Clear Sky Science · es
Comparación entre aprendizaje automático descentralizado y modelos clínicos de IA frente a alternativas locales y centralizadas: una revisión sistemática
Por qué importa compartir conocimientos médicos sin compartir los datos
La medicina moderna depende cada vez más de la inteligencia artificial para detectar enfermedades antes, elegir el tratamiento adecuado y predecir quién tiene mayor riesgo. Sin embargo, las mejores herramientas de IA necesitan enormes cantidades de datos de pacientes, y los hospitales no pueden simplemente agrupar sus historiales por leyes de privacidad estrictas y preocupaciones éticas. Este artículo revisa más de una década de investigación sobre el aprendizaje “descentralizado”: formas para que los hospitales entrenen IA de forma conjunta sin compartir nunca los datos en bruto de los pacientes, y plantea una pregunta práctica: ¿cómo rinden en la realidad estos métodos que preservan la privacidad en comparación con los enfoques tradicionales?
Nuevas formas de aprender de los pacientes protegiendo la privacidad
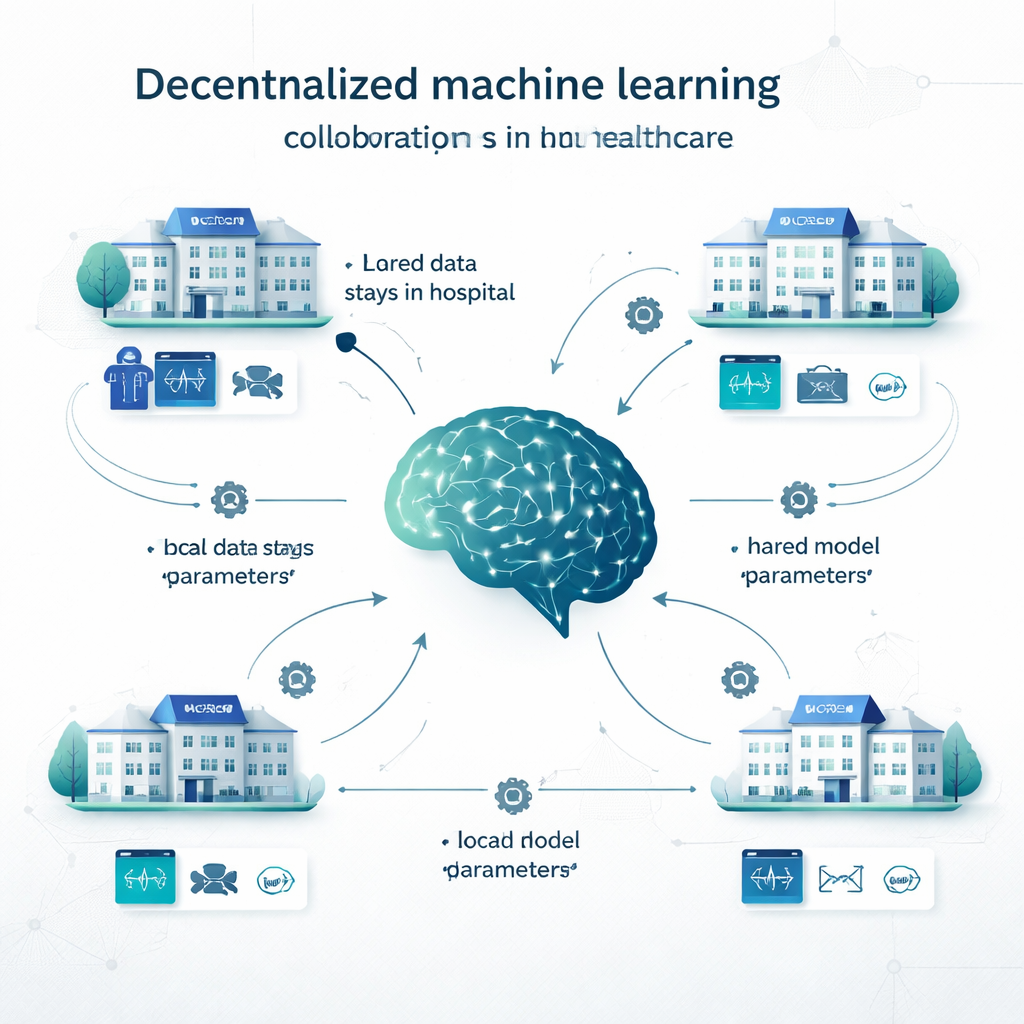
En el aprendizaje centralizado tradicional, los hospitales copian todos sus datos en una gran base de datos y entrenan un único modelo allí. En el aprendizaje local, cada institución construye su propio modelo con sus propios datos, sin colaboración. El aprendizaje descentralizado ofrece un camino intermedio. En el aprendizaje federado, por ejemplo, cada hospital entrena un modelo localmente y luego solo se envían los parámetros del modelo (como los “mandos” de una red neuronal) para combinarse en un modelo compartido; los historiales de pacientes nunca abandonan la sede. El swarm learning elimina el coordinador central y permite que las instituciones intercambien actualizaciones de modelos directamente. Otros enfoques descentralizados combinan predicciones de múltiples modelos locales o dividen el modelo entre sitios. Estos métodos se han probado en problemas que van desde la detección de cáncer y el diagnóstico de COVID‑19 hasta enfermedades cardíacas, diabetes, trastornos cerebrales y afecciones psiquiátricas.
Qué examinaron los investigadores
Los autores buscaron sistemáticamente en 11 bases de datos principales y cribaron 165 010 estudios publicados entre 2012 y marzo de 2024. Tras eliminar duplicados y trabajos que no implicaban decisiones clínicas reales, quedaron 160 artículos. En conjunto, estos trabajos reportaron 710 modelos descentralizados y 8 149 comparaciones directas de rendimiento frente a modelos centralizados o locales. La mayoría de los estudios se centró en el diagnóstico, pero también hubo muchos sobre segmentación de imágenes (por ejemplo, delinear tumores), predicción de resultados futuros como supervivencia o complicaciones, y tareas combinadas. Los tipos de datos abarcaron casi todas las fuentes principales usadas en medicina: historias clínicas electrónicas, tomografías y resonancias, radiografías, diapositivas de patología digital, señales cardíacas y cerebrales e incluso datos genéticos.
Cómo se comparan los modelos que preservan la privacidad con la IA centralizada
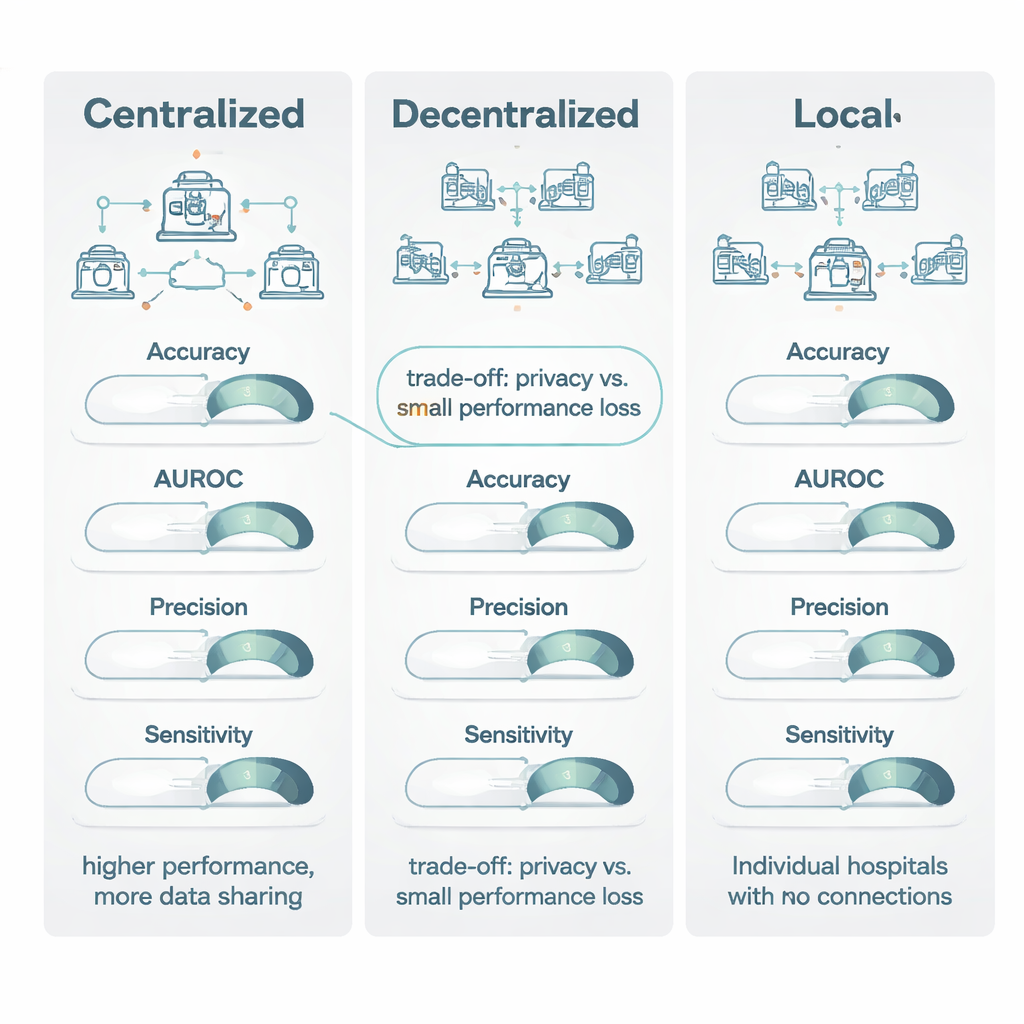
Cuando se compararon modelos descentralizados con modelos centralizados entrenados con datos agrupados, el aprendizaje centralizado generalmente salió ligeramente por delante. Funcionó especialmente bien en medidas basadas en umbrales, como la exactitud y una métrica de imagen habitual llamada coeficiente Dice, ganando en aproximadamente tres cuartas partes de los casos y por una diferencia suficiente como para considerarse una ventaja moderada a grande. Sin embargo, para medidas de tipo ranking —como el área bajo la curva ROC (AUROC), que captura qué tan bien un modelo ordena a los pacientes de menor a mayor riesgo—, los modelos descentralizados y centralizados estuvieron mucho más cerca, con una pequeña ventaja para el entrenamiento centralizado. Es importante destacar que cuando ambos modelos alcanzaron lo que los autores denominan rendimiento “viable clínicamente” (una puntuación de al menos 0,80), la ganancia habitual del modelo centralizado fue modesta: a menudo menos de 1–1,5 puntos porcentuales. En muchas situaciones esto equivalía a “excelente frente a aceptable”, no a “útil frente a inútil”.
Por qué el aprendizaje descentralizado supera al trabajo en solitario
La señal más fuerte en la revisión surgió al comparar modelos descentralizados con modelos puramente locales. En todos los principales indicadores —exactitud, AUROC, puntuación F1, sensibilidad, especificidad y especialmente precisión—, los métodos descentralizados casi siempre rindieron mejor, a menudo por un margen amplio. En pruebas cara a cara, el aprendizaje descentralizado superó a los modelos locales en más del 80 % de las comparaciones para medidas clave como exactitud, precisión y AUROC. En muchos casos, los modelos locales no alcanzaron el umbral de 0,80 para la utilidad clínica, mientras que el modelo descentralizado correspondiente lo superó con holgura, mejorando la sensibilidad hasta en 27 puntos porcentuales. Los autores atribuyen esto a la experiencia más amplia que obtienen los modelos multisede: al “ver” patrones de muchos hospitales, se evitan mejor las particularidades locales de ciertos escáneres o registros y se detectan con más precisión los rasgos de la enfermedad que realmente generalizan.
Equilibrar rendimiento, privacidad y uso práctico
La revisión concluye que el aprendizaje centralizado sigue siendo el estándar de oro cuando las normas de privacidad y la logística permiten combinar datos y cuando importa cada fracción de punto porcentual en el rendimiento, como ocurre con enfermedades muy raras. No obstante, el aprendizaje descentralizado ofrece una alternativa potente y clínicamente aceptable para situaciones en las que el intercambio de datos está restringido por leyes como el RGPD y la Ley de IA de la UE, o por políticas institucionales. En comparación con mantener los modelos totalmente locales, los enfoques descentralizados proporcionan grandes mejoras tanto en precisión como en fiabilidad, manteniendo los datos dentro de las paredes del hospital. Los autores señalan que trabajos futuros deberían informar con mayor claridad sobre las técnicas de privacidad y los costes computacionales, para que los sistemas de salud puedan tomar decisiones informadas sobre cuándo compensan las pequeñas pérdidas de rendimiento los beneficios sustanciales en privacidad y colaboración.
Cita: Diniz, J.M., Vasconcelos, H., Rb-Silva, R. et al. Comparing decentralized machine learning and AI clinical models to local and centralized alternatives: a systematic review. npj Digit. Med. 9, 174 (2026). https://doi.org/10.1038/s41746-025-02329-z
Palabras clave: aprendizaje federado, IA en salud, privacidad de datos médicos, aprendizaje automático descentralizado, modelos de predicción clínica