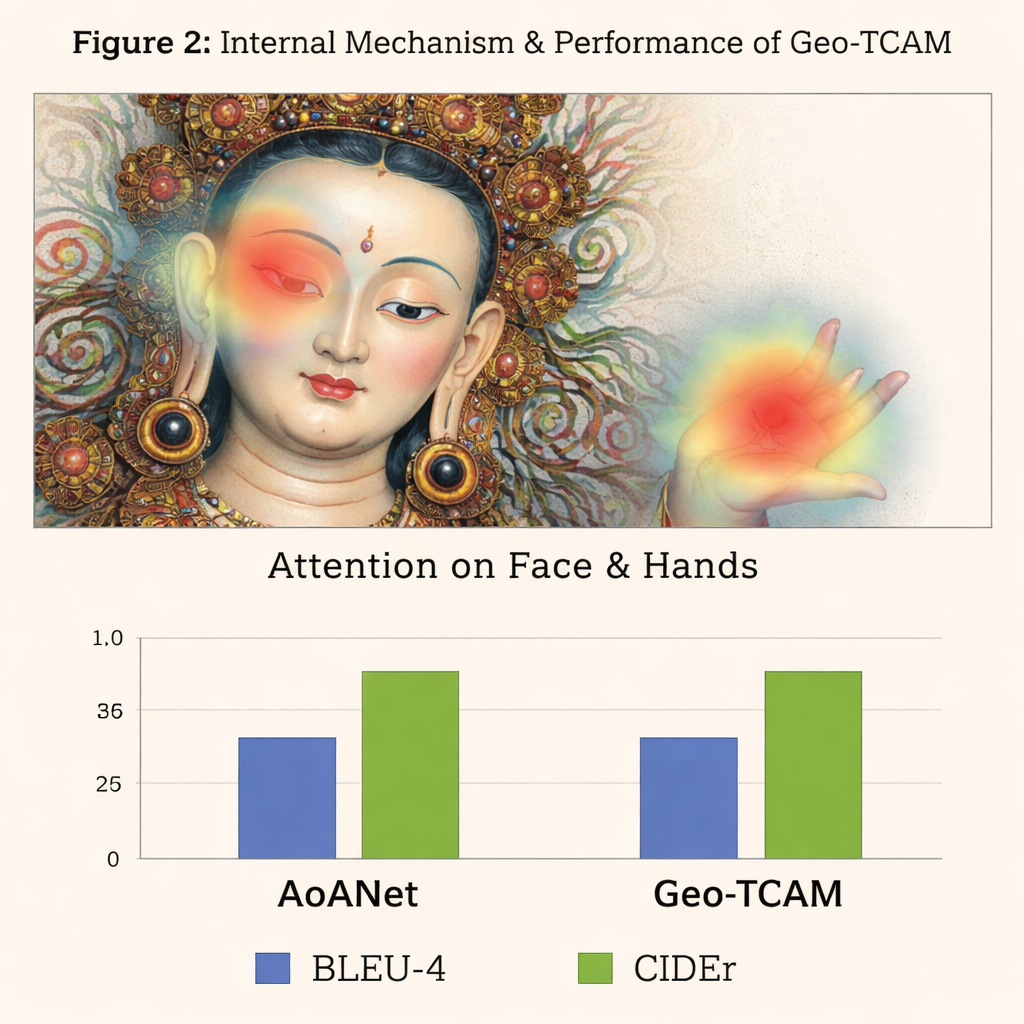
Quel est le niveau de performance de Geo‑TCAM ?
Pour évaluer leur approche, les auteurs ont constitué un jeu de données spécialisé D‑Thangka de près de 4 000 images soigneusement annotées, chacune accompagnée de descriptions détaillées d'experts. Sur cet ensemble, Geo‑TCAM a nettement surpassé plusieurs systèmes de légendage de référence, y compris le populaire AoANet et des grands modèles vision‑langage. Selon la métrique, ses scores se sont améliorés jusqu'à environ 120 % par rapport à la référence, et les évaluateurs humains ont massivement préféré ses légendes pour leur exactitude, leur fluidité et la richesse des détails. Fait important, lorsque le même modèle a été testé sur une collection standard de photos du quotidien (le jeu de données COCO), il est resté compétitif par rapport aux méthodes de pointe, montrant que sa conception est puissante tout en restant polyvalente.
Ce que cela signifie pour le patrimoine et au‑delà
Pour les non‑experts, la conclusion principale est que Geo‑TCAM peut transformer des peintures Thangka visuellement complexes en récits clairs et informatifs qui expliquent qui est représenté, ce qu'il fait et pourquoi ces détails importent. En mêlant analyse visuelle en couches, thèmes appris à partir de textes d'experts et attention particulière portée aux visages et aux gestes, le système aligne ses légendes beaucoup plus étroitement sur la façon dont les spécialistes humains lisent ces œuvres. À long terme, de tels outils pourraient soutenir les archives numériques, les guides de musée et les plateformes éducatives, rendant l'art religieux ésotérique plus accessible tout en aidant conservateurs et chercheurs à documenter et protéger des trésors culturels fragiles.
Citation: Zhong, P., Hu, W., Zhao, Y. et al. Geo-TCAM: a Thangka captioning method integrating topic modeling with geometry-guided spatial attention. npj Herit. Sci. 14, 87 (2026). https://doi.org/10.1038/s40494-026-02343-8
Mots-clés: Légendage d'images de Thangka, IA pour le patrimoine culturel, attention visuelle, topic modeling, préservation des œuvres d'art