Clear Sky Science · es
Corregir errores aritméticos de multiplicación-acumulación en procesamiento-en-memoria con LDPC
Por qué importa corregir errores matemáticos en memoria
Los chips de inteligencia artificial modernos extraen más velocidad y eficiencia del hardware realizando cálculos directamente dentro de la memoria, en lugar de mover constantemente los datos hacia y desde procesadores separados. Este enfoque de “procesamiento-en-memoria” ahorra energía pero introduce un problema serio: pequeñas imperfecciones eléctricas pueden invertir bits almacenados o distorsionar señales analógicas, degradando de forma silenciosa la precisión de tareas como el reconocimiento de imágenes. El artículo describe una nueva forma de detectar y corregir automáticamente estos errores en tiempo real, ayudando a que el hardware de IA futuro sea tanto rápido como fiable.
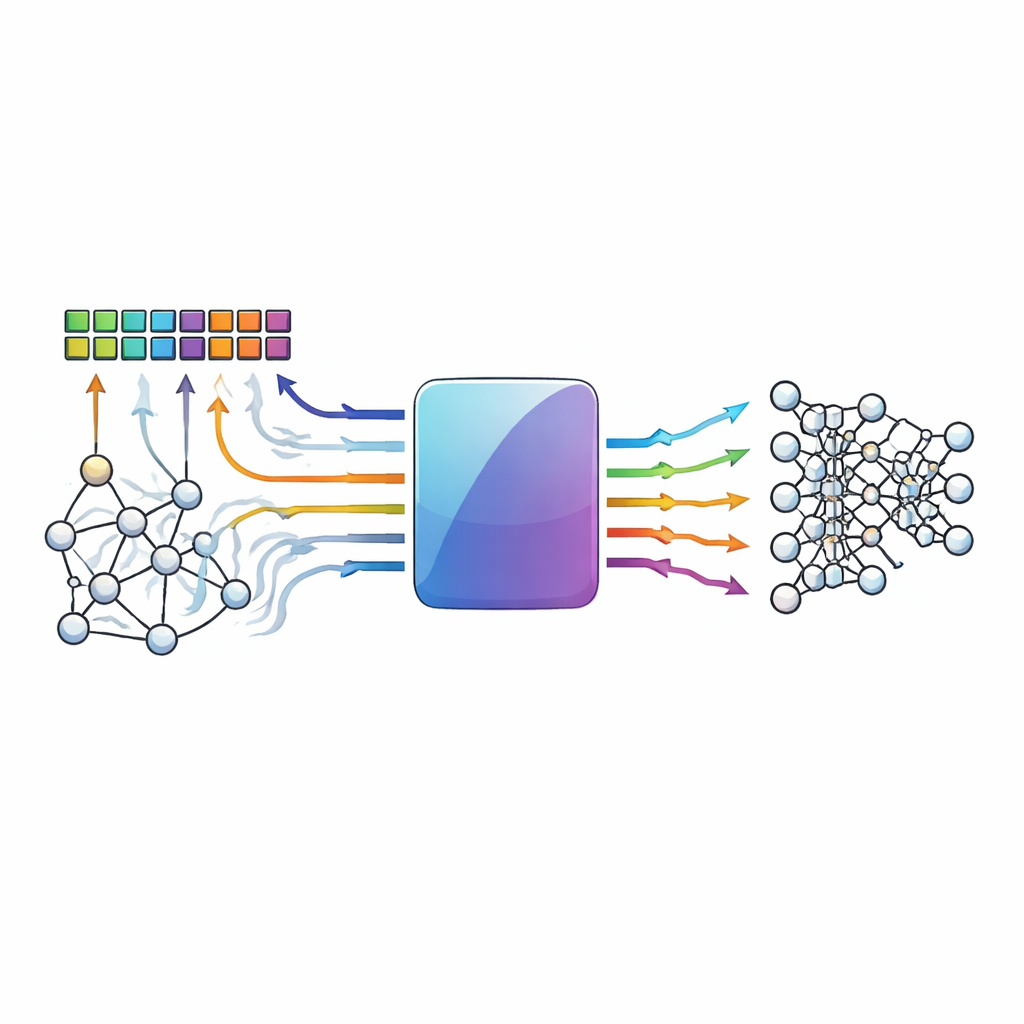
Calcular donde viven los datos
Los ordenadores convencionales se ven ralentizados por la necesidad de mover datos entre la memoria y el procesador. Los diseños de procesamiento-en-memoria evitan este cuello de botella realizando operaciones de multiplicación y acumulación —la columna vertebral de las redes neuronales— dentro de densos arreglos de celdas de memoria. Dispositivos emergentes como la RAM resistiva y otros elementos memristivos son especialmente atractivos porque pueden almacenar muchos valores y realizar aritmética de estilo analógico de forma muy eficiente. Sin embargo, la misma naturaleza analógica y la variabilidad de los dispositivos que los hace potentes también los hace ruidosos: las fluctuaciones térmicas, las desajustes entre dispositivos y las caídas de tensión pueden desvi ar valores almacenados o resultados calculados de donde deberían estar.
Cuando pequeñas fallas se acumulan
En estos arreglos en memoria, se activan muchas filas de celdas a la vez y sus contribuciones se suman a lo largo de cables compartidos. A medida que participan más filas, sus imperfecciones individuales se acumulan, creando patrones de error que son a la vez frecuentes y complejos. En lugar de un único bit equivocado, los diseñadores observan a menudo múltiples errores agrupados en la misma columna de una matriz o distribuidos a través de varias columnas de una manera que derrota los trucos tradicionales de corrección de errores. Los códigos estándar suelen asumir patrones de error simples y longitudes de palabra cortas; pueden pasar por alto fallos multi-bit o no tener entradas en sus tablas de consulta para combinaciones raras pero dañinas. Como resultado, la precisión de los modelos de redes neuronales profundas puede caer drásticamente una vez que el hardware subyacente se vuelve siquiera moderadamente poco fiable.
Una nueva especie de red de seguridad digital
Los autores presentan un código de paridad de baja densidad no binario (NB-LDPC) diseñado específicamente para hardware de procesamiento-en-memoria. En lugar de trabajar solo con ceros y unos, su esquema opera sobre pequeños grupos de bits tratados como símbolos en una estructura matemática llamada campo finito construido a partir de un número primo (aquí, tres). Esto permite que el mismo código proteja tanto el almacenamiento binario ordinario como las codificaciones multinivel o diferenciales usadas habitualmente en aceleradores analógicos. El sistema añade un número modesto de símbolos extra —símbolos de comprobación— a cada bloque de datos. Durante tanto las lecturas normales de memoria como las operaciones de multiplicación-acumulación en memoria, el hardware calcula los resultados para los datos y los símbolos de comprobación juntos, de modo que la detección de errores queda naturalmente entretejida en la computación.
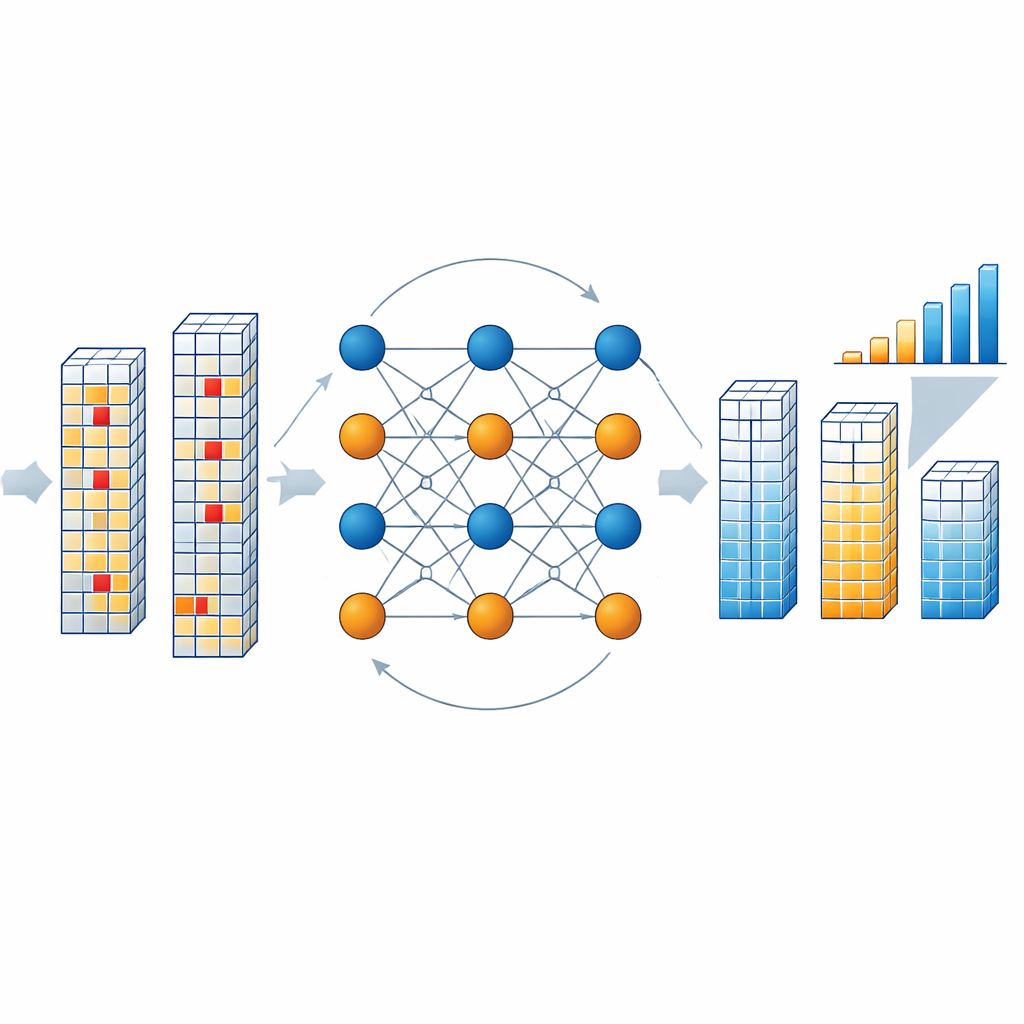
Cómo funciona el motor de corrección dentro del chip
Cuando el chip lee un bloque de resultados, un decodificador dedicado examina si los símbolos combinados de datos y comprobación cumplen las relaciones de paridad definidas por el código. Si lo hacen, se asume que el bloque está limpio. Si no, el decodificador lanza un proceso iterativo en el que abstracciones llamadas “nodos de variable” que representan cada símbolo y “nodos de comprobación” que representan condiciones de paridad intercambian mensajes de probabilidad. Estos mensajes estiman cuán probable es que cada símbolo adopte cada uno de los valores permitidos, basándose en las salidas observadas y la tasa esperada de inversión de bits de la memoria. Los autores simplifican este razonamiento matemático usando aproximaciones de distancia Manhattan, lo que reduce en gran medida el coste hardware manteniendo un alto rendimiento. Tras unas pocas rondas —típicamente tres— el decodificador converge en la versión corregida más plausible del vector de resultados, sin necesidad de volver a leer la memoria ni detener la corriente de cálculo.
Prueba en silicio e impacto en la precisión de la IA
Para probar la idea en la práctica, el equipo construyó un chip prototipo en un proceso de 40 nanómetros que combina un arreglo de RAM resistiva, convertidores analógico-digitales ligeros y el nuevo decodificador NB-LDPC. Con una configuración que protege 256 símbolos de información usando 32 símbolos de comprobación, el decodificador alcanza una alta tasa de código (alrededor de 0,8), una eficiencia energética medida máxima de aproximadamente 88 terabits de datos corregidos por segundo por vatio, y una sobrecarga de área modesta que puede reducirse más compartiendo un decodificador entre varios macros de memoria. Simulaciones con muchos tamaños de código muestran que, al proteger 1024 símbolos de datos con 128 símbolos de comprobación, el esquema puede mejorar la tasa de error de bit casi 60 veces. Aplicado a un modelo de clasificación de imágenes ResNet-34 ejecutado en hardware de procesamiento-en-memoria, la corrección restaura más de 20 puntos porcentuales de precisión perdidos bajo condiciones de error desafiantes.
Qué significa esto para los chips de IA del futuro
En términos sencillos, el trabajo proporciona al hardware de procesamiento-en-memoria un “corrector ortográfico” robusto para sus operaciones matemáticas, uno que entiende conjuntos de símbolos más ricos y patrones de error complejos sin ralentizar el flujo de datos. Al unificar la protección tanto para los datos almacenados como para los cálculos en tiempo real, y demostrando una implementación eficiente en silicio, el estudio muestra que los aceleradores en memoria de alta densidad y bajo consumo no tienen que sacrificar la fiabilidad. Este tipo de corrección de errores a medida podría convertirse en un ingrediente clave para que los aceleradores neuromórficos y de IA futuros sean a la vez eficientes en energía y lo bastante fiables para aplicaciones del mundo real, desde dispositivos móviles hasta centros de datos a gran escala.
Cita: Shi, D., Fu, Y., Zhu, Y. et al. Correcting processing-in-memory multiply-accumulate arithmetic errors with LDPC. npj Unconv. Comput. 3, 14 (2026). https://doi.org/10.1038/s44335-026-00061-9
Palabras clave: procesamiento-en-memoria, corrección de errores, códigos LDPC, RAM resistiva, hardware de redes neuronales