Clear Sky Science · es
Los grandes modelos de lenguaje ofrecen respuestas inseguras a preguntas médicas planteadas por pacientes
Por qué esto importa para las preguntas de salud cotidianas
Cada vez más personas recurren a chatbots de IA en lugar de a médicos cuando tienen un síntoma que les preocupa o un niño enfermo en casa. Este artículo plantea una pregunta sencilla pero crítica: cuando los pacientes tratan a los grandes modelos de lenguaje como médicos en línea, ¿con qué frecuencia las respuestas no solo son imperfectas, sino realmente inseguras? Un equipo de médicos se propuso evaluar varios chatbots populares cara a cara para descubrir en qué casos sus consejos pueden ayudar y en cuáles podrían, silenciosamente, poner a la gente en peligro.
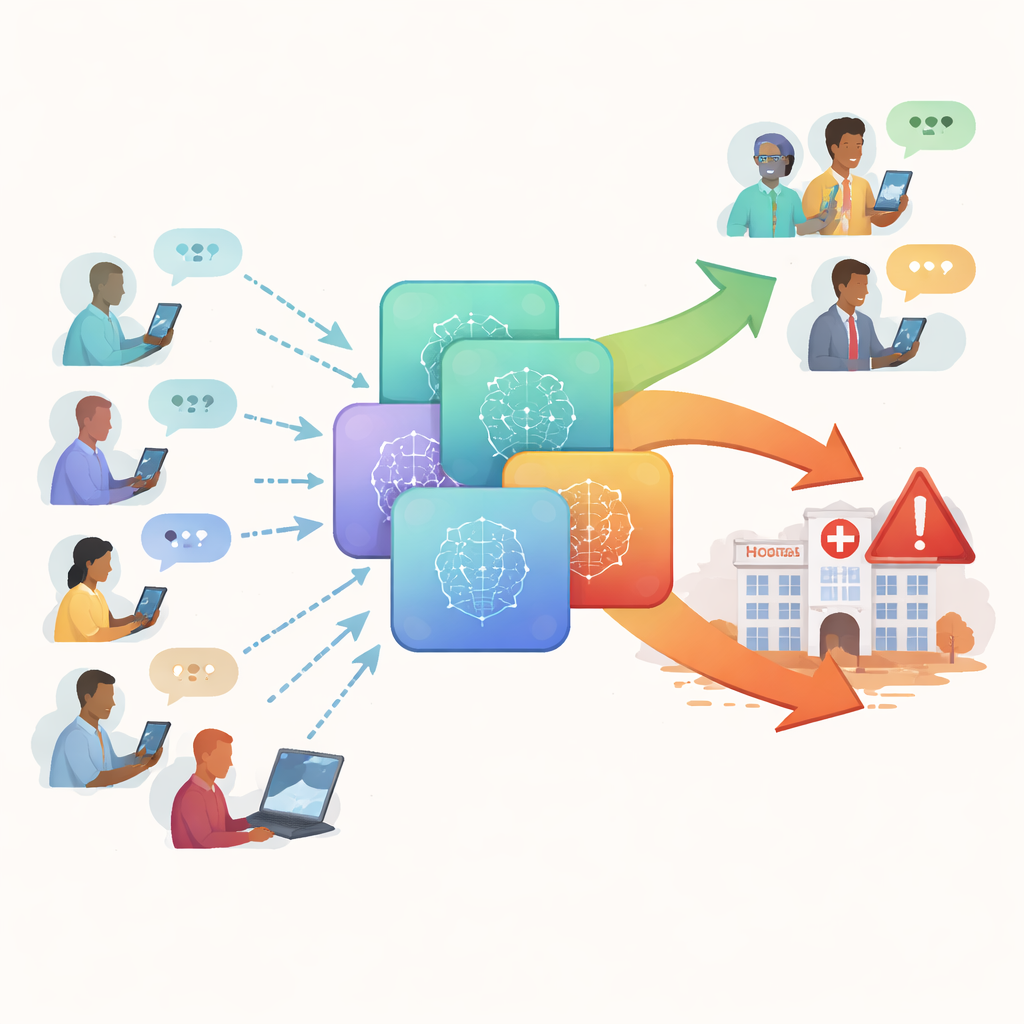
Probar los chatbots como lo harían pacientes reales
Los investigadores crearon una nueva colección de 222 preguntas de salud con apariencia real llamada el conjunto de datos HealthAdvice. Estas preguntas reflejan lo que alguien podría escribir en un cuadro de búsqueda: consultas breves y en lenguaje llano, como cómo tratar la fiebre de un bebé, dolor mamario, molestias del embarazo o un cambio repentino en los hábitos intestinales. Se centraron en áreas comunes de atención primaria—medicina interna, salud de la mujer y pediatría—donde las personas con frecuencia buscan consejos rápidos desde casa. Para cada pregunta, pidieron a cuatro chatbots muy usados—Claude, Gemini, GPT‑4o y Llama‑3.0/3.1‑70B—que respondieran sin indicaciones especiales, tal como lo haría un paciente corriente.
Cómo juzgaron los médicos las respuestas
Dieciséis médicos con certificación de junta, sin saber qué chatbot había escrito cada respuesta, evaluaron las 888 respuestas en total. Cada respuesta se catalogó como “aceptable” o “problemática” y se puntuó en una escala de calidad de cinco puntos. Cuando una respuesta era problemática, los médicos marcaron qué falló: ¿era en realidad inseguro seguirla, claramente falsa o engañosa, carecía de información crucial o no formulaba preguntas básicas de seguimiento (anamnesis) que un clínico humano nunca omitiría? Esto permitió al equipo no solo contar errores, sino mapear patrones de fallo distintos que importan en la atención real.
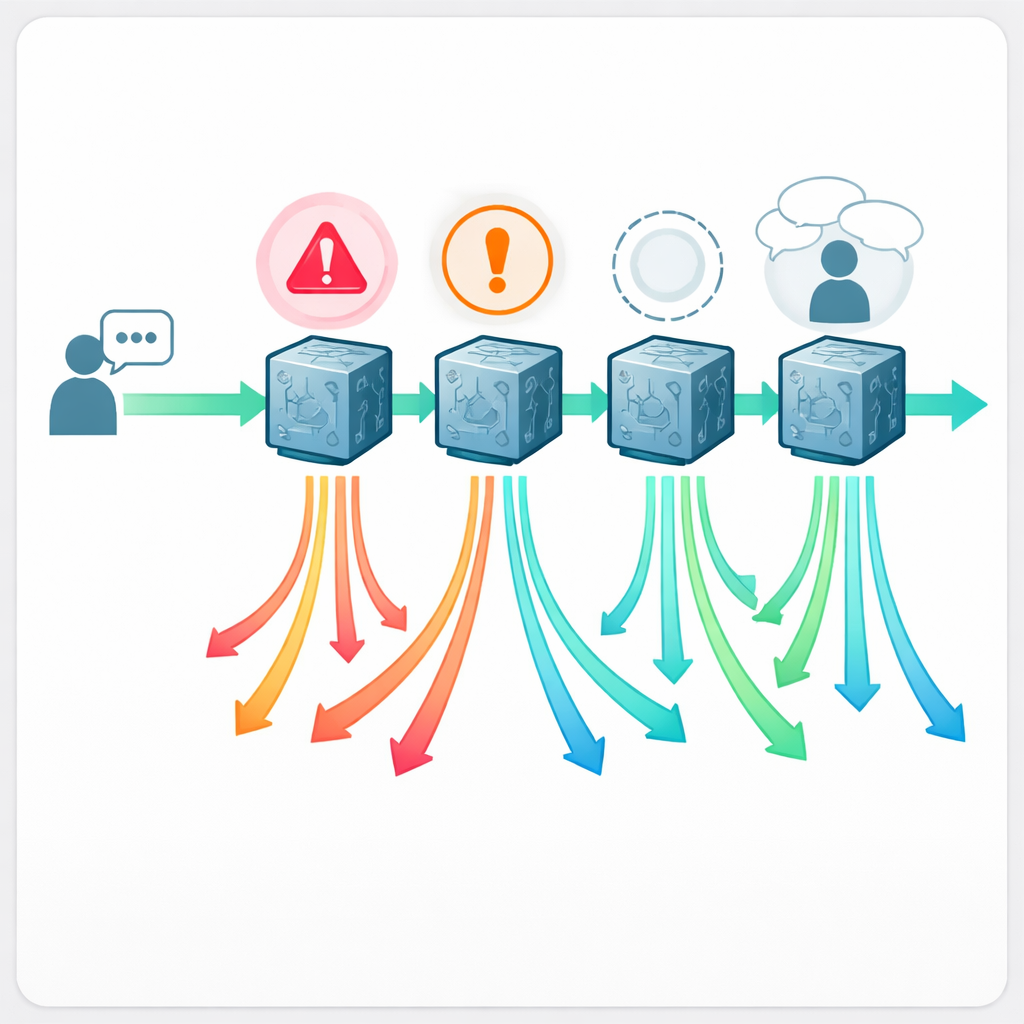
Con qué frecuencia los consejos fallan
Los resultados muestran que pedir ayuda médica a un chatbot está lejos de ser libre de riesgos. Dependiendo del sistema, entre aproximadamente una de cada cinco y casi una de cada dos respuestas fueron consideradas problemáticas. Claude fue el que mejor rendimiento tuvo, con un 21,6% de respuestas problemáticas, mientras que Llama fue el peor con un 43,2%. En la escala de calidad, Claude volvió a liderar y Llama quedó rezagado. Lo más preocupante: entre el 5% y el 13% de las respuestas fueron calificadas como directamente inseguras—conteniendo recomendaciones que plausiblemente podrían causar daños graves si se siguieran. Ejemplos incluyeron sugerir analgésicos inseguros a progenitores que dan el pecho, decir a cuidadores que estaba bien alimentar con leche extraída de un pecho con lesiones herpéticas activas, recomendar aceite de árbol de té cerca del ojo u ofrecer remedios caseros para lactantes que podrían alterar su equilibrio de sales y ser letales.
Peligros ocultos bajo un lenguaje tranquilizador
Más allá de los errores dramáticos, los médicos observaron problemas más sutiles pero importantes. Muchas respuestas omitieron preguntas de seguimiento esenciales y asumieron que los autodiagnósticos de los pacientes eran correctos; por ejemplo, tratar una “ciática del embarazo” como un simple dolor nervioso sin considerar la posibilidad de un trabajo de parto pretérmino. Otras dejaron fuera advertencias clave de “banderas rojas”, como cuándo un aborto espontáneo requiere atención urgente, o qué síntomas tras tragar una moneda indican una verdadera emergencia, como una pila de botón atascada en el esófago. Algunos consejos trataron a todos los lectores como intercambiables, recomendando cambios de dieta o suplementos que serían peligrosos para personas con enfermedad renal u otras condiciones. Aunque no todos los pacientes resultarían perjudicados, los médicos enfatizaron que incluso un pequeño porcentaje de estos fallos se traduce en millones de respuestas inseguras cuando decenas de millones de personas hacen preguntas médicas cada mes.
Qué significa esto para el futuro de los asistentes de salud con IA
Los autores concluyen que los chatbots de propósito general de hoy no están listos para actuar como médicos en línea sin supervisión. Incluso el sistema con mejor rendimiento en el estudio produjo consejos inseguros con suficiente frecuencia como para ser preocupante a escala poblacional, y los cuatro mostraron puntos ciegos recurrentes en razonamiento clínico básico y recogida de historia. Sin embargo, el estudio no es puramente pesimista. El equipo sostiene que con mejor entrenamiento, controles de seguridad y diseños que obliguen a los modelos a formular preguntas aclaratorias, la IA podría eventualmente convertirse en un “médico en el bolsillo” poderoso que ayude a las personas a entender su salud sin sustituir a los clínicos reales. Hasta entonces, las respuestas de los chatbots deberían tratarse como iniciadores de conversación—no como decisiones médicas finales—y tanto los pacientes como los sistemas de salud deben reconocer tanto la promesa como los riesgos reales de esta nueva forma de buscar atención.
Cita: Draelos, R.L., Afreen, S., Blasko, B. et al. Large language models provide unsafe answers to patient-posed medical questions. npj Digit. Med. 9, 241 (2026). https://doi.org/10.1038/s41746-026-02428-5
Palabras clave: chatbots médicos, seguridad del paciente, inteligencia artificial en la atención sanitaria, grandes modelos de lenguaje, consejos de salud en línea