Clear Sky Science · es
El papel de los grandes modelos de lenguaje en la atención de urgencias: un estudio exhaustivo de evaluación comparativa
Por qué esto importa para cualquiera que pueda visitar urgencias
Los servicios de urgencias están más concurridos que nunca, con esperas más largas y menos personal para atender a un número creciente de pacientes críticamente enfermos. Este estudio plantea una pregunta que afecta a casi todo el mundo: ¿pueden los sistemas de IA modernos, conocidos como grandes modelos de lenguaje, ayudar de forma segura a médicos y enfermeras a trabajar más rápido e inteligentemente en el servicio de urgencias? Al someter a varios de los principales sistemas de IA a una serie de pruebas médicas y casos simulados de urgencias, los investigadores exploran qué tan cerca están estas herramientas de convertirse en «copilotos» fiables en la atención urgente.
Servicios de urgencias bajo intensa presión
El artículo comienza describiendo una crisis creciente en la atención de urgencias, especialmente en Estados Unidos. Una población que envejece y un aumento de las enfermedades crónicas están impulsando cifras récord de visitas a urgencias, que superaron aproximadamente los 155 millones solo en 2022. Al mismo tiempo, los hospitales afrontan graves carencias de enfermeras y médicos, y el número de camas por persona ha disminuido en las últimas décadas. Un sistema de salud fragmentado dificulta la coordinación de la atención, aumentando el riesgo de retrasos y errores. Frente a este panorama, los autores sostienen que se necesitan con urgencia nuevas herramientas que ayuden a los clínicos a hacer el triaje de pacientes, tomar decisiones rápidas y documentar la atención sin añadir carga de trabajo.
Cómo evaluaron los investigadores la IA médica
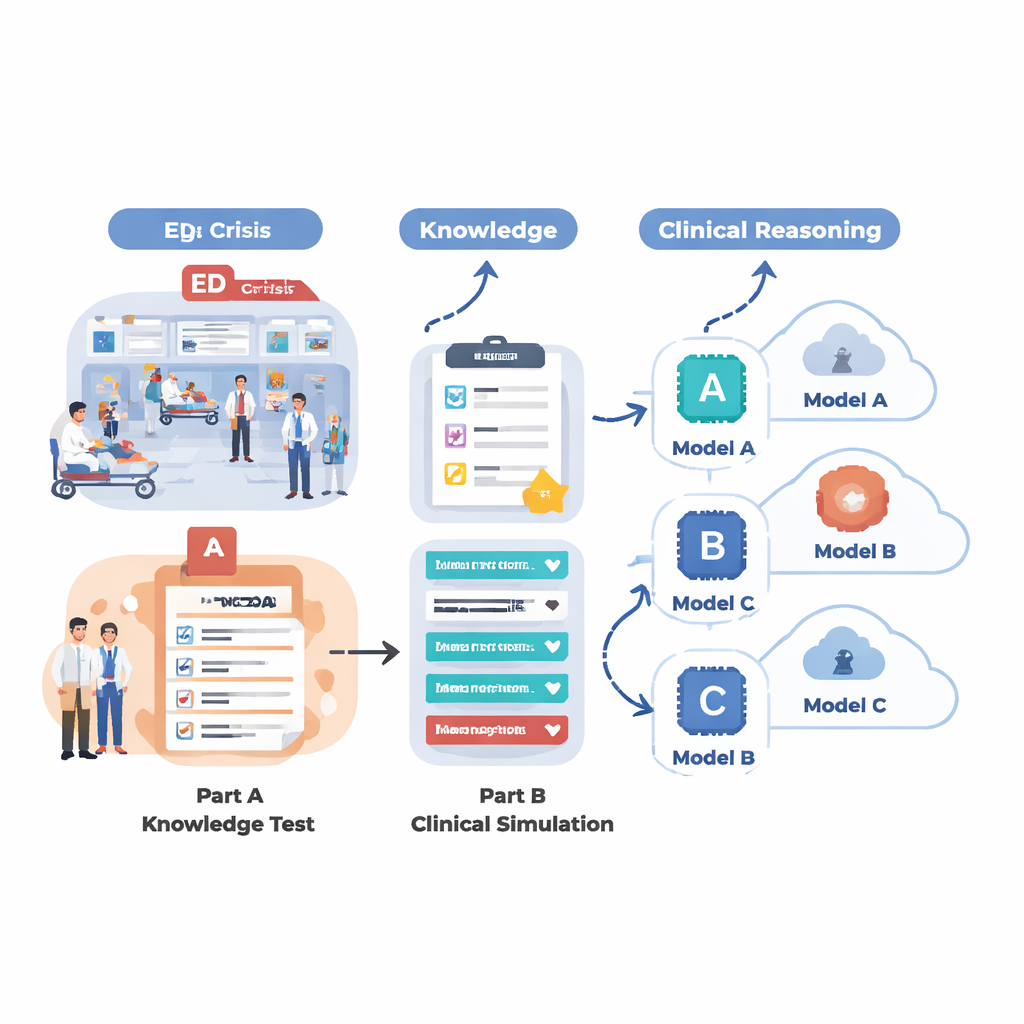
Para ver qué pueden realmente hacer los sistemas de IA actuales en un entorno similar a urgencias, el equipo diseñó una evaluación en dos partes. Primero, probaron 18 modelos de lenguaje diferentes con un amplio conjunto de preguntas de opción múltiple extraídas de MedMCQA, un conjunto de datos tipo examen médico que abarca 12 motivos de consulta comunes en urgencias, como dolor torácico, dificultad respiratoria, cefalea y dolor abdominal. Esta fase midió el conocimiento médico básico: ¿podía la IA escoger la respuesta correcta entre cuatro opciones a lo largo de miles de preguntas? Segundo, seleccionaron los cinco modelos más fuertes de esa ronda y les pidieron que resolvieran 12 casos realistas de urgencias, paso a paso, tal como lo haría un médico. Para cada caso, la IA tuvo que resumir al paciente, asignar una puntuación de urgencia de triaje, sugerir preguntas de seguimiento clave, proponer pasos de manejo y listar diagnósticos probables a medida que se revelaba nueva información (signos vitales, antecedentes, hallazgos del examen, resultados de laboratorio e imágenes).
Qué modelos de IA conocían los hechos—y cuáles sabían razonar
En la recuperación puramente factual, varios modelos obtuvieron un rendimiento impresionante. Un sistema especializado llamado LLaMA 4 Maverick alcanzó aproximadamente un 91 por ciento de precisión global en las preguntas médicas, seguido de cerca por LLaMA 3.1, GPT-4.5, GPT-5 y Claude 4. Estos modelos de primera línea fueron consistentemente fuertes entre distintos motivos de consulta, lo que sugiere que las IAs de vanguardia pueden estar acercándose a un techo en el conocimiento médico de tipo bibliográfico. Los sistemas de gama media quedaron bastante rezagados, con algunos rondando el 60 por ciento y con dificultades en áreas clave como el cuidado de heridas y problemas respiratorios. Sin embargo, cuando la tarea cambió de responder preguntas aisladas a razonar sobre historias clínicas ricas y en evolución, las diferencias se hicieron más marcadas. En estas simulaciones clínicas, GPT-5 destacó claramente: produjo los resúmenes más precisos y completos, formuló las preguntas de seguimiento más útiles, recomendó pasos siguientes sensatos y seguros, y ofreció las listas de diagnósticos posibles más exhaustivas y bien ordenadas.
Puntos fuertes, debilidades y preocupaciones de seguridad
Los clínicos evaluaron cuidadosamente la salida de cada IA en términos de precisión, relevancia y seguridad. GPT-5 no solo obtuvo las puntuaciones más altas en conjunto; además fue el único modelo cuyo rendimiento se mantuvo estable o mejoró a medida que los casos se volvían más complejos, manteniendo al mismo tiempo las alucinaciones y errores graves por debajo de aproximadamente el 2 por ciento. Otros modelos mostraron patrones distintivos de debilidad. Algunos tendían a pasar por alto diagnósticos secundarios o a priorizar problemas menores por delante de los peligrosos. Otros se volvieron excesivamente cautelosos o vagos, o se fijaron demasiado pronto en un único diagnóstico. En general, la mayoría de los sistemas subestimó la gravedad de los pacientes al asignar niveles de triaje, un sesgo conservador que podría retrasar la atención urgente si no se corrige. Los hallazgos subrayan un punto clave: saber hechos médicos no es lo mismo que entrelazar esos hechos de forma fiable en decisiones seguras y paso a paso cuando la información es incompleta, desordenada y cambiante.

Qué podría significar esto para futuras visitas a urgencias
Los autores concluyen que, si bien varias IAs modernas ya se igualan entre sí en conocimiento médico, GPT-5 en particular muestra un nuevo nivel de habilidad para razonar que podría hacerlo útil como herramienta de soporte a la decisión en los servicios de urgencias. Insisten en que estos sistemas no están listos para reemplazar a los clínicos ni actuar por sí solos. En cambio, el papel más prometedor a corto plazo es el de asistente supervisado: ayudar a las enfermeras de triaje a estimar la urgencia, redactar resúmenes del paciente, sugerir preguntas o pruebas y verificar si se han considerado diagnósticos graves. El estudio también subraya que se necesita más investigación en entornos clínicos reales, con rigurosos controles de seguridad y reglas claras de uso. Para los pacientes, el mensaje es de optimismo cauteloso: la IA está mejorando en el razonamiento sobre problemas médicos, pero su uso seguro en urgencias dependerá del diseño cuidadoso, la supervisión y un enfoque continuo en apoyar—no sustituir—el juicio humano de médicos y enfermeras.
Cita: Naderi, B., Liu, L., Ghandehari, A. et al. The role of large language models in emergency care: a comprehensive benchmarking study. npj Artif. Intell. 2, 24 (2026). https://doi.org/10.1038/s44387-026-00078-2
Palabras clave: medicina de urgencias, grandes modelos de lenguaje, soporte a la decisión clínica, triaje, evaluación comparativa de IA médica