Clear Sky Science · es
Los grandes modelos de lenguaje mejoran la transferibilidad de predicciones basadas en registros electrónicos de salud entre países y sistemas de codificación
Por qué importa compartir mejor los datos médicos
Hospitales y clínicas de todo el mundo albergan una mina de información: registros electrónicos de salud que capturan diagnósticos, tratamientos y resultados de las personas a lo largo de muchos años. En teoría, esta información podría ayudar a los médicos a identificar tempranamente a quienes tienen alto riesgo de enfermedades graves, mucho antes de que los síntomas sean evidentes. En la práctica, sin embargo, los modelos informáticos actuales tienen dificultades para “viajar” de un país o sistema hospitalario a otro porque cada lugar registra los datos de salud de forma distinta. Este estudio presenta un nuevo enfoque, llamado GRASP, que aprovecha avances en inteligencia artificial para salvar esas diferencias y lograr que un modelo entrenado en un sistema de salud funcione de manera fiable en otros.
Diferentes hospitales, diferentes lenguajes
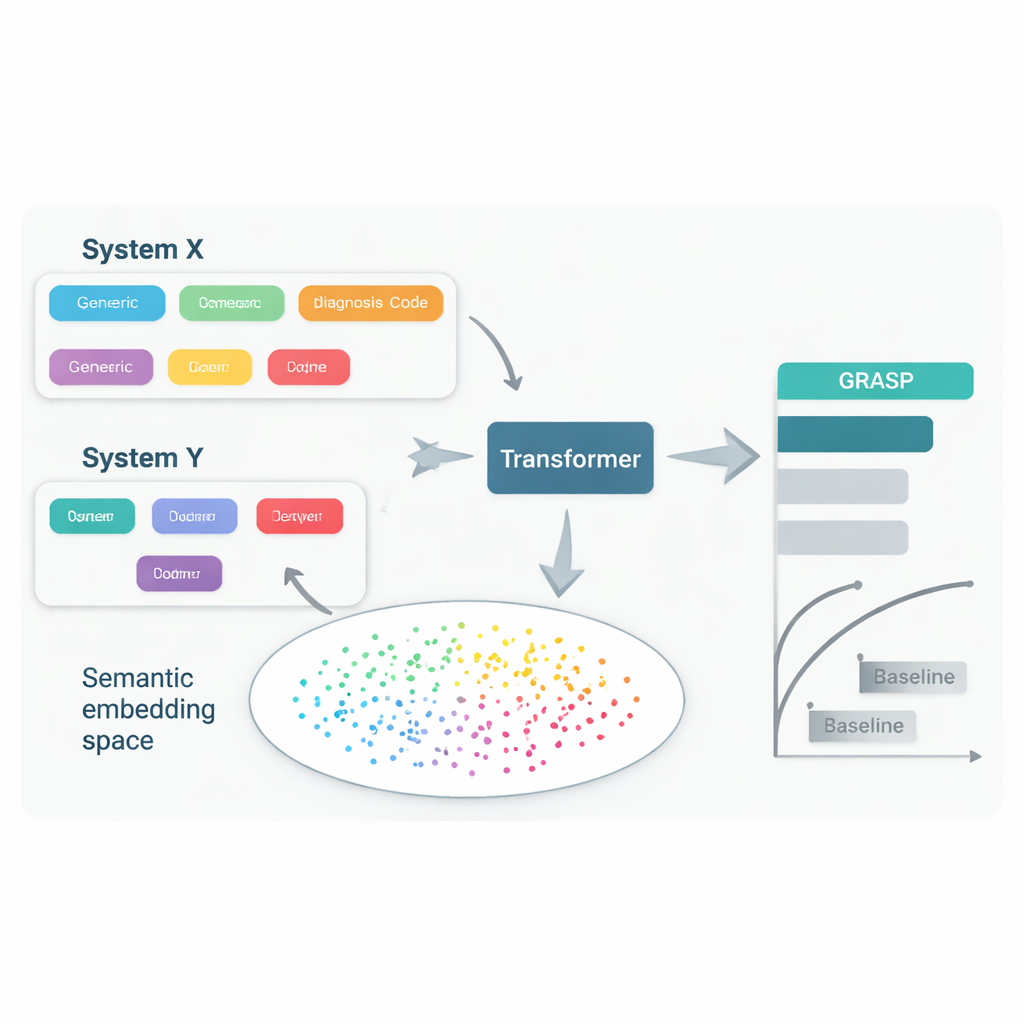
Aun cuando los médicos tratan la misma enfermedad, a menudo usan distintos sistemas de códigos y costumbres locales para registrarla en la historia clínica. Un hospital puede guardar “azúcar en sangre alta” bajo un código, otro usar “hiperglucemia” con un código distinto, y un tercero emplear un sistema completamente distinto. Los esfuerzos por imponer un único estándar común —como grandes esquemas internacionales de codificación— son útiles pero lentos, costosos y aún dejan diferencias importantes. Como resultado, un modelo informático que predice enfermedades a partir de los registros de un país puede perder precisión cuando se aplica en otro, limitando quién puede beneficiarse de estas herramientas.
Permitir que la IA lea el significado, no solo el código
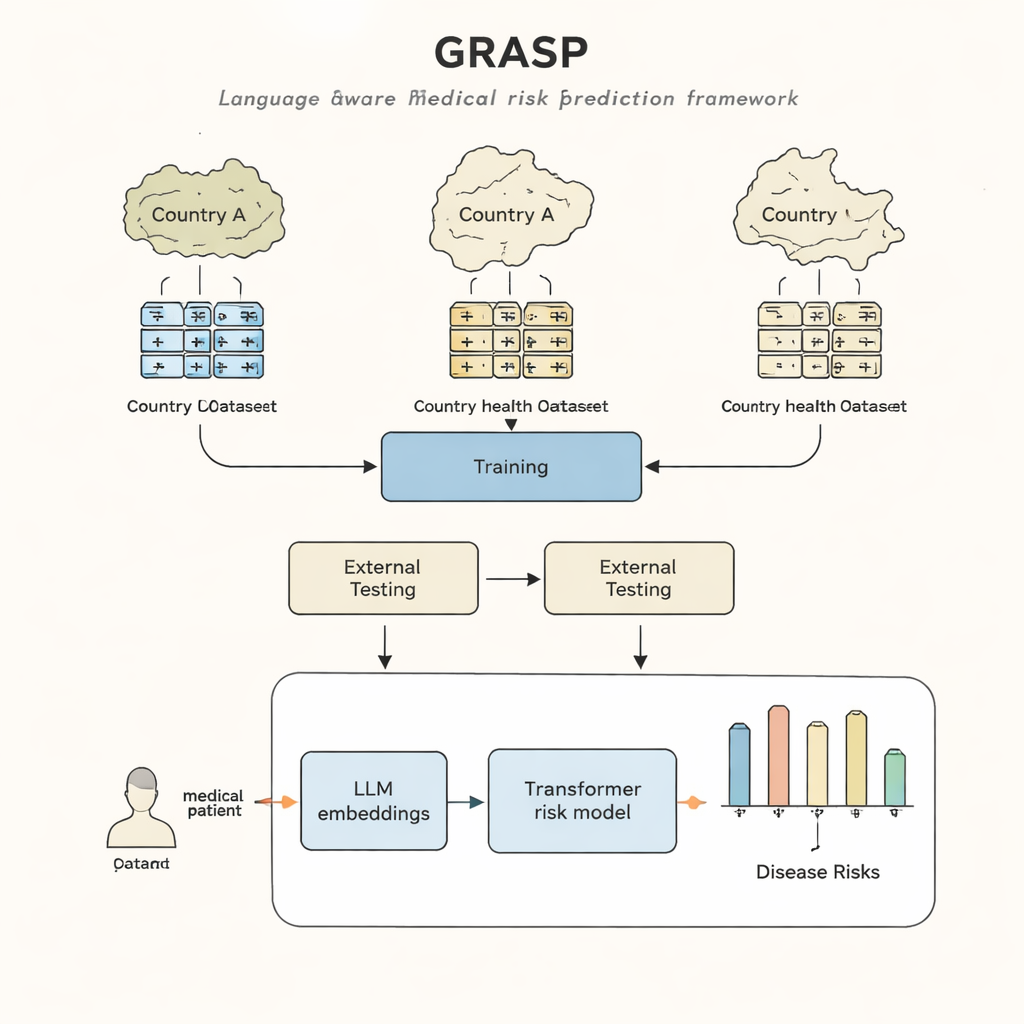
El enfoque GRASP parte de una idea simple: en lugar de tratar cada código médico como un número de identificación sin sentido, dejar que un gran modelo de lenguaje lea la descripción humana que hay detrás, por ejemplo “infección aguda del tracto respiratorio superior”, y convierta ese significado en un “embedding” numérico. Estos embeddings sitúan conceptos relacionados cerca unos de otros en un espacio compartido, aunque procedan de distintos sistemas de codificación o países. GRASP pre-calcula dichos embeddings para millones de términos médicos estándar y los almacena en una tabla de consulta. La historia médica de un paciente se representa entonces como una serie de estos vectores ricos, que se introducen en una red transformadora —un tipo de red neuronal adecuada para manejar colecciones de entradas diversas— para estimar el riesgo de esa persona de 21 enfermedades principales, además del riesgo global de muerte.
Pruebas entre países y sistemas de registro
Los investigadores entrenaron GRASP usando datos de casi 400 000 participantes del UK Biobank, y luego lo evaluaron sin volver a entrenarlo en dos entornos muy diferentes: el proyecto FinnGen en Finlandia y una gran red hospitalaria en la ciudad de Nueva York. GRASP igualó o superó a alternativas sólidas, incluidos un método popular llamado XGBoost y un transformador similar que no usaba embeddings basados en lenguaje. En Finlandia, GRASP tuvo un rendimiento especialmente bueno, mostrando mejoras claras en afecciones como asma, enfermedad renal crónica e insuficiencia cardiaca. De forma llamativa, incluso cuando los datos hospitalarios estadounidenses se dejaron en un esquema de codificación distinto en lugar de convertirse a un estándar compartido, GRASP siguió ofreciendo mejores predicciones que solo con datos demográficos, porque podía alinear los códigos únicamente comprendiendo el texto de sus descripciones.
Obtener más con menos datos
Otra ventaja de GRASP es la eficiencia. Dado que el modelo de lenguaje ya ha aprendido que muchos conceptos médicos están relacionados, la red de predicción no necesita redescubrir estos vínculos desde cero. Cuando los autores entrenaron GRASP con subconjuntos mucho más reducidos de los datos del Reino Unido —hasta solo 10 000 personas—, aún superó a los modelos competidores entrenados con las mismas muestras limitadas, tanto en el Reino Unido como al transferirse al extranjero. Las puntuaciones de riesgo de GRASP también se alinearon más estrechamente con el riesgo genético hereditario de varias enfermedades, lo que sugiere que captura aspectos más profundos de la susceptibilidad a la enfermedad en lugar de limitarse a memorizar patrones de un único conjunto de datos.
Qué significa esto para la atención futura
Para no especialistas, el mensaje clave es que GRASP demuestra cómo la IA moderna basada en lenguaje puede ayudar a distintos sistemas de salud a “hablar el mismo idioma” sin obligarlos a adoptar un único esquema rígido de codificación. Al leer el significado de los términos médicos, GRASP puede generar predicciones de riesgo de enfermedad que generalizan mejor entre países y formatos de registros, y puede hacerlo con menos ejemplos de pacientes. Si bien el método aún requiere pruebas cuidadosas, recalibración y comprobaciones de equidad antes de su uso en la atención cotidiana, apunta hacia un futuro en el que herramientas de riesgo potentes desarrolladas en un lugar puedan compartirse de forma segura y eficiente con hospitales y clínicas de todo el mundo.
Cita: Kirchler, M., Ferro, M., Lorenzini, V. et al. Large language models improve transferability of electronic health record-based predictions across countries and coding systems. npj Digit. Med. 9, 177 (2026). https://doi.org/10.1038/s41746-026-02363-5
Palabras clave: registros electrónicos de salud, predicción de riesgo de enfermedad, grandes modelos de lenguaje, compartición de datos médicos, IA en la atención sanitaria