Clear Sky Science · es
Definiendo la seguridad operativa en sistemas de inteligencia artificial clínica
Por qué importa una IA segura en medicina
Los hospitales están adoptando rápidamente la inteligencia artificial para leer exploraciones y señalar enfermedades, pero hay una cuestión que las puntuaciones de precisión habituales no pueden responder: ¿cuándo es realmente seguro dejar que la máquina tome la decisión? Este artículo presenta un método práctico para decidir cuándo los médicos pueden confiar con seguridad en un sistema de IA, cuándo deben ignorarlo y cuándo deben examinar el caso más detenidamente por sí mismos. El objetivo no es simplemente crear algoritmos más inteligentes, sino integrarlos en la atención diaria de forma que protejan a los pacientes, reduzcan pruebas innecesarias y alivien la carga de los clínicos en lugar de aumentarla.
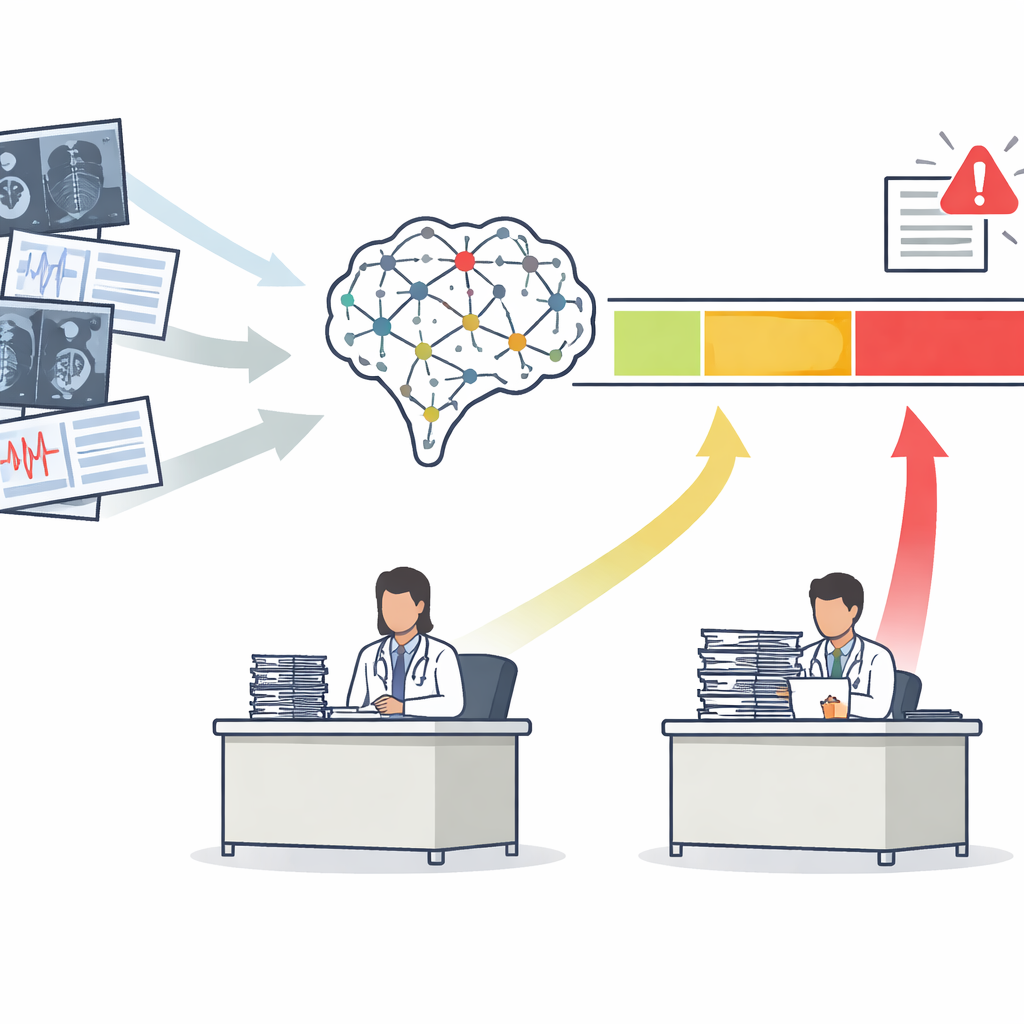
De una puntuación a tres zonas claras de acción
La mayoría de las herramientas de IA médica generan una única puntuación de riesgo, como la probabilidad de que una mamografía muestre cáncer. Tradicionalmente, los desarrolladores evalúan estas herramientas con una curva que resume cómo separan, en conjunto, a los pacientes enfermos de los sanos. Los autores sostienen que eso no es suficiente. Proponen el marco Safety-Aware ROC (SA-ROC), que parte de las mismas puntuaciones de riesgo pero las transforma en tres regiones prácticas. Una zona de «rule-in» de puntuaciones altas contiene a los pacientes cuyos resultados son lo bastante fiables como para provocar una acción, como un seguimiento urgente. Una zona de «rule-out» de puntuaciones bajas contiene a los pacientes cuyos resultados son lo bastante fiables como para despriorizarlos con seguridad. Entre ambas existe una «zona gris» de incertidumbre, donde la IA no es lo bastante confiable y un experto humano debe revisar el caso.
Permitir que los clínicos fijen el umbral de seguridad
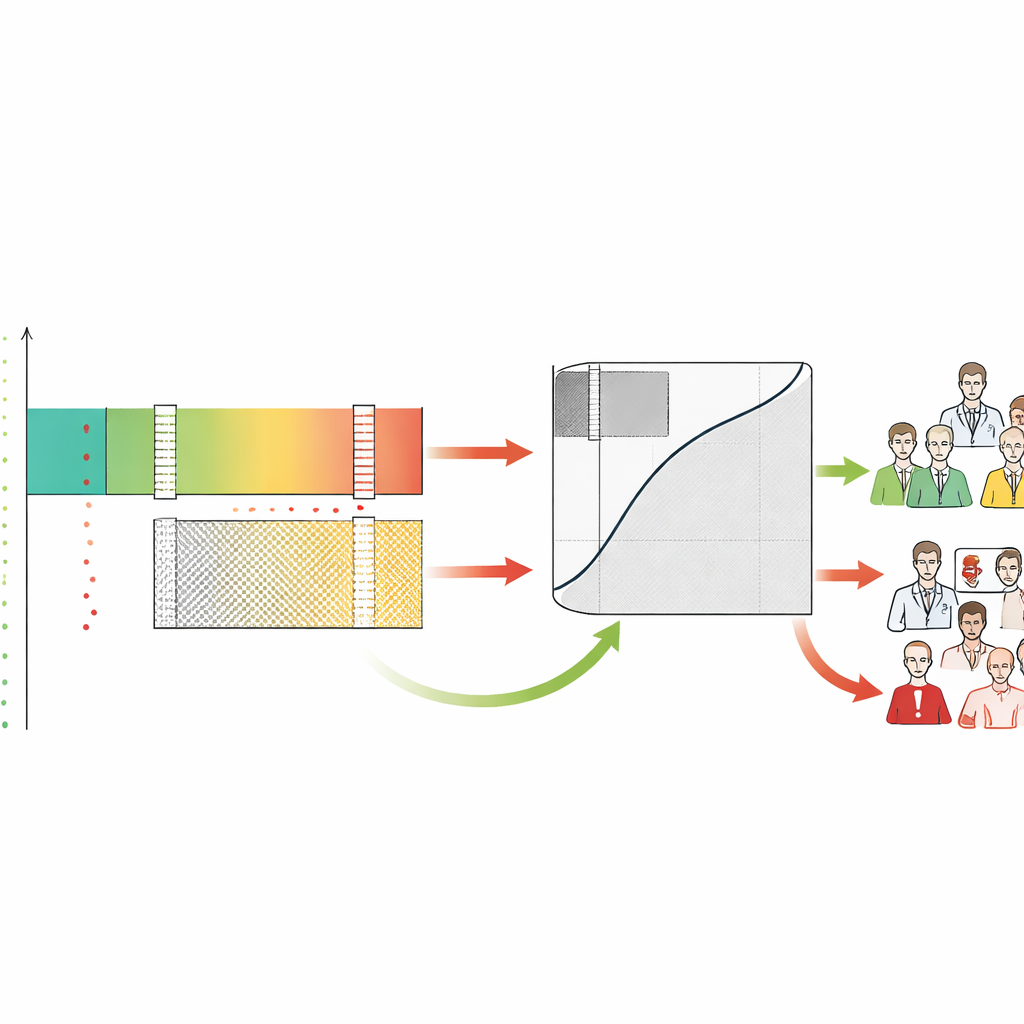
De forma crucial, SA-ROC permite que los clínicos e instituciones definan sus propios objetivos de seguridad desde el principio. Ellos eligen cuán seguros quieren estar antes de actuar sobre un resultado positivo (la probabilidad mínima aceptable de que un hallazgo señalado sea realmente anómalo) y cuán seguros quieren estar antes de relajarse tras un resultado negativo (la probabilidad mínima aceptable de que un caso descartado sea realmente normal). Dados estos objetivos, el marco explora las puntuaciones del modelo para encontrar los límites exactos que los satisfacen. Las puntuaciones por encima del límite superior forman la zona segura de rule-in, las puntuaciones por debajo del límite inferior forman la zona segura de rule-out y todo lo intermedio se convierte en la zona gris. El marco cuantifica entonces cuántos pacientes caen en cada región y cuánto trabajo incierto—casos devueltos a los humanos—deja sin resolver la IA.
Revelando diferencias ocultas entre IAs similares
Los autores muestran que dos sistemas de IA con puntuaciones de precisión tradicionales casi idénticas pueden comportarse de manera muy diferente cuando se los examina desde esta óptica de seguridad. En simulaciones, modelos con el mismo rendimiento global produjeron tamaños muy distintos de zonas de rule-in, rule-out y zona gris según cómo se distribuyeran sus puntuaciones. Uno podría sobresalir en confirmar la enfermedad con confianza, mientras que otro podría sobresalir en declarar con seguridad a un gran número de pacientes de bajo riesgo como claros. En un estudio de caso real de dos herramientas aprobadas por la Administración de Alimentos y Medicamentos de EE. UU. para cribado de cáncer de mama, el sistema con la mayor puntuación estándar de precisión fue en realidad peor para el cribado de alta confianza. En el ajuste de seguridad más estricto—no permitir ningún cáncer perdido en el grupo de bajo riesgo—el sistema supuestamente más débil eliminó de manera segura a casi el doble de mujeres de la cola de trabajo del radiólogo. SA-ROC expone así una especie de «inversión de rendimiento» que las métricas convencionales ocultan.
Comprender la tensión humano–IA y la carga de trabajo
Al etiquetar cada caso como rule-in, rule-out o gris, el marco también revela cómo se comportan los médicos humanos en estas zonas. Los autores encontraron que los radiólogos a menudo sobrediagnostican casos que la IA consideró de bajo riesgo con seguridad, generando muchas falsas alarmas en la región donde la máquina era más fiable. En contraste, tanto los humanos como la IA tuvieron dificultades en la zona gris, lo que valida que esa área necesita realmente la atención experta. SA-ROC captura el tamaño de esta zona gris en un solo número, que representa el coste de la indecisión. Una zona gris pequeña significa más automatización segura y menos carga de trabajo humano; una zona gris grande implica que muchos casos aún requieren revisión manual cuidadosa y que el sistema puede aumentar el agotamiento en lugar de aliviarlo.
Convertir reglas de seguridad en práctica cotidiana
Más allá de la medición, el marco está diseñado como una herramienta de gobernanza que convierte políticas en comportamiento concreto de la IA. Los hospitales pueden usarlo de dos maneras. Primero, pueden especificar directamente requisitos de seguridad o límites sobre cuántos casos están dispuestos a enviar a la zona gris y dejar que el marco calcule los umbrales correspondientes. Segundo, pueden asignar valores y penalizaciones a distintos desenlaces—detectar un cáncer, pasar por alto uno, ordenar una prueba innecesaria o remitir a revisión humana—y hacer que el marco busque la política que maximice el beneficio global. Estas estrategias pueden ajustarse para objetivos muy distintos, como programas de cribado masivo, derivaciones a especialistas o cohortes de investigación, todo usando el mismo modelo subyacente.
Qué significa esto para pacientes y clínicos
En términos sencillos, este trabajo ofrece una manera de decir no solo «esta IA es precisa», sino «aquí está exactamente cuándo y cómo puede confiarse en la clínica». Al dividir las salidas de la IA en regiones seguras, inseguras e inciertas vinculadas a promesas explícitas de seguridad, SA-ROC ayuda a los sistemas de salud a decidir cuándo las máquinas pueden actuar por sí solas y cuándo los humanos deben mantenerse firmemente al mando. Subraya que las puntuaciones de precisión tradicionales pueden ser engañosas y que la seguridad real depende de cómo se comporta un modelo en los extremos donde los errores son más costosos. Si se adopta ampliamente y se valida en entornos reales más amplios, este marco podría apoyar una automatización más fiable, reducir alarmas y pruebas innecesarias y convertir los casos más difíciles para la IA—la zona gris—en una fuente focalizada de aprendizaje y mejora tanto para los algoritmos como para la medicina en sí.
Cita: Kim, YT., Kim, H., Bahl, M. et al. Defining operational safety in clinical artificial intelligence systems. npj Digit. Med. 9, 281 (2026). https://doi.org/10.1038/s41746-026-02450-7
Palabras clave: inteligencia artificial clínica, seguridad operativa, imagen médica, apoyo a la decisión, estratificación de riesgo