Clear Sky Science · es
Mejora de la predicción de kcat mediante un mecanismo de atención consciente de residuos y representaciones preentrenadas
Por qué importan las predicciones más rápidas de enzimas
Las enzimas son las pequeñas fuerzas motoras que mantienen en funcionamiento a las células —y a industrias enteras—. Aceleran las reacciones químicas que impulsan nuestro metabolismo, fabrican medicamentos y permiten procesos de producción más sostenibles. Un número clave que describe la velocidad de una enzima es el número de recambio, o kcat. Medir kcat en el laboratorio es lento y caro, por lo que los científicos recurren a la inteligencia artificial para predecirlo a partir de la secuencia y la información de la reacción. Este artículo presenta PMAK, un nuevo modelo de IA que no solo predice kcat con mayor precisión que herramientas previas, sino que además ayuda a identificar qué partes de una enzima son más importantes para su actividad.
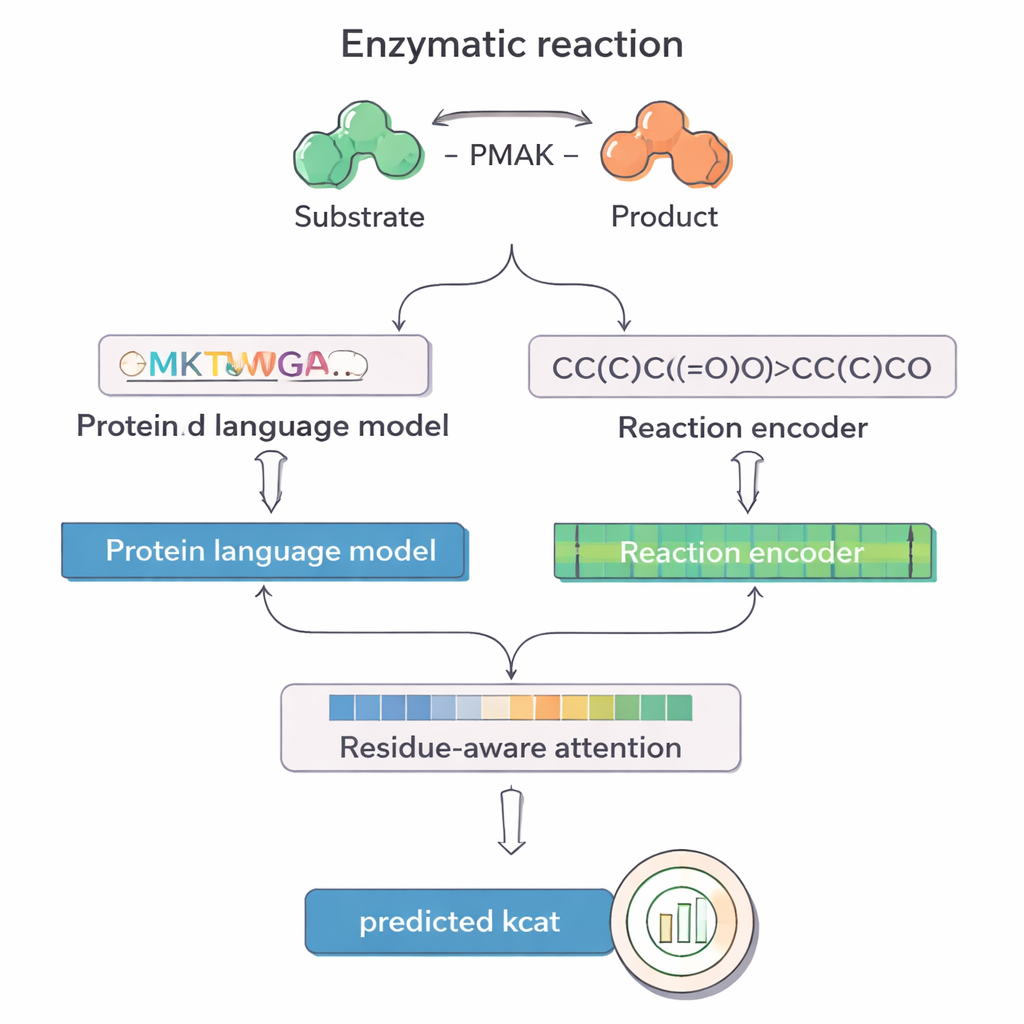
Del trabajo de laboratorio arduo a predicciones inteligentes
Tradicionalmente, determinar kcat implica medir cuidadosamente la rapidez con que una enzima convierte su sustrato en producto bajo condiciones controladas, como temperatura y pH constantes. Hacer esto para miles de enzimas es impracticable, lo que limita nuestra capacidad para modelar redes metabólicas completas o diseñar nuevos biocatalizadores. Métodos computacionales previos intentaron cubrir este vacío, pero muchos dependían de características diseñadas a mano o de una visión simplificada de la enzima y un único sustrato. A menudo funcionaban bien solo cuando las enzimas nuevas eran muy similares a las ya vistas en los datos de entrenamiento, y tenían dificultades con enzimas verdaderamente nuevas, reacciones inéditas o mutantes diseñados.
Enseñar a las computadoras el “lenguaje” de enzimas y reacciones
PMAK aprovecha avances recientes en “modelos de lenguaje” desarrollados originalmente para texto, pero reentrenados con enormes colecciones de secuencias de proteínas y reacciones químicas. Un modelo, llamado ProT5, convierte la secuencia de aminoácidos de una enzima en una representación numérica rica que captura patrones aprendidos a partir de millones de proteínas. Otro modelo, RXNFP, hace lo mismo para reacciones completas escritas como cadenas SMILES, que codifican reactivos y productos. PMAK alimenta estas dos representaciones aprendidas en una red neuronal que alinea sus dimensiones y permite al modelo considerar tanto la enzima como el contexto completo de la reacción conjuntamente, en lugar de tratarlos por separado.
Resaltar los bloques de construcción más importantes
Una innovación central en PMAK es un mecanismo de “atención consciente de residuos”. En lugar de tratar cada aminoácido de una enzima como igualmente importante, el modelo aprende a asignar pesos mayores a residuos específicos que importan más para la reacción en cuestión. Estas puntuaciones de atención actúan como un foco sobre la secuencia: cuando los investigadores las compararon con sitios activos y de unión conocidos a partir de estructuras proteicas, encontraron que PMAK resaltaba de forma consistente residuos funcionales con mucha más frecuencia que el azar. El modelo también mostró buen rendimiento cuando los sitios activos se definieron de forma más amplia para incluir residuos vecinos en el espacio 3D, lo que sugiere que captura señales estructurales y químicas sutiles relevantes para la catálisis.
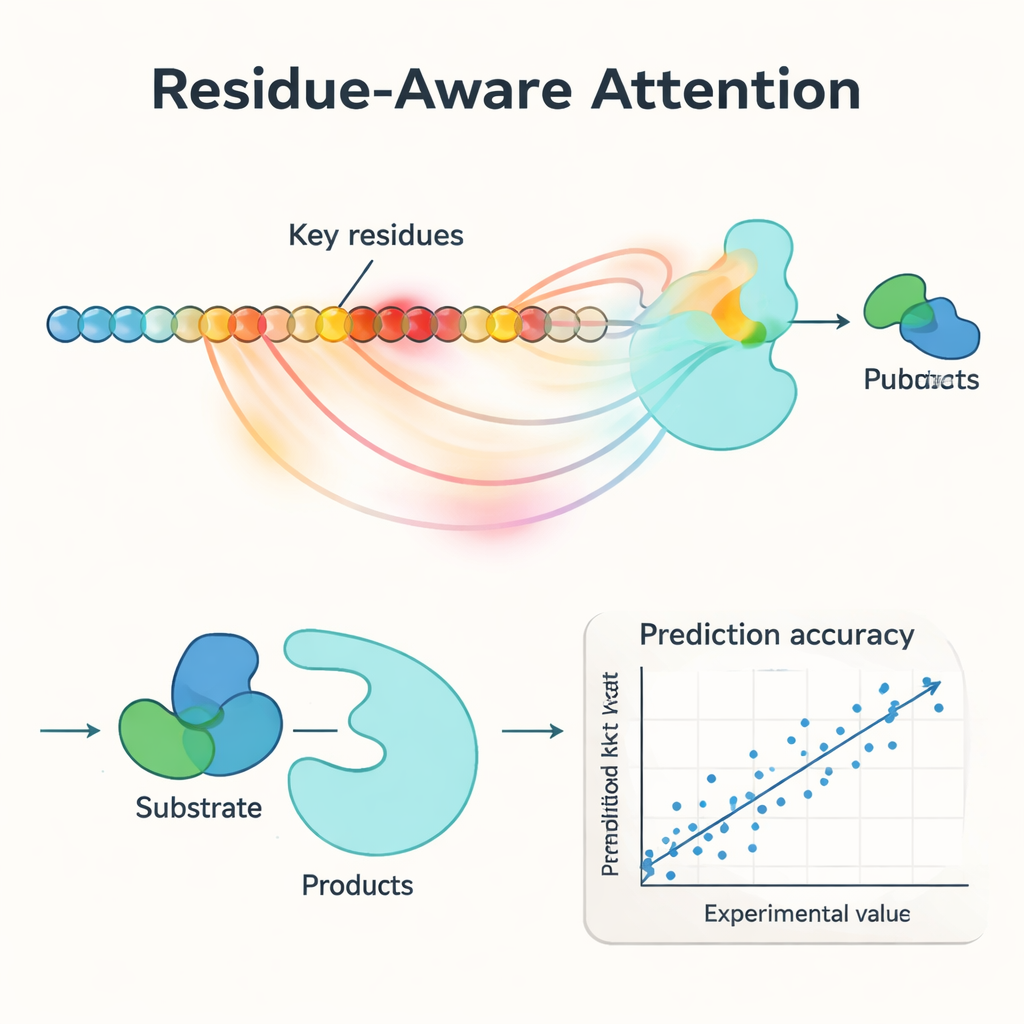
Buen rendimiento en enzimas nuevas, reacciones nuevas y mutantes
Los autores probaron rigurosamente PMAK en un conjunto depurado de más de 4.000 valores de kcat que abarcan cerca de 3.000 enzimas y 2.800 reacciones. Bajo condiciones de “inicio cálido” —donde enzimas y reacciones similares aparecen tanto en los conjuntos de entrenamiento como en los de prueba—, PMAK igualó o superó a los mejores modelos existentes. Más impresionante aún, en pruebas de “inicio en frío” donde la enzima o la reacción del conjunto de prueba no se habían visto antes, PMAK superó a una variedad de métodos líderes. Siguió siendo útil incluso para enzimas con muy baja similitud de secuencia respecto a los datos de entrenamiento y para reacciones que eran bastante diferentes de las que había aprendido. PMAK también mejoró las predicciones en aplicaciones realistas, como estimar cómo las células asignan sus limitados recursos proteicos y prever los efectos de mutaciones en conjuntos de datos de ingeniería enzimática.
Qué significa esto para la biología y la biotecnología
Para quienes no son especialistas, PMAK puede verse como un asistente inteligente que aprende de enormes “bibliotecas” de proteínas y reacciones para estimar la velocidad a la que funcionará cualquier enzima en una reacción particular —y para explicar qué aminoácidos impulsan ese comportamiento. Al combinar mayor precisión con información a nivel de residuos, este enfoque puede ayudar a los investigadores a diseñar mejores enzimas, construir modelos metabólicos más fiables y explorar cómo las mutaciones afectan la función sin realizar todos los experimentos en el laboratorio. A medida que modelos similares se apliquen a otros rasgos cinéticos, podrían convertirse en herramientas clave para diseñar procesos industriales más limpios, optimizar microbios para producción sostenible y profundizar nuestra comprensión de cómo las máquinas moleculares de la vida alcanzan su notable velocidad.
Cita: Cai, Y., Ge, F., Zhang, C. et al. Enhancing kcat prediction through residue-aware attention mechanism and pre-trained representations. Commun Biol 9, 273 (2026). https://doi.org/10.1038/s42003-026-09551-9
Palabras clave: cinética enzimática, aprendizaje profundo, predicción de kcat, ingeniería de proteínas, modelado metabólico