Clear Sky Science · es
Una evaluación de la incertidumbre estimativa en modelos de lenguaje a gran escala
Por qué las palabras imprecisas sobre el riesgo importan de verdad
Cuando un médico dice que un tratamiento es “probable” que funcione, o un meteorólogo advierte que hay “pocas probabilidades” de un huracán, confiamos en esas palabras imprecisas para tomar decisiones reales. Hoy, los modelos de lenguaje a gran escala (LLM), como los chatbots en línea, empiezan a emplear el mismo vocabulario. Este estudio plantea una pregunta simple pero crucial: cuando una IA dice “probablemente”, ¿significa lo mismo que para nosotros—y puede convertir de forma fiable números en palabras cotidianas de incertidumbre?
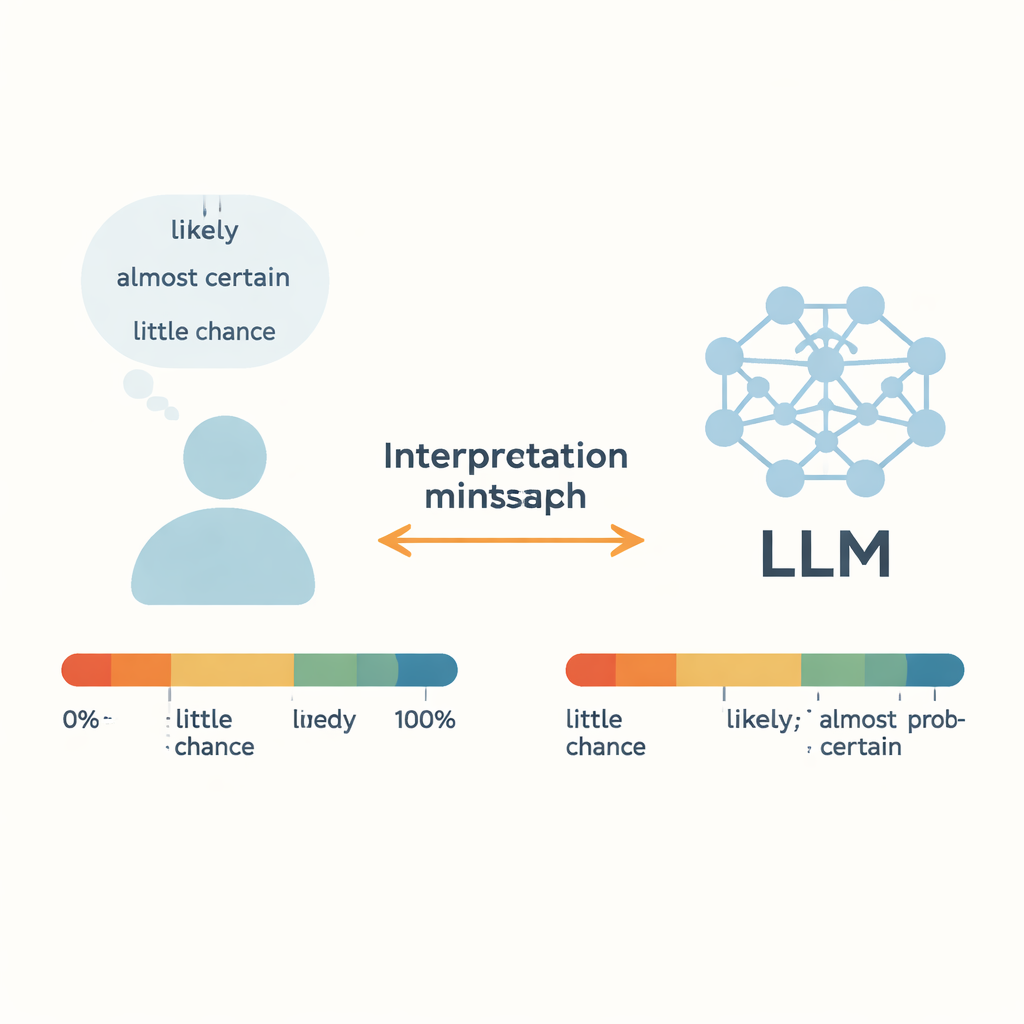
Poniendo la incertidumbre cotidiana bajo el microscopio
Los autores se centran en las “Palabras de Probabilidad Estimativa” (WEP, por sus siglas en inglés): términos como “casi seguro”, “probable” y “pocas probabilidades” que la gente usa en lugar de porcentajes exactos. Trabajos anteriores, que datan de los analistas de inteligencia en los años sesenta, intentaron vincular estas palabras con probabilidades numéricas mediante encuestas. Este estudio compara esos juicios humanos con la salida de cinco LLM modernos, incluidos GPT-3.5, GPT-4, los modelos Llama de Meta y un sistema chino llamado ERNIE-4.0. Para 17 palabras de incertidumbre comunes, a cada modelo se le dieron indicaciones breves tipo historia en inglés o chino y se le pidió responder con una probabilidad numérica entre 0 y 100 por ciento. Repitiendo esto en muchos contextos, los autores construyeron distribuciones de probabilidad completas para cada palabra y cada modelo, y luego las compararon con datos de encuestas humanas.
Donde humanos y IAs hablan el mismo idioma
Para las expresiones más extremas—como “casi seguro” en el extremo alto y “casi sin probabilidad” en el extremo bajo—los LLM y los humanos se alinean sorprendentemente bien. Tanto las personas como los modelos tienden a agrupar estas frases dentro de rangos estrechos de alta o baja probabilidad, lo que sugiere que estos términos contundentes tienen significados relativamente estables según el contexto. Lo mismo ocurre con “más o menos 50/50”, que la mayoría de los humanos y los modelos tratan como aproximadamente una probabilidad del 50 %. Las pruebas estadísticas muestran pocas diferencias significativas entre las distribuciones humanas y las de los modelos para estas palabras concretas, lo que implica que los LLM pueden captar casos claros de casi certeza o casi imposibilidad con una precisión semejante a la humana.
Donde los significados se separan en silencio
Las palabras ambiguas y de tono intermedio cuentan otra historia. Para expresiones como “probable”, “probable”, “dudamos” y “pocas probabilidades”, las interpretaciones numéricas de los modelos difieren significativamente de los juicios humanos. GPT-4, a pesar de ser más capaz en general que GPT-3.5, a menudo muestra brechas mayores. Los autores sugieren que esto puede deberse a que tales palabras mezclan dos cosas: una sensación de probabilidad y la actitud o postura del hablante. En conversaciones reales, “probable” puede sonar cauto o confiado según el tono y el contexto, y “dudamos” puede expresar escepticismo más que una probabilidad precisa. Entrenados con grandes textos de géneros mixtos de Internet, los LLM pueden promediar sobre muchos usos conflictivos, difuminando estas sutilezas. El resultado es una descoincidencia oculta: humanos y máquinas pueden ver la misma frase y asignarle en silencio números distintos a la misma palabra.
Género, idioma y ecos culturales
Los investigadores también probaron cómo el lenguaje con matices de género y los distintos idiomas moldean estas palabras de probabilidad. Cuando las indicaciones se referían a “él” o “ella” en lugar de sujetos neutrales en cuanto al género, GPT-3.5 y GPT-4 a menudo produjeron estimaciones de probabilidad menos variables, más “cerradas”, a veces colapsando hasta un único valor. Esto sugiere que los modelos pueden haber absorbido patrones rígidos procedentes de estereotipos en sus datos de entrenamiento, aunque los promedios generales para indicaciones masculinas y femeninas fueran similares. Al comparar indicaciones en inglés y en chino, los modelos GPT mostraron desplazamientos notables en cómo interpretaban las mismas palabras de incertidumbre. ERNIE-4.0, entrenado principalmente en texto chino, se acercó más a los hablantes chinos en muchos términos pero aun así sobrestimó o subestimó ciertas frases. Estos hallazgos muestran que la manera en que una IA habla sobre la incertidumbre depende no solo de la palabra elegida, sino del idioma y los patrones culturales incorporados en su entrenamiento.
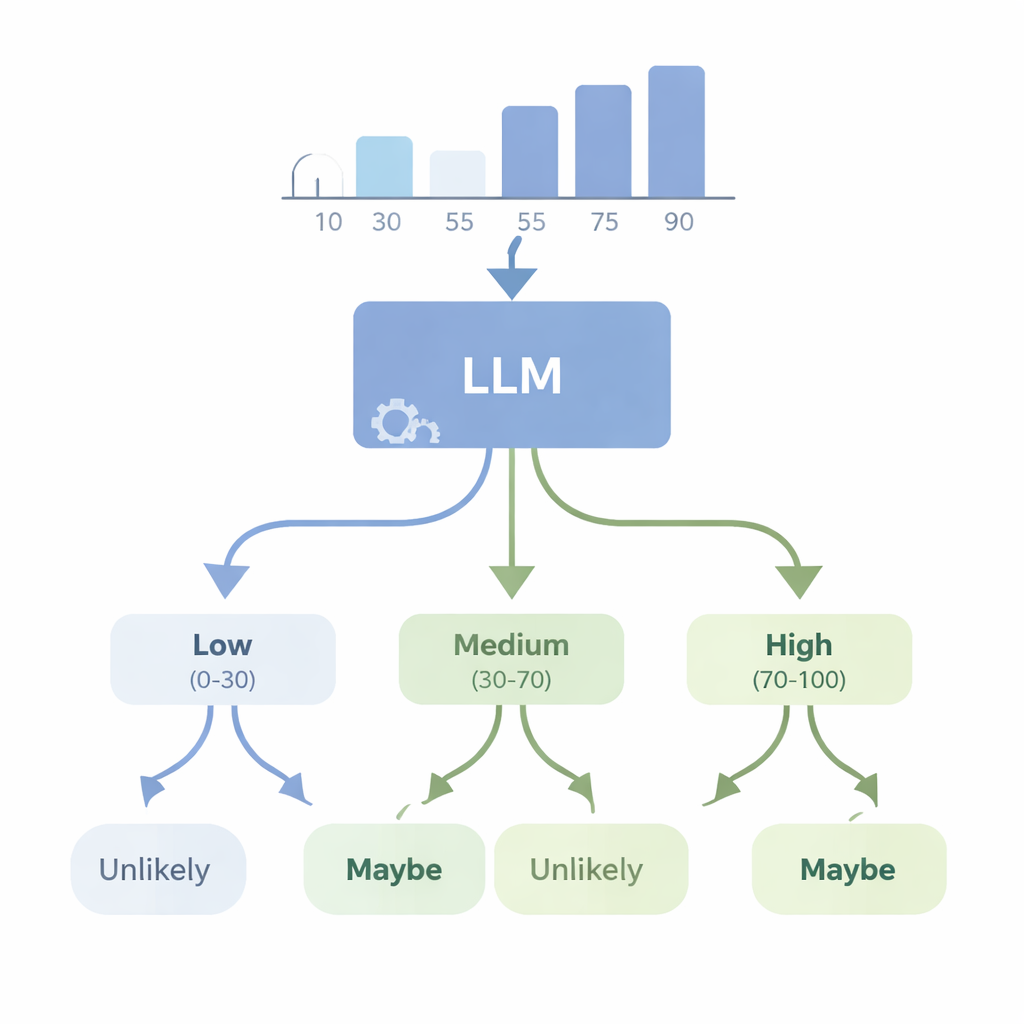
¿Pueden las IAs convertir números en dudas expresadas en lenguaje llano?
En un segundo conjunto de experimentos, los autores examinaron el problema inverso: ¿puede un modelo avanzado como GPT-4 partir de datos numéricos y elegir una palabra de incertidumbre apropiada? Alimentaron al modelo con conjuntos de datos simples—listas de alturas o puntuaciones de pruebas—y le pidieron escoger la WEP que mejor encajara (por ejemplo, “casi con seguridad”, “probable”, “tal vez”, “improbable” o “casi seguro que no”) para afirmaciones sobre resultados futuros. Luego evaluaron a GPT-4 con cuatro nuevas puntuaciones de “consistencia” que verifican si sus elecciones de palabras tienen sentido lógico cuando las probabilidades suben o bajan, cuando se describen eventos complementarios y cuando los números subyacentes cambian de manera controlada. GPT-4 rindió mucho mejor que el azar y con frecuencia pudo seguir cambios aproximados en la probabilidad, pero quedó lejos de una consistencia perfecta. En algunas pruebas respondió casi de la misma manera a diferentes niveles de confianza, lo que sugiere que en ocasiones trata estas palabras como etiquetas generales en lugar de una escala finamente calibrada vinculada a los datos reales.
Qué significa esto para las decisiones del mundo real
Para los lectores, el mensaje es de precaución pero no alarmista. Los LLM ya pueden imitar nuestras expresiones más firmes de certeza e imposibilidad, y con frecuencia pueden resumir datos en enunciados razonables como “probable” o “improbable”. Pero este estudio muestra que para muchas palabras cotidianas de incertidumbre, su calibración interna no coincide completamente con la intuición humana, y su mapeo de números a lenguaje puede ser inconsistente. En ámbitos como la medicina, la política o la comunicación científica—donde pequeños cambios en la forma de expresar el riesgo o la confianza pueden tener importancia—el “probablemente” de un modelo puede no ser el mismo que el tuyo. Los autores sostienen que, para usar estos sistemas con seguridad, debemos tratar las palabras de incertidumbre como un libro de códigos compartido que aún necesita alineación cuidadosa, pruebas y quizá respaldo numérico explícito, en lugar de asumir por defecto que humano y máquina significan lo mismo.
Cita: Tang, Z., Shen, K. & Kejriwal, M. An evaluation of estimative uncertainty in large language models. npj Complex 3, 8 (2026). https://doi.org/10.1038/s44260-026-00070-6
Palabras clave: incertidumbre lenguaje, modelos de lenguaje a gran escala, palabras de probabilidad, comunicación humano-IA, interpretación del riesgo