Clear Sky Science · es
Espejo Mágico 3D: reconstrucción de ropa a partir de una sola imagen desde una perspectiva causal
Probar ropa sin vestuario
Imagínese hacer una sola foto de cuerpo entero con su móvil y verse al instante en 3D, poder girar la imagen, cambiar el punto de vista o incluso intercambiar prendas con un amigo. Este artículo aborda el problema técnico central detrás de ese “Espejo Mágico 3D”: convertir una fotografía 2D ordinaria de una persona vestida en un modelo 3D detallado de su ropa, sin depender de costosos escaneos 3D ni de fotos en estudio controladas.
Por qué convertir fotos 2D en 3D es tan complicado
Transformar una imagen plana en un objeto 3D es un rompecabezas clásico. Los sistemas actuales a menudo parten de una plantilla corporal digital fija y la deforman para que encaje con la imagen. Eso funciona razonablemente bien para partes rígidas del cuerpo como brazos y piernas, pero falla con vestidos fluidos, abrigos drapeados, pelo o bolsos, que no siguen una forma simple y estándar. Otro obstáculo es la disponibilidad de datos: hay millones de fotos de moda en la web, pero casi ninguna colección amplia de prendas 3D medidas con precisión para entrenar. Por último, una sola foto oculta información importante. Un abrigo pequeño cercano a la cámara puede parecer idéntico a uno más grande y lejano, y la iluminación o los patrones de la tela también pueden confundir a un algoritmo. Estas ambigüedades dificultan que una red neuronal “adivine” la estructura 3D correcta.
Enseñar a la IA a separar causa y efecto
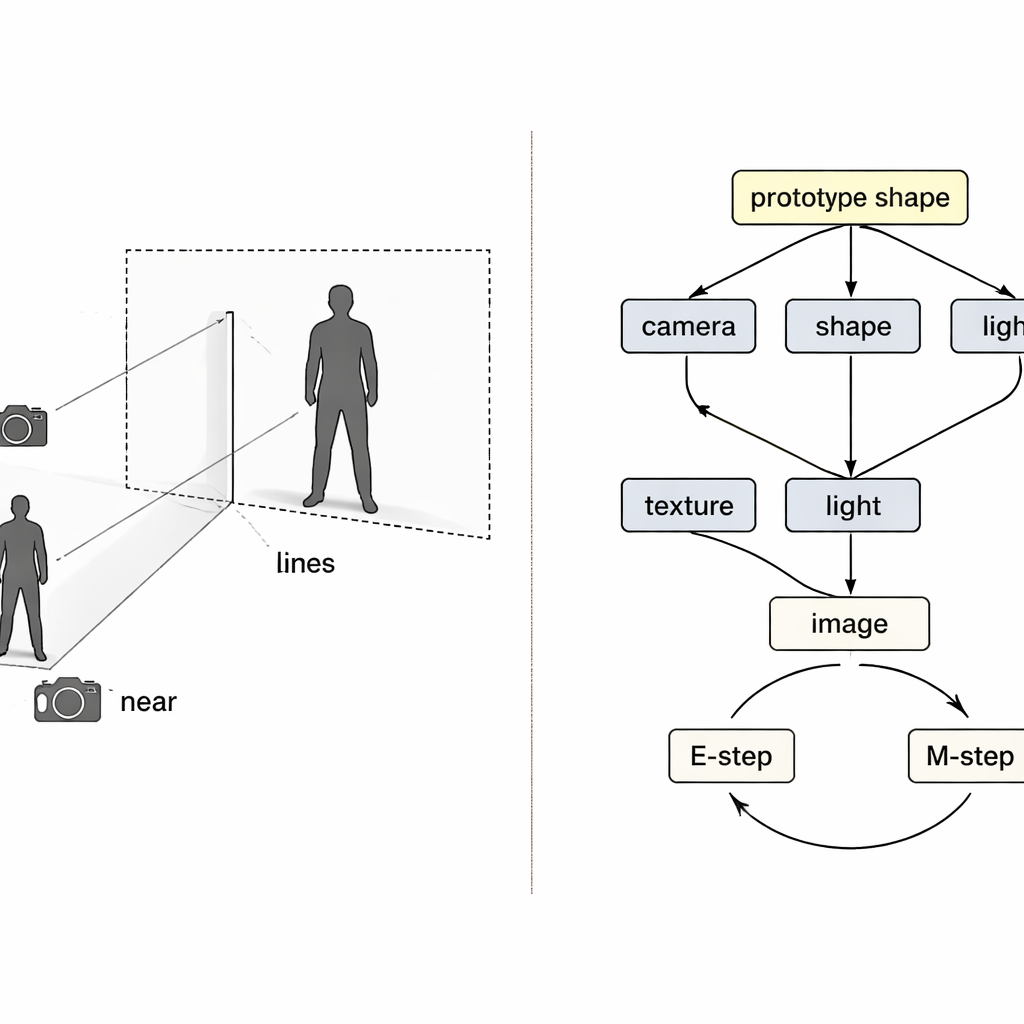
En lugar de tratar el problema como un mapeo de caja negra de píxeles a 3D, los autores toman ideas del razonamiento causal—las matemáticas de causa y efecto. Ven la imagen final como el resultado de cuatro causas ocultas: la posición de la cámara, la forma de la prenda, su textura (colores y patrones) y la iluminación. Un “mapa causal estructural” especial describe cómo estos factores se combinan para producir la imagen observada. Guiado por este mapa, el sistema usa cuatro codificadores neuronales separados, cada uno responsable de un factor. Junto con un renderizador 3D inspirado en la física, forman un bucle: entra la imagen y la máscara de primer plano, sale una malla 3D coloreada, que luego se proyecta de nuevo a una imagen que puede compararse con la original.
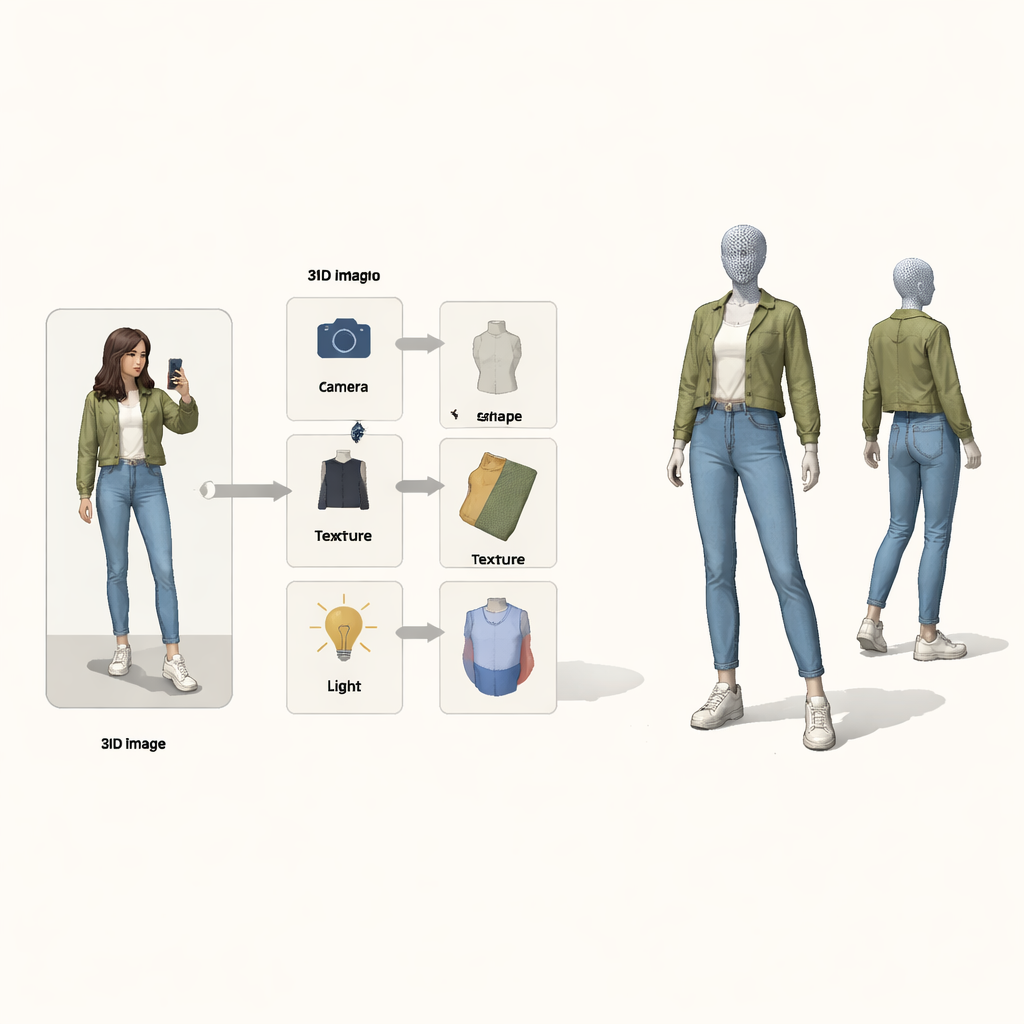
Un bucle de aprendizaje que corrige una cosa a la vez
Incluso con codificadores separados, el entrenamiento puede salir mal. Si la reconstrucción es imperfecta, no está claro qué codificador es el responsable, y el aprendizaje habitual tiende a ajustar todos a la vez. Los autores tratan esto como un problema clásico de “colisionador” en causalidad, donde distintas causas pueden compensarse indebidamente entre sí. Su solución es entrelazar dos bucles de expectativa–maximización durante el entrenamiento. En el primer bucle, tres codificadores se congelan temporalmente mientras se actualiza solo el cuarto, de modo que los errores se atribuyen con claridad y ese componente aprende un papel más limpio. En el segundo bucle, una «forma prototipo» 3D compartida—comenzando como una esfera simple—se actualiza lentamente para convertirse en la forma humana o de ave promedio en los datos. Los ejemplos individuales aprenden solo pequeñas desviaciones respecto a este prototipo, mientras que el módulo de cámara asume plena responsabilidad de cómo de grande o cercano aparece el objeto, abordando directamente la confusión tamaño-versus-distancia.
De fotos de moda a aves, y más allá
Para evaluar su enfoque, los investigadores entrenan con dos grandes conjuntos de datos de moda que contienen fotos callejeras ordinarias y con una colección estándar de imágenes de aves. Es importante que usan solo máscaras de primer plano 2D, no mallas 3D de referencia. En ropa humana, su sistema supera a los métodos basados en plantillas corporales populares al ajustar mejor el contorno verdadero de las prendas y maneja elementos no rígidos como pelo y bolsos con mayor fidelidad. En aves, alcanza o supera la calidad de los principales métodos de reconstrucción 3D a partir de una sola imagen, al tiempo que produce vistas nuevas más realistas. Los modelos 3D son lo bastante flexibles para soportar aplicaciones lúdicas, como intercambiar texturas de ropa entre personas o generar datos sintéticos de entrenamiento para mejorar sistemas de reidentificación de personas usados en investigación de vigilancia.
Qué significa esto para los mundos digitales cotidianos
Para no especialistas, el mensaje clave es que avatares 3D convincentes y herramientas de probador virtual ya no requieren escáneres 3D costosos ni plantillas rígidas. Al modelar explícitamente causa y efecto—separando cámara, forma, textura y luz, y anclándolos a un prototipo compartido—los autores muestran cómo un sistema puede “explicar” una sola foto como una escena 3D. Aunque el método aún tiene dificultades con vistas que nunca ha visto, como la espalda de una persona fotografiada solo de frente, supone un avance importante hacia Espejos Mágicos 3D prácticos que funcionen con las imágenes desordenadas y tomadas en libertad que realmente hacemos.
Cita: Zheng, Z., Zhu, J., Ji, W. et al. 3D Magic Mirror: clothing reconstruction from a single image via a causal perspective. npj Artif. Intell. 2, 29 (2026). https://doi.org/10.1038/s44387-026-00082-6
Palabras clave: probador virtual, reconstrucción 3D, aprendizaje causal, visión por ordenador, IA de moda