Clear Sky Science · fr
Construction du corpus étiqueté en partie du discours des Vingt-Quatre Histoires anciens-modernes
Pourquoi les anciennes chroniques comptent à l’ère de l’IA
Depuis plus de deux millénaires, les historiens chinois ont consigné guerres, cours, famines et vie quotidienne dans la vaste série connue sous le nom des Vingt-Quatre Histoires. Aujourd’hui, ces classiques sont redécouverts non seulement par les savants, mais aussi par les ordinateurs. Cette étude décrit comment des chercheurs ont transformé ces chroniques anciennes et leurs traductions en chinois moderne en une base de données linguistique soigneusement annotée. Cette ressource peut aider l’intelligence artificielle à lire, traduire et analyser les textes historiques de manière plus précise — et rendre le passé lointain beaucoup plus accessible au grand public.
Des volumes poussiéreux au texte numérique
Le projet commence par une tâche basique mais redoutable : convertir des millions de caractères imprimés en un texte numérique propre et précis. L’équipe s’est appuyée sur deux sources — une édition moderne définitive des Vingt-Quatre Histoires et une grande collection en ligne — pour alimenter un système de reconnaissance optique de caractères. Ils ont ensuite retiré, avec patience, les passages corrompus, corrigé les caractères mal lus et éliminé le bruit tel que les en-têtes et bas de page. Le résultat est un ensemble parallèle de fichiers, l’un en chinois ancien et l’autre en chinois moderne, qui reproduit fidèlement les livres originaux mais est prêt pour l’analyse informatique. 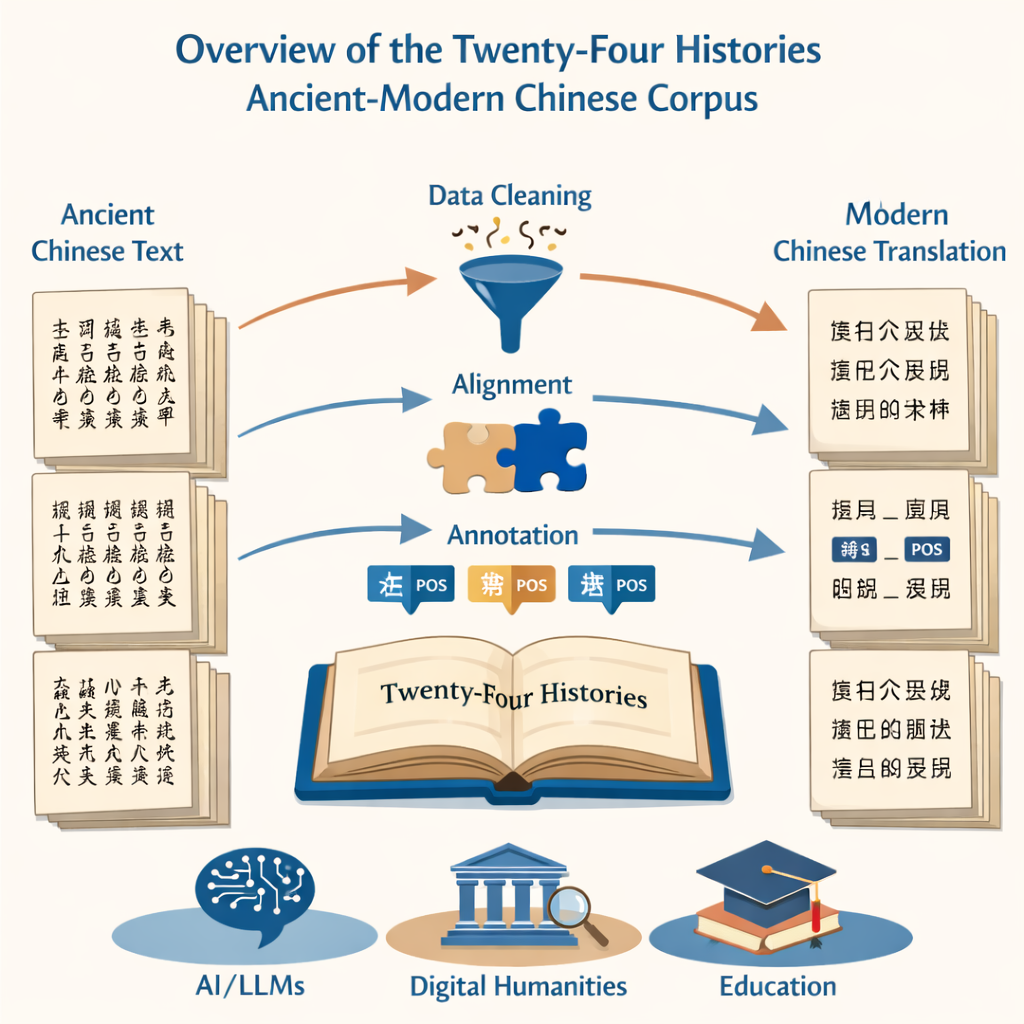
Appairer phrases anciennes et modernes
Parce que l’objectif était de comparer l’évolution de la langue au fil du temps, il était essentiel d’aligner les versions anciennes et modernes phrase par phrase. Les chercheurs ont utilisé un logiciel d’alignement spécialisé pour d’abord faire correspondre les paragraphes, puis les décomposer en phrases correspondantes. Les outils automatisés ont fait le gros du travail, mais des experts humains ont dû vérifier chaque paire proposée, car la grammaire du chinois ancien peut différer fortement du chinois moderne. Là où le logiciel a buté — en séparant une pensée au mauvais endroit ou en mal lisant un caractère — les annotateurs ont consulté les pages numérisées originales et corrigé le texte numérique afin que chaque phrase ancienne s’aligne proprement avec sa contrepartie moderne.
Apprendre à l’ordinateur à reconnaître la grammaire
Au-delà de la simple transcription, le cœur du projet est l’annotation grammaticale. Chaque mot, dans les textes anciens comme modernes, a été marqué d’une étiquette de partie du discours indiquant s’il s’agit, par exemple, d’un nom, d’un verbe ou d’un mot temporel. Faute d’un standard unique pour le chinois ancien, l’équipe a ancré son système sur les directives nationales modernes, puis les a adaptées aux usages anciens. Ils ont conçu un schéma de 22 étiquettes qui inclut un label spécial pour des emplois verbaux propres à l’ancien chinois, tels que « faire vivre » ou « mourir pour le pays ». Un réseau neuronal personnalisé — construit sur un modèle de langue pour textes anciens avec des couches de labellisation de séquences — a produit des étiquettes initiales, ensuite vérifiées et corrigées par une large équipe d’étudiants diplômés bien formés. Des tests stricts d’accord entre annotateurs ont montré une très grande cohérence, confirmant que le corpus étiqueté final est à la fois volumineux et fiable.
Ce que révèle le nouveau prisme
Grâce au corpus étiqueté, les auteurs ont examiné certains des motifs qu’il rend visibles. En chinois ancien, les mots monosyllabiques (à caractère unique) dominent, reflétant un style d’écriture notoirement compact, tandis que le chinois moderne privilégie les mots composés de deux caractères. Les éléments anciens les plus fréquents sont de petites particules grammaticales comme « 之 » et « 以 », tandis que verbes et noms ordinaires constituent ensemble environ la moitié de tous les mots dans les deux périodes. Les données montrent aussi quels mots ont tendance à apparaître ensemble — par exemple, des structures décrivant des officiers, des armées ou des missions diplomatiques. En comparant les étiquettes entre les paires ancien–moderne, l’équipe a retracé des évolutions fonctionnelles : certaines anciennes prépositions et adverbes correspondent aujourd’hui à des verbes modernes pleins, et certains verbes se sont figés en titres fixes ou en termes juridiques. Une étude de cas a extrait tous les noms de lieux et cartographié leurs concentrations selon les dynasties, révélant comment les centres politiques et économiques se sont déplacés du nord‑ouest vers le bas Yangzi et au-delà. 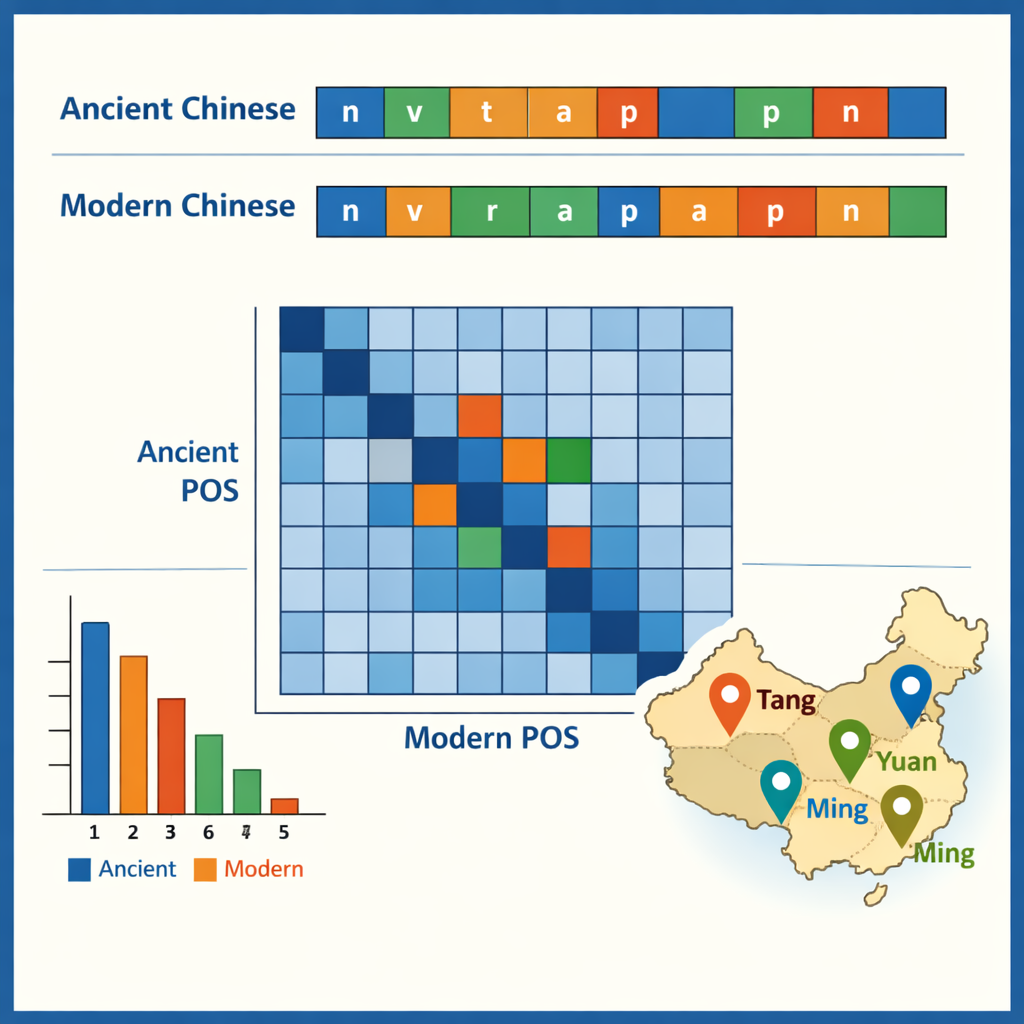
Faire entrer le passé dans l’avenir numérique
Concrètement, ce projet transforme un mur imposant de prose classique en données structurées que les humains et les machines peuvent parcourir. Pour les historiens et les linguistes, il fournit un outil puissant pour suivre comment les mots, la grammaire et même les frontières étatiques ont évolué au fil des siècles. Pour les développeurs d’IA, il offre du matériel d’entraînement de haute qualité pour construire des modèles de langue capables de traiter véritablement le chinois classique au lieu de le considérer comme un simple enchevêtrement de caractères. Et pour les étudiants et les lecteurs non spécialistes, l’appairage phrase par phrase des textes anciens et modernes abaisse la barrière à la lecture des classiques. En annotant et en alignant soigneusement les Vingt-Quatre Histoires, les auteurs ont créé un pont entre les rouleaux manuscrits du passé et les systèmes intelligents du présent et de l’avenir.
Citation: Ye, W., Xu, Q., Zhao, X. et al. Construction of the twenty-four histories ancient-modern part-of-speech tagged corpus. npj Herit. Sci. 14, 97 (2026). https://doi.org/10.1038/s40494-026-02309-w
Mots-clés: corpus chinois ancien, étiquetage morphosyntaxique, humanités numériques, textes parallèles, changement linguistique historique