Clear Sky Science · es
Evaluación sistemática y directrices para el modelo Segment Anything en el análisis de vídeo quirúrgico
Por qué importan las herramientas inteligentes de vídeo en el quirófano
La cirugía moderna se guía cada vez más por vídeo: pequeñas cámaras exploran el interior del cuerpo mientras los cirujanos manejan instrumentos delicados sobre una pantalla. Convertir esos vídeos ricos pero desordenados en mapas claros y etiquetados de herramientas y tejidos podría hacer las operaciones más seguras, el entrenamiento más eficaz y la futura asistencia robótica más fiable. Este estudio toma un poderoso sistema de visión de propósito general, entrenado originalmente con vídeos cotidianos, y plantea una pregunta simple pero importante: ¿puede “ver” lo suficiente dentro del cuerpo humano para ser útil en cirugía real —sin volver a entrenarse desde cero con costosos datos médicos?
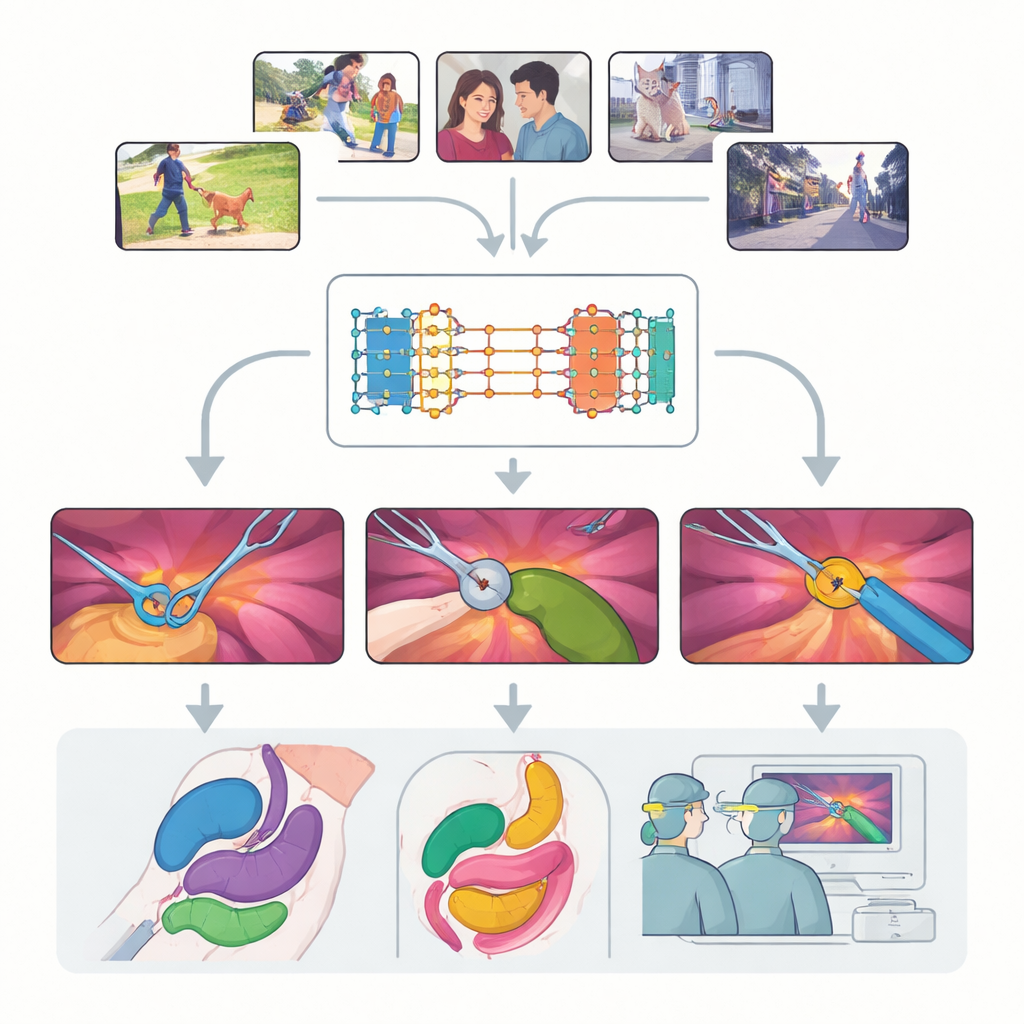
Una herramienta de visión flexible creada para cualquier escena
El trabajo se centra en el Segment Anything Model 2 (SAM2), un gran sistema de IA diseñado para identificar objetos en vídeos cuando se le da una pista, o “prompt”, sobre qué buscar. A diferencia de los modelos tradicionales que aprenden categorías fijas, SAM2 es independiente de clases: no le importa si un objeto es un perro, un coche o una pinza quirúrgica, siempre que el usuario lo señale con un punto, un cuadro o una máscara de ejemplo. Un avance clave en SAM2 es su banco de memoria, que recuerda cómo se veía un objeto en fotogramas anteriores y usa esa memoria para seguirlo a lo largo del tiempo. Esto hace que SAM2 resulte especialmente prometedor para el vídeo quirúrgico, donde los instrumentos entran y salen de la vista y los tejidos se deforman constantemente.
Poner el modelo a prueba a través de muchas cirugías
Los autores realizan una evaluación sistemática a gran escala de SAM2 en nueve conjuntos de datos diversos que cubren diecisiete tipos de procedimientos, desde colecistectomía laparoscópica hasta cirugía prostática robótica y endoscopia. Examinan tres desafíos principales: el seguimiento de instrumentos, la segmentación de múltiples órganos y la comprensión de escenas que mezclan herramientas y tejidos. Para cada uno, prueban diferentes formas de dar prompts al modelo —puntos únicos, varios puntos, cajas delimitadoras y máscaras completas— y exploran con qué frecuencia es necesario actualizar los prompts a medida que avanza el vídeo. También comparan el modelo fuera de la caja con varias maneras de reentrenarlo ligeramente con imágenes quirúrgicas para ver hasta dónde puede llegar el rendimiento sin necesitar conjuntos de datos nuevos y enormes.
Qué funciona mejor dentro del cuerpo
En general, SAM2 demuestra ser sorprendentemente robusto en este entorno poco familiar. Sin reentrenamiento quirúrgico, ya segmenta instrumentos y muchos órganos de forma competitiva frente a modelos médicos especializados, especialmente cuando se le proporcionan prompts ricos como cajas delimitadoras o máscaras. «Reinicializar» periódicamente los prompts cada 30 fotogramas —esencialmente recordando al sistema qué hay dónde— mejora mucho el seguimiento en clips largos y complejos. Cuando los investigadores afinan solo partes específicas de SAM2, como el módulo que convierte los prompts en máscaras, la precisión en escenas con múltiples órganos aumenta significativamente manteniendo moderadas las demandas de entrenamiento. En contraste, intentar ajustar por completo el codificador de imagen con datos quirúrgicos limitados puede perjudicar el rendimiento, lo que sugiere que la mayor parte del conocimiento visual general de SAM2 debería mantenerse intacto.
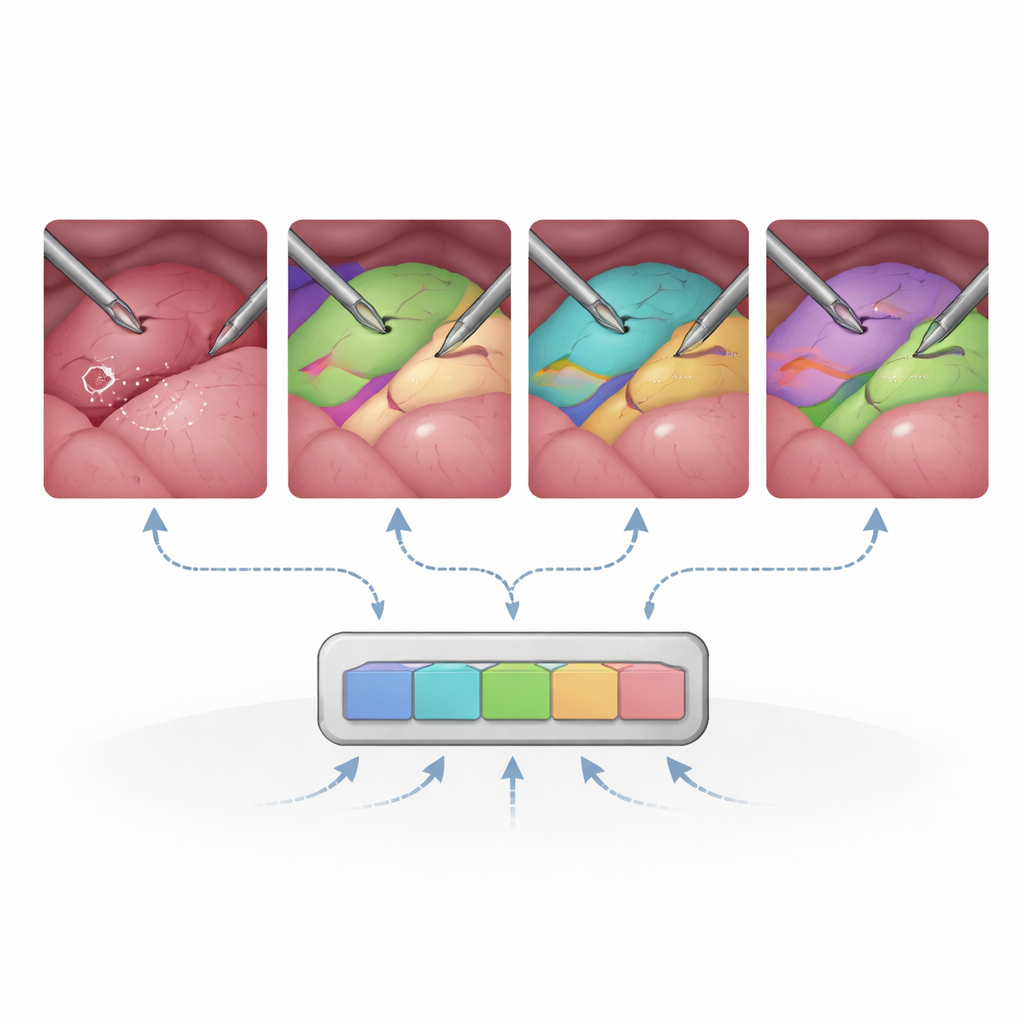
Límites en escenas desordenadas y de cambio rápido
El estudio también pone de manifiesto puntos débiles claros. SAM2 tiene dificultades cuando el campo de visión es estrecho, la imagen es ruidosa o está mal iluminada, o cuando los tejidos carecen de bordes nítidos, como en algunos procedimientos endoscópicos. Estructuras finas y ramificadas como vasos sanguíneos y conductos son difíciles de separar cuando se solapan o comparten un contorno aproximado. Usar la memoria de vídeo no siempre ayuda: en escenas muy dinámicas con movimiento rápido de la cámara, las señales temporales pueden inducir error al modelo en lugar de estabilizarlo. Estos hallazgos subrayan que, aunque un modelo fundamental general puede llegar lejos, algunas realidades quirúrgicas siguen requiriendo ajuste específico del dominio y mejor manejo del movimiento y de los cambios de apariencia.
Directrices para futuros sistemas inteligentes de cirugía
A partir de estas pruebas extensas, los autores extraen consejos prácticos para investigadores y clínicos que quieran usar SAM2 en proyectos quirúrgicos. Recomiendan empezar con prompts en forma de máscara o caja y un ajuste fino simple basado en imagen centrado en el decodificador de máscaras, añadir actualizaciones periódicas de los prompts para vídeos largos y explorar únicamente entrenamientos basados en vídeo más complejos cuando las escenas sean relativamente estables. Demuestran que incluso clips escasamente etiquetados —solo algunos fotogramas anotados— pueden ser suficientes para adaptar eficazmente el modelo. En términos claros, la conclusión es alentadora: un único modelo de visión entrenado de forma amplia puede abordar muchas tareas de segmentación quirúrgica, reduciendo drásticamente la necesidad de crear una herramienta nueva para cada procedimiento. Con un prompting cuidadoso y una ligera personalización, sistemas como SAM2 podrían convertirse en bloques de construcción potentes para la próxima generación de navegación, automatización y herramientas de formación quirúrgica.
Cita: Yuan, C., Jiang, J., Yang, K. et al. Systematic evaluation and guidelines for segment anything model in surgical video analysis. npj Digit. Surg. 1, 2 (2026). https://doi.org/10.1038/s44484-025-00002-2
Palabras clave: análisis de vídeo quirúrgico, segmentación de imagen, modelos fundamentales, cirugía asistida por ordenador, IA médica