Clear Sky Science · es
Modelos de aprendizaje automático para la predicción de interacciones fármaco‑fármaco: del descubrimiento computacional a la aplicación clínica
Por qué combinar medicamentos puede ser arriesgado
La medicina moderna suele basarse en la administración simultánea de varios fármacos—para el cáncer, enfermedades del corazón, infecciones o simplemente para controlar las múltiples dolencias asociadas al envejecimiento. Pero cuando los medicamentos se encuentran en el organismo, pueden alterar los efectos de los demás, a veces reduciendo la eficacia del tratamiento o incluso provocando peligros. Esta revisión examina cómo la inteligencia artificial, en especial los métodos modernos de aprendizaje automático, se utiliza para predecir estas interacciones fármaco‑fármaco con antelación, de modo que los médicos puedan elegir combinaciones más seguras y adaptar los tratamientos a pacientes individuales.
Del ensayo y error a la seguridad basada en datos
Tradicionalmente, las combinaciones de fármacos preocupantes se han descubierto de forma dura—durante ensayos clínicos en fases avanzadas o después de que un medicamento ya esté en el mercado y provoque daños en pacientes. Las pruebas de laboratorio en células, animales y voluntarios siguen siendo el estándar, pero son lentas, costosas e imposibles de aplicar al enorme número de pares de fármacos potenciales. Los autores sostienen que la predicción computacional ofrece una salida a este cuello de botella. Aprendiendo a partir de grandes colecciones digitales de información sobre fármacos—como estructuras químicas, dianas en el organismo, efectos secundarios conocidos e informes de reacciones adversas en el mundo real—los sistemas de aprendizaje automático pueden señalar pares riesgosos mucho antes de que afecten a un gran número de pacientes.
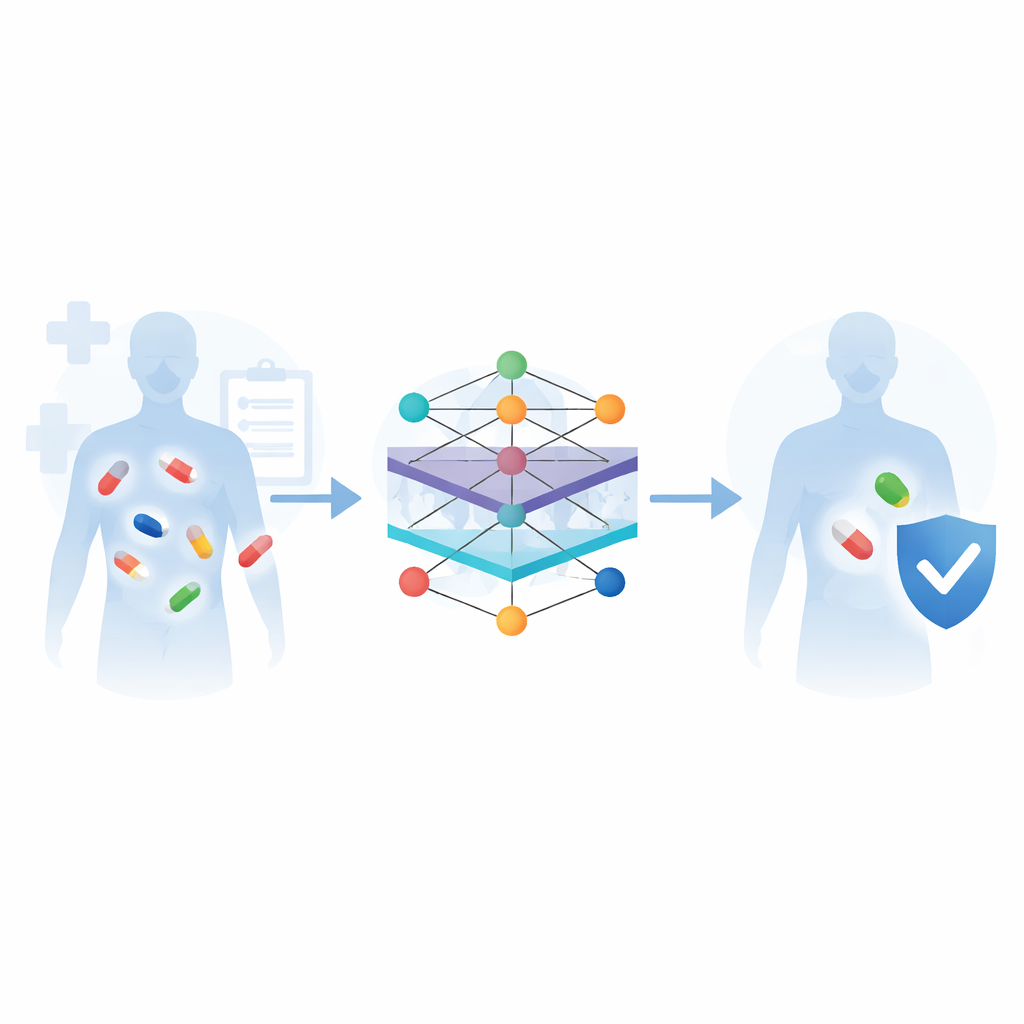
Cómo aprenden las máquinas a partir de diversos tipos de datos sobre fármacos
La revisión explica un flujo de trabajo común para estos sistemas de predicción. Primero se recopila información de grandes bases de datos biomédicos: bibliotecas químicas que describen la apariencia de cada molécula, mapas de vías que muestran cómo se procesan los fármacos en el organismo y listas curadas de interacciones y efectos secundarios conocidos. A continuación, los algoritmos convierten esta información en patrones numéricos que las máquinas pueden entender—por ejemplo, midiendo la similitud entre dos fármacos o representando cada fármaco como un nodo en una red conectado a sus dianas, vías y reacciones previas. Luego se entrenan distintos modelos de aprendizaje automático para reconocer qué pares de fármacos tienden a causar problemas, y su rendimiento se evalúa con conjuntos de referencia usando medidas estándar de precisión.
Diversas familias de algoritmos abordan el problema a su manera
Dado que las interacciones entre fármacos son complejas, ningún tipo de modelo es óptimo para todas las situaciones. Algunos enfoques se basan en clasificadores tradicionales que trabajan con características diseñadas manualmente, mientras que otros aprenden directamente de la estructura de las moléculas o de la red de conexiones entre fármacos y entidades biológicas. Los métodos basados en grafos y en aprendizaje profundo han sido especialmente exitosos: tratan a los fármacos y sus relaciones como una red, lo que permite al algoritmo "razonar" sobre cadenas de conexiones que podrían ser invisibles para modelos más simples. Otras estrategias comparten información entre tareas relacionadas, como predecir tanto si dos fármacos interactúan como qué tipo de efecto producen, lo que ayuda cuando los datos escasean. El artículo también destaca direcciones nuevas, como los grandes modelos de lenguaje que leen textos científicos y notas clínicas, y los modelos generativos que exploran posibles patrones de interacción en conjuntos de datos muy grandes y dispersos.
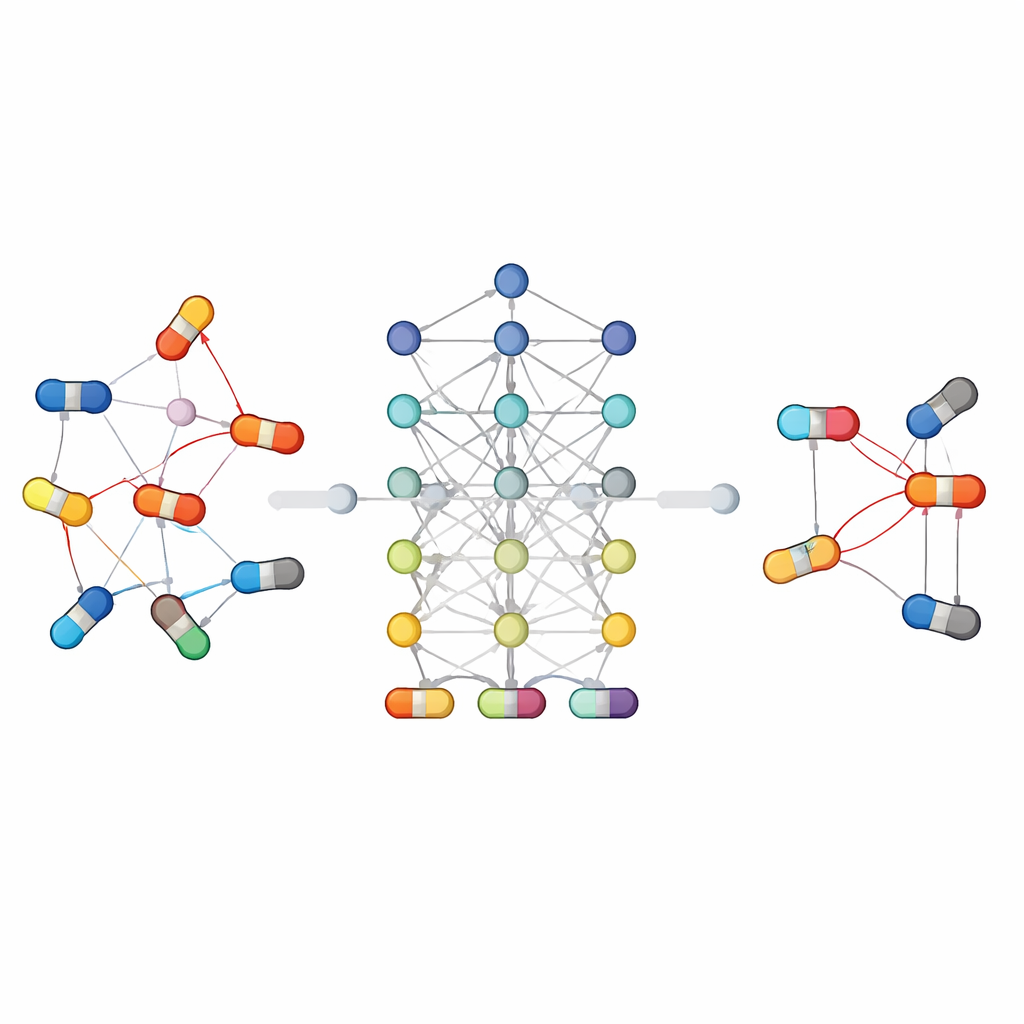
Vinculando las predicciones informáticas con pacientes reales
Más allá de los métodos, el artículo enfatiza cómo estas herramientas pueden apoyar la atención clínica real. Los autores discuten cómo los modelos entrenados con bases de datos curadas y registros clínicos pueden alertar a los clínicos sobre combinaciones peligrosas en el punto de atención, ayudar a diseñar regímenes multi‑fármaco más seguros en oncología, cardiología e infecciones, y priorizar qué interacciones predichas merecen pruebas en el laboratorio. También repasan ejemplos clínicos clásicos—como antibióticos que alteran los niveles de fármacos que reducen el colesterol, analgésicos que se anulan entre sí o zumos de frutas que aumentan inesperadamente las concentraciones de fármacos—para mostrar las muchas vías por las que surgen las interacciones. Los sistemas de aprendizaje automático que capturan estos patrones pueden actuar así como dispositivos de alerta temprana, especialmente en pacientes mayores que toman múltiples medicamentos.
Desafíos en el camino hacia una IA confiable para medicamentos
A pesar de una precisión impresionante en conjuntos de prueba, los autores subrayan que los modelos actuales aún enfrentan obstáculos importantes antes de poder confiarse ampliamente en la práctica clínica. Muchos son "cajas negras" que ofrecen poca información sobre por qué se considera riesgoso un par específico, lo que dificulta que los médicos evalúen o expliquen la recomendación. Los modelos pueden fallar cuando los datos son ruidosos o están desequilibrados—por ejemplo, cuando las interacciones perjudiciales son raras en comparación con los pares seguros. Integrar información de la química, la genética, los registros electrónicos de salud y la literatura publicada es técnicamente difícil, y los marcos regulatorios exigen pruebas sólidas antes de que tales herramientas puedan influir en la prescripción. Los autores argumentan que el trabajo futuro debe centrarse en modelos más interpretables, un mejor manejo de datos sesgados e incompletos, y sistemas que puedan aprender continuamente de nueva experiencia clínica respetando las normas de privacidad y seguridad.
Qué significa esto para el tratamiento cotidiano
En términos sencillos, esta revisión muestra que la inteligencia artificial se está convirtiendo en un aliado potente para mantener seguras las combinaciones farmacológicas. Al cribar montañas de datos digitales muy por encima de lo que cualquier experto humano podría manejar, los modelos de aprendizaje automático pueden destacar pares peligrosos, sugerir alternativas más seguras y apoyar prescripciones más personalizadas. Estas herramientas no sustituirán el juicio clínico ni las pruebas de laboratorio cuidadosas, pero pueden ayudar a que la creciente complejidad de la terapia moderna no se traduzca en un coste para la seguridad del paciente.
Cita: Lu, Y., Chen, J., Fan, N. et al. Machine learning models for drug-drug interaction prediction from computational discovery to clinical application. npj Digit. Med. 9, 198 (2026). https://doi.org/10.1038/s41746-026-02400-3
Palabras clave: interacciones fármaco‑fármaco, aprendizaje automático en medicina, redes neuronales gráficas, farmacología clínica, seguridad de la inteligencia artificial