Clear Sky Science · es
ADMM estocástico inexacto preacondicionado para modelos profundos
Entrenamiento más inteligente para una IA más inteligente
Los sistemas de inteligencia artificial modernos, desde chatbots hasta generadores de imágenes, se alimentan de redes neuronales masivas que son notoriamente difíciles y costosas de entrenar. A medida que empresas e investigadores distribuyen datos entre muchos dispositivos y servidores, los métodos de entrenamiento habituales suelen ralentizarse, volverse inestables o simplemente no dar abasto frente a la heterogeneidad de datos del mundo real. Este artículo presenta una nueva familia de algoritmos de entrenamiento, centrada en un método llamado PISA, que promete un aprendizaje más rápido y fiable para una amplia gama de modelos profundos, al tiempo que requiere menos supuestos matemáticos sobre los datos.
Por qué los métodos actuales tienen dificultades
La mayoría de los modelos de aprendizaje profundo se entrenan con variantes del descenso por gradiente estocástico, un enfoque que ajusta repetidamente los parámetros del modelo en la dirección que reduce el error. Con los años, muchas mejoras —como Adam, RMSProp y otras— han intentado hacer esos ajustes más inteligentes adaptando los tamaños de paso o añadiendo momento. Sin embargo, estos métodos suelen asumir que los datos de entrenamiento están bien barajados y son estadísticamente similares entre máquinas, y que ciertas cantidades matemáticas permanecen acotadas. En la práctica, especialmente en escenarios como el aprendizaje federado donde teléfonos o dispositivos periféricos contienen datos muy diferentes, esos supuestos a menudo se violan, lo que conduce a convergencia lenta o a un rendimiento deficiente.
Una nueva forma de coordinar muchos aprendices
Los autores parten de un marco de optimización distinto conocido como método de direcciones alternadas de multiplicadores (ADMM), que es eficaz para dividir un problema grande en muchos subproblemas más pequeños que pueden resolverse en paralelo. Su contribución principal, PISA (ADMM estocástico inexacto preacondicionado), conserva las fortalezas de ADMM evitando sus desventajas habituales —como la necesidad de calcular gradientes completos sobre todos los datos o realizar inversiones de matrices costosas. En su lugar, PISA permite que cada cliente o nodo trabajador actualice su propia copia del modelo usando solo un mini-lote de datos y luego coordina estas actualizaciones mediante una variable central. Matrices de "preacondicionamiento" diseñadas con cuidado reconfiguran las direcciones de actualización para que el aprendizaje progrese de forma más suave y eficiente. 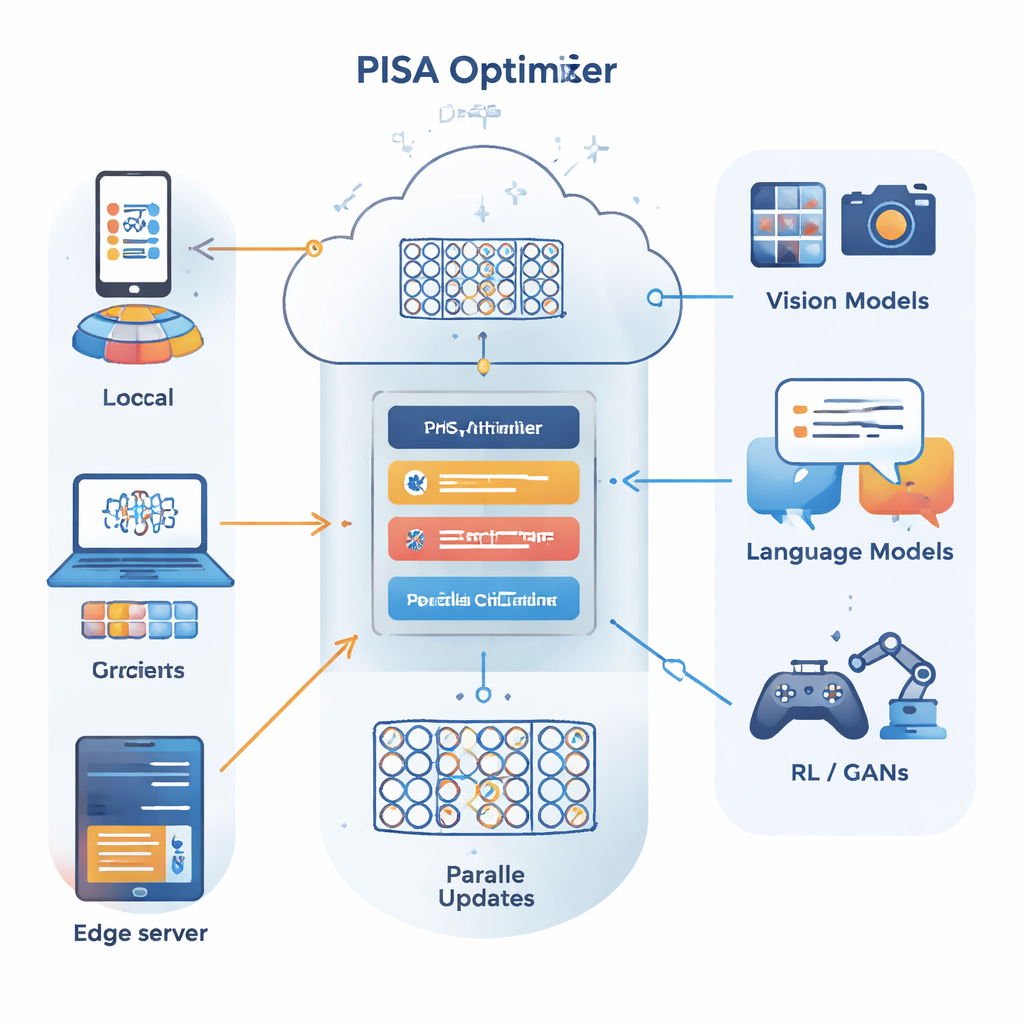
Garantías más sólidas con supuestos más suaves
Un rasgo distintivo de PISA es su fundamentación teórica. Los autores demuestran que su algoritmo converge bajo un único supuesto relativamente tenue: que el gradiente de la función de pérdida es Lipschitz continuo dentro de una región acotada, una condición satisfecha por muchas pérdidas estándar en redes neuronales. A diferencia de la mayoría de los métodos estocásticos, PISA no requiere que los gradientes sean insesgados, que tengamos varianza acotada o que los datos provengan de una mezcla perfecta. A pesar de este planteamiento relajado, el método alcanza una tasa de convergencia lineal en términos de la velocidad a la que se estabilizan los valores de la función y las actualizaciones de parámetros, situándose entre los algoritmos de mejor rendimiento en la tabla comparativa proporcionada. Esto hace que PISA sea especialmente atractivo para distribuciones de datos heterogéneas y no uniformes, habituales en despliegues reales.
Variantes prácticas para redes profundas reales
Para hacer el marco práctico en redes neuronales grandes, los autores presentan dos variantes eficientes, SISA y NSISA. SISA utiliza información del segundo momento —esencialmente rastreando cuán grandes han sido las actualizaciones pasadas en cada dirección de parámetro— para formar precondicionadores diagonales simples, semejantes a las ideas detrás de Adam y RMSProp pero integradas dentro de la estructura ADMM. NSISA da un paso más al incorporar una técnica conocida como ortogonalización de Newton–Schulz, inspirada en el optimizador Muon, para alinear mejor el momento con direcciones útiles en el espacio de parámetros. Ambas variantes conservan las garantías de convergencia de PISA mientras mantienen el cómputo lo suficientemente ligero para GPUs modernas y modelos grandes.
Rendimiento en visión, lenguaje y modelos generativos
Los autores prueban SISA y NSISA en un conjunto amplio de tareas de aprendizaje profundo. En experimentos de aprendizaje federado con distribuciones de etiquetas deliberadamente sesgadas —un escenario difícil donde cada cliente ve solo un subconjunto de clases— SISA supera drásticamente a métodos populares como FedAvg, FedProx, FedNova y Scaffold, logrando una precisión de prueba mucho mayor en benchmarks como MNIST y CIFAR-10. Para clasificación de imágenes estándar con modelos como ResNet y DenseNet en CIFAR-10 e ImageNet, SISA iguala o supera a optimizadores potentes incluyendo SGD con momentum, AdaBelief y AdamW. Al afinar modelos de lenguaje GPT2 de tamaño creciente, NSISA alcanza menor pérdida de validación en menos tiempo de reloj que optimizadores especializados como Shampoo, SOAP, Adam-mini y Muon, con la ventaja haciéndose más pronunciada en el modelo de mayor tamaño. También estabiliza el entrenamiento de redes generativas antagónicas, obteniendo puntuaciones de Fréchet inception distance más bajas, que miden la calidad visual y la diversidad de las imágenes generadas. 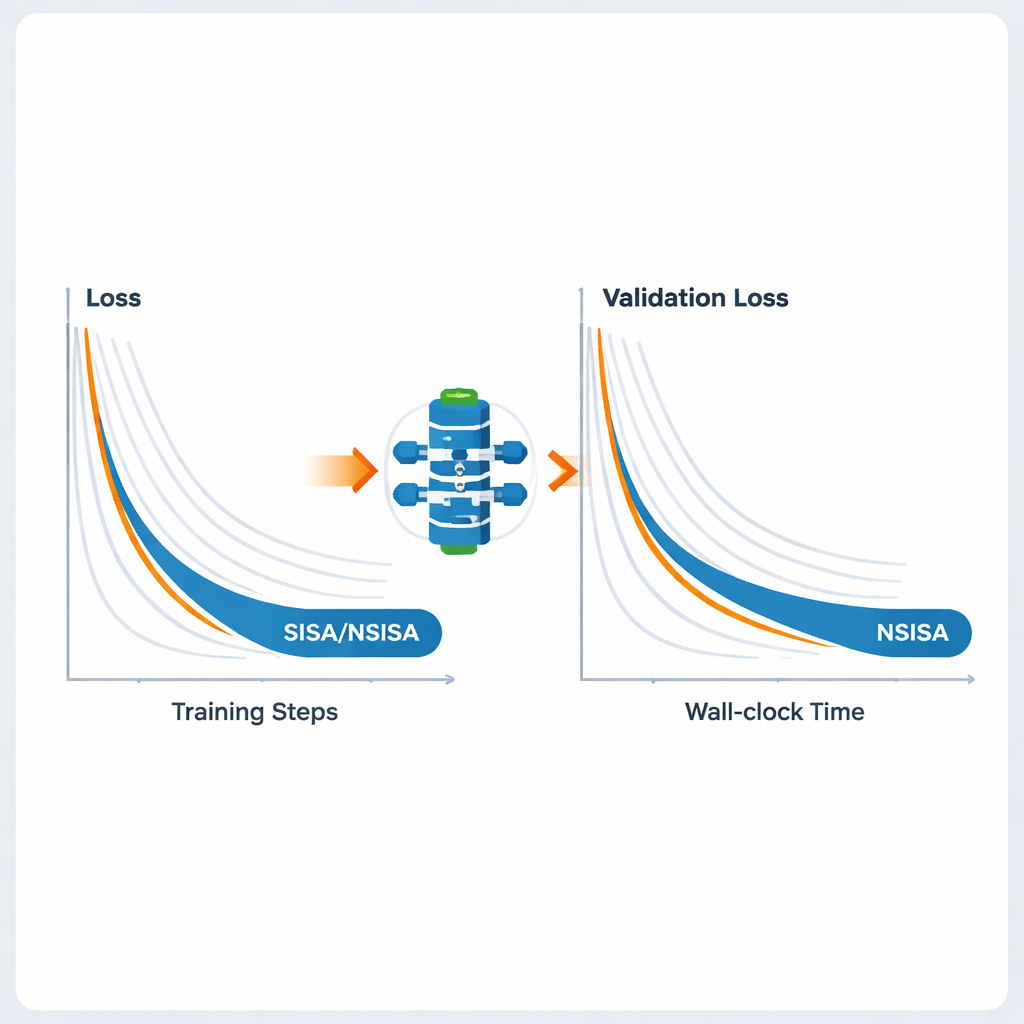
Qué significa esto para la IA cotidiana
En términos sencillos, este trabajo demuestra que es posible entrenar modelos de IA potentes de forma más rápida y fiable, incluso cuando los datos son desordenados, desequilibrados o están dispersos en muchos dispositivos. Al rediseñar el proceso de optimización subyacente en lugar de limitarse a ajustar las tasas de aprendizaje, PISA y sus variantes ofrecen una herramienta unificada que funciona bien para tareas de visión, lenguaje, aprendizaje por refuerzo y generativas. Para los usuarios finales, el beneficio podría traducirse en una personalización más inteligente en teléfonos, modelos de lenguaje e imagen más capaces y un uso más eficiente de los recursos informáticos en grandes centros de datos —todo ello posibilitado por un algoritmo de entrenamiento que se ajusta mejor a las realidades de los sistemas de IA modernos.
Cita: Zhou, S., Wang, O., Luo, Z. et al. Preconditioned inexact stochastic ADMM for deep models. Nat Mach Intell 8, 234–245 (2026). https://doi.org/10.1038/s42256-026-01182-3
Palabras clave: optimización en aprendizaje profundo, aprendizaje federado, ADMM estocástico, modelos de lenguaje grandes, datos heterogéneos