Clear Sky Science · es
Predicción e interpretación de respuestas farmacológicas específicas por tipo celular en el régimen de datos escasos usando prior inductivos
Por qué esta investigación importa para las medicinas del futuro
Cuando se prueba un nuevo fármaco, una de las mayores incógnitas es cuánto diferirá su efecto entre los muchos tipos de células de nuestro cuerpo. Un compuesto que beneficia a un tipo celular puede no afectar a otro o incluso causar daño. Generar experimentalmente esta información para miles de fármacos y una multitud de tipos celulares resulta demasiado lento y costoso. Este artículo presenta un enfoque computacional, llamado PrePR-CT, que aprende a predecir cómo responden tipos celulares individuales a fármacos, incluso cuando solo hay datos limitados. El trabajo apunta a maneras más rápidas, baratas y precisas de explorar medicamentos potenciales in silico antes de comprometerse con costosos estudios de laboratorio y clínicos.
Mirar dentro de las células en lugar de fijarse solo en los fármacos
Las pruebas farmacológicas tradicionales a menudo tratan a las células como si fueran todas iguales y se centran principalmente en promedios agregados. En realidad, las células inmunitarias, hepáticas y cancerosas pueden reaccionar de manera muy distinta al mismo compuesto. Los autores sostienen que, para predecir estas diferencias, un modelo debe comprender el cableado interno de cada tipo celular: qué genes tienden a activarse juntos y cómo esos patrones definen la identidad de la célula. Construyen "mapas" por tipo celular examinando qué genes en células no perturbadas (controles) suben y bajan al unísono. Cada mapa se representa como una red, donde los nodos representan genes y los enlaces reflejan una fuerte coactividad. Estas redes sirven como conocimiento previo sobre cómo está organizada un tipo celular antes de añadir cualquier fármaco.
Un motor de aprendizaje consciente de redes
PrePR-CT combina tres ingredientes: la red de actividad génica de un tipo celular, la expresión génica basal de ese tipo celular y una descripción compacta de la estructura química del fármaco. El modelo utiliza una clase de redes neuronales diseñadas para grafos para procesar la red génica de la célula y extraer un resumen que capture sus patrones característicos. En paralelo, convierte cada fármaco en una huella numérica derivada de su estructura molecular. Estas piezas se introducen en un módulo de predicción que aprende, a partir de experimentos disponibles, cómo un fármaco dado desplazará la distribución de la actividad génica en ese tipo celular. En lugar de producir un único número por gen, el método estima tanto el cambio medio como la variabilidad de la respuesta entre células individuales, lo cual es crucial para comprender efectos sutiles y fuertes por igual.
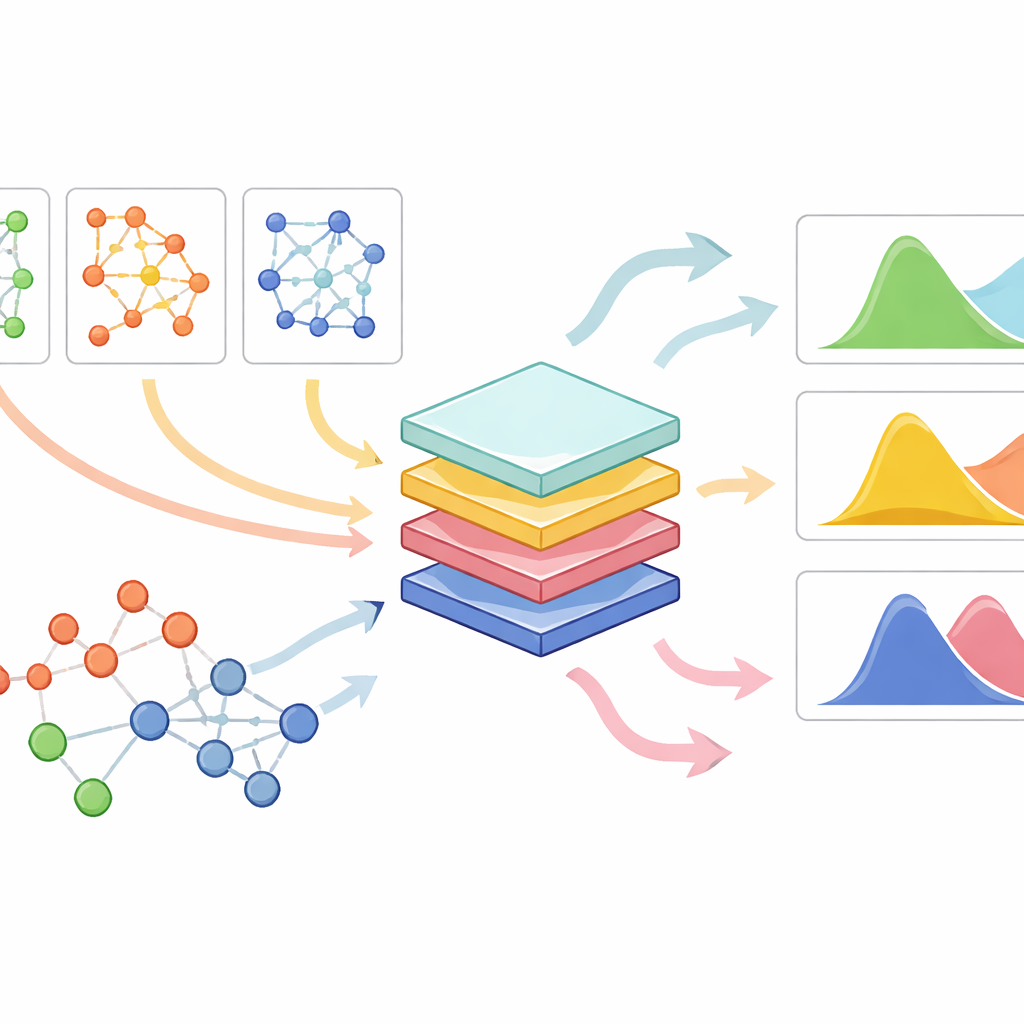
Trabajar a través de muchos tipos celulares, fármacos y conjuntos de datos pequeños
Los investigadores probaron PrePR-CT en una amplia colección de conjuntos de datos, incluidos células sanguíneas humanas expuestas a señales inmunitarias, varias líneas celulares cancerosas tratadas con distintos compuestos, células hepáticas de ratón expuestas a un contaminante y cribados farmacológicos a gran escala de recursos públicos. En escenarios desafiantes en los que se excluía por completo un tipo celular durante el entrenamiento, el modelo aún pudo predecir cómo ese nuevo tipo celular respondería a un fármaco conocido, a menudo con una precisión superior a la de modelos generativos anteriores. Del mismo modo, cuando se dejaba fuera un fármaco nuevo pero el tipo celular era familiar, el método anticipó con éxito su impacto usando solo su huella química. De forma importante, el modelo siguió siendo eficaz cuando se entrenó con números relativamente pequeños de células, una situación en la que muchos enfoques de aprendizaje profundo tienen dificultades.
De caja negra a pistas sobre el mecanismo
Más allá de la mera predicción, los autores querían saber si su modelo podía ofrecer información sobre qué genes y vías impulsan la respuesta de una célula. La arquitectura basada en grafos incluye un mecanismo de atención que realza los genes que el modelo considera especialmente influyentes en cada tipo celular. Muchos de estos genes de "alta atención" no coincidían con los sospechosos habituales señalados por el análisis estándar de expresión diferencial, sin embargo se agruparon en vías relacionadas con la inmunidad coherentes con la biología de los fármacos probados. Cuando los investigadores alteraron deliberadamente estos genes influyentes en la entrada del modelo, la calidad de la predicción disminuyó, especialmente para los genes más reactivos, lo que sugiere que las puntuaciones de atención apuntan a jugadores mecanísticos significativos y no a ruido.
Qué implica esto para diseñar mejores fármacos
En términos sencillos, este trabajo muestra que dotar a los modelos de inteligencia artificial de una visión estructurada de cómo está cableado cada tipo celular—su red génica interna—mejora en gran medida su capacidad para pronosticar cómo los fármacos remodelarán esas células, incluso cuando solo hay datos modestos. PrePR-CT no sustituye a los experimentos, pero puede ayudar a acotar qué compuestos y tipos celulares merecen ensayos y sugerir por qué ciertas células reaccionan como lo hacen. A medida que los conjuntos de datos crezcan y se incorporen más características celulares, estos enfoques podrían convertirse en herramientas clave para adaptar terapias a tejidos específicos o tipos celulares de pacientes, reduciendo la prueba y error en el laboratorio y acercando medicinas más precisas a la realidad.
Cita: Alsulami, R., Lehmann, R., Khan, S.A. et al. Predicting and interpreting cell-type-specific drug responses in the small-data regime using inductive priors. Nat Mach Intell 8, 461–473 (2026). https://doi.org/10.1038/s42256-026-01202-2
Palabras clave: predicción de respuesta a fármacos, transcriptómica de célula única, redes neuronales de grafos, descubrimiento de fármacos, especificidad por tipo celular