Clear Sky Science · es
LIMO: aplanador en memoria de bajo consumo y primitiva de multiplicación de matrices para computación en el extremo
Rutas más inteligentes y chips más esbeltos
Cada día, las empresas afrontan rompecabezas como hallar la ruta más corta para un camión de reparto con miles de paradas o escanear rápidamente imágenes para detectar rostros con una cámara alimentada por batería. Estos problemas sobrecargan los ordenadores actuales, que mueven enormes cantidades de datos entre la memoria y los procesadores. Este artículo presenta LIMO, un nuevo tipo de bloque de computación de bajo consumo que mantiene los datos en su lugar mientras resuelve tareas difíciles de planificación de rutas y ejecuta modelos de inteligencia artificial (IA), haciendo que los futuros dispositivos en el borde sean más rápidos y eficientes energéticamente.
Por qué es tan difícil encontrar buenas rutas
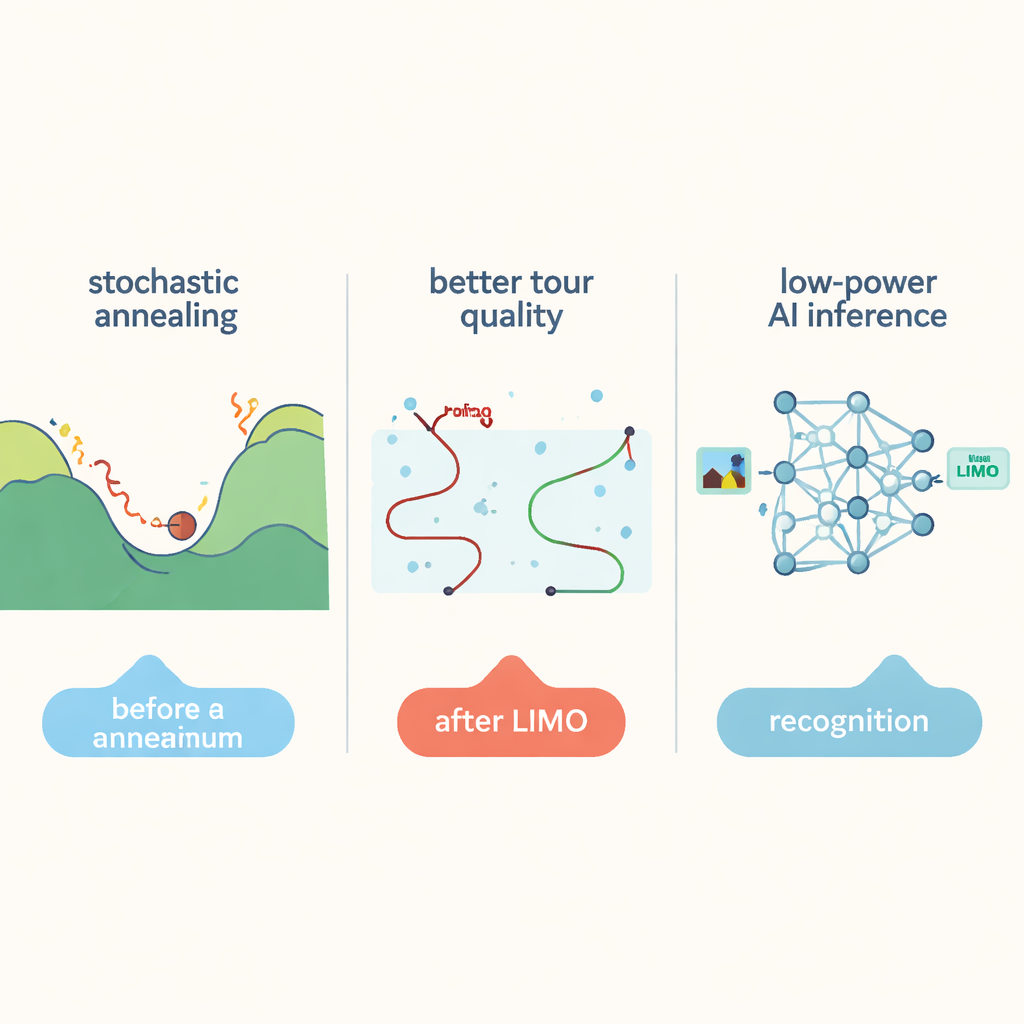
En el centro de este trabajo está el famoso Problema del Viajante: dado un conjunto de ciudades, encontrar el circuito más corto que visite cada ciudad una vez y vuelva al inicio. Para mapas pequeños, las herramientas matemáticas exactas pueden hallar la mejor solución. Pero cuando el número de ciudades crece hasta decenas de miles, las posibles rutas se disparan y hasta los ordenadores potentes se atascan. Heurísticas como el anelado simulado pueden explorar este vasto espacio en busca de recorridos buenos, aunque no óptimos, aceptando ocasionalmente soluciones intermedias peores para evitar quedarse atrapadas. Sin embargo, los enfoques estándar siguen explorando el espacio de búsqueda de forma ineficiente para problemas muy grandes y desperdician tiempo moviendo datos entre memoria y CPU, chocando contra la llamada «pared de memoria».
Una nueva forma de buscar las posibilidades
Los autores proponen un nuevo algoritmo llamado Inserción Anealada Ponderada por Significación (Significance Weighted Annealed Insertion, SWAI) que redefine cómo se exploran las rutas candidatas. En lugar de intercambiar constantemente pares de ciudades, lo que escala mal cuando crece el número de ciudades, SWAI construye los recorridos paso a paso, insertando una ciudad nueva a la vez. En cada paso, a veces elige la ciudad siguiente más cercana (una elección voraz) y otras veces recurre a aleatoriedad controlada que favorece aristas candidatas más cortas sin excluir por completo las más largas. Este sesgo se ajusta con el tiempo, empezando más aventurero y volviéndose más conservador a medida que avanza la búsqueda. Como cada paso examina opciones de un modo que crece solo linealmente con el número de ciudades, el algoritmo explora mejoras a largo alcance de forma más eficaz que el anelado simulado tradicional.
Computación dentro de la memoria con aleatoriedad integrada
LIMO transforma este algoritmo en hardware mediante un diseño conjunto estrecho del circuito y del método de búsqueda. En su núcleo hay una matriz de memoria modificada que almacena tanto el recorrido actual como las distancias entre ciudades, y realiza los pasos clave de actualización sin comunicarse constantemente con un procesador separado. Las elecciones aleatorias necesarias para el algoritmo provienen de diminutos dispositivos magnéticos llamados uniones túnel magnéticas por transferencia de momento (spin-transfer-torque magnetic tunnel junctions), que tienden a cambiar de estado de forma impredecible cuando se los impulsa con la corriente adecuada. Los diseñadores convierten esa aleatoriedad física en bits digitales y usan comparaciones simples para implementar las decisiones probabilísticas del algoritmo. Debido a que la mayoría de las operaciones permanecen en digital y ocurren directamente dentro de la memoria, el sistema evita convertidores voluminosos y circuitos analógicos frágiles, ahorrando tanto energía como área.
Dividir los grandes problemas en piezas
Para abordar tareas de planificación de rutas realmente grandes, con hasta 85.900 ciudades, el sistema emplea una estrategia de dividir y conquistar. Un método geométrico ligero agrupa ciudades próximas en clústeres hasta que cada clúster es lo bastante pequeño para caber en un único bloque LIMO. El hardware resuelve muchas de estas subrutas en paralelo y luego las ensambla de nuevo en un recorrido completo. Pasos adicionales de refinamiento pulen aún más la ruta global: segmentos del recorrido se reoptimizan por el hardware, y una limpieza clásica «2-opt» en un procesador convencional elimina los cruces restantes. En pruebas con puntos de referencia estándar, este enfoque combinado produjo recorridos de mayor calidad que máquinas de anelado especializadas anteriores, alcanzando respuestas hasta unas cinco veces más rápido en el problema de mayor tamaño.
De rutas difíciles a IA eficiente
LIMO no se limita a la planificación de rutas. La misma matriz de memoria también puede actuar como un bloque constructivo para redes neuronales realizando multiplicaciones vector–matriz, la operación central detrás del reconocimiento de imágenes y patrones. En lugar de usar convertidores precisos y consumidores de energía para leer señales analógicas, LIMO se apoya en circuitos de detección muy simples que capturan solo el signo de la señal acumulada, y compensa esa crudeza entrenando las redes de forma consciente del hardware. En tareas de clasificación de imágenes y detección facial, estas redes alcanzaron una precisión cercana a la de los modelos de software estándar, reduciendo al mismo tiempo el consumo energético y el tiempo de respuesta en comparación con chips convencionales de computación-en-memoria. Para el usuario cotidiano, esto significa que cámaras, drones y otros dispositivos periféricos podrían algún día resolver tareas complejas de planificación y ejecutar modelos de IA más tiempo con una batería, todo gracias a una búsqueda y computación más inteligentes directamente donde residen los datos.
Cita: Holla, A., Chatterjee, S., Sen, S. et al. LIMO: Low-power in-memory-annealer and matrix-multiplication primitive for edge computing. npj Unconv. Comput. 3, 10 (2026). https://doi.org/10.1038/s44335-026-00054-8
Palabras clave: computación en memoria, problema del viajante, anelado por hardware, IA de bajo consumo, computación en el borde