Clear Sky Science · es
Generalización de la segmentación automática de tumores en imágenes de diapositivas completas histopatológicas a través de múltiples tipos de cáncer
Por qué esto importa para la atención del cáncer
El diagnóstico del cáncer sigue dependiendo de que expertos examinen con detenimiento las laminillas de tejido teñido bajo el microscopio, una tarea que consume mucho tiempo y que se complica por el aumento de casos y la escasez de patólogos. Este estudio plantea una pregunta sencilla pero potente: ¿puede un único sistema de inteligencia artificial localizar de forma fiable las áreas cancerosas en imágenes digitales de microscopio para muchos tipos de tumor distintos, en lugar de construir una herramienta separada para cada cáncer? Si es así, podría aliviar la carga de trabajo, acelerar el diagnóstico y extender análisis avanzados incluso a cánceres menos frecuentes donde los datos son escasos.
De las laminillas a los asistentes digitales
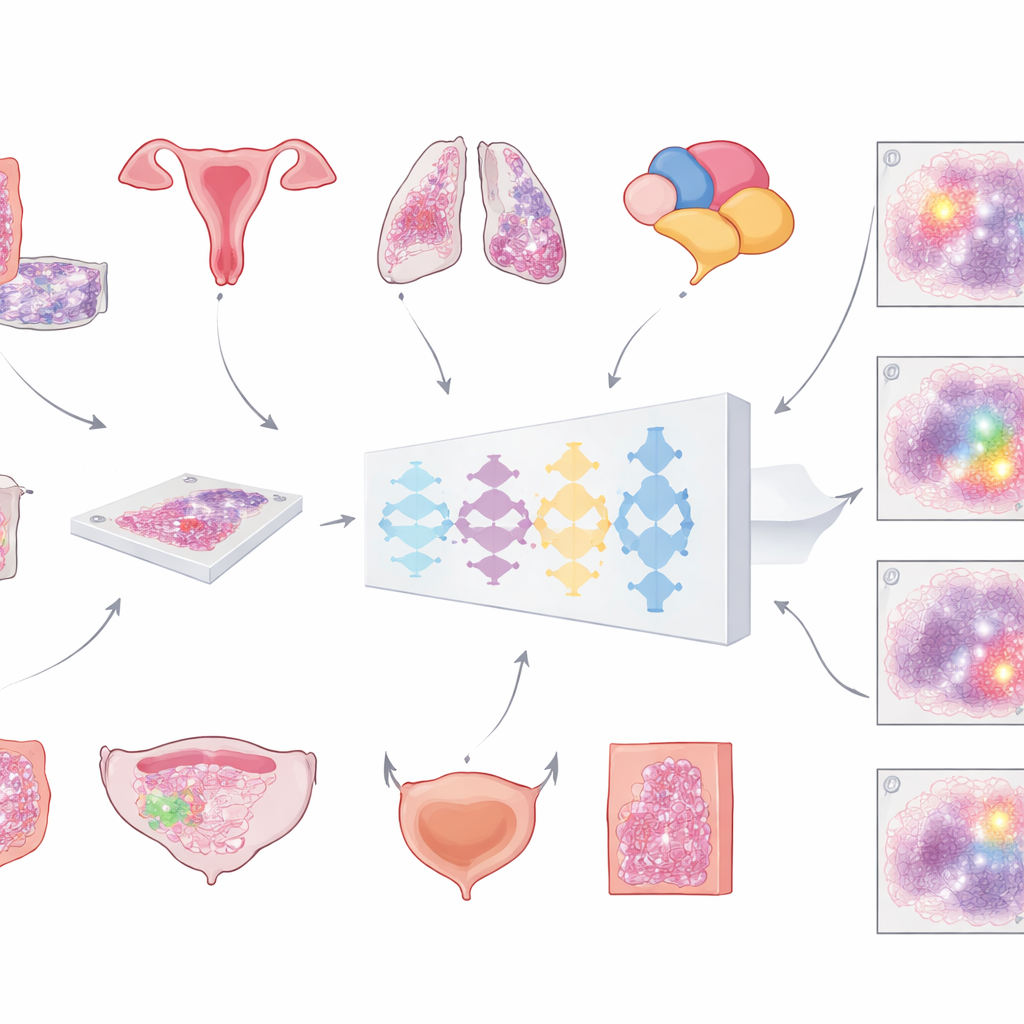
Los hospitales modernos escanean cada vez más las laminillas de microscopio para crear enormes y detalladas “imágenes de diapositiva completa” de los tumores. El primer paso crucial para cualquier análisis asistido por ordenador es separar el tejido canceroso de todo lo demás: células normales, grasa, vidrio vacío y artefactos. Hasta ahora, la mayoría de las herramientas automatizadas se han entrenado en un solo tipo de cáncer, lo que limita su aplicabilidad. El equipo detrás de este trabajo se propuso construir un único modelo universal capaz de detectar regiones tumorales en múltiples cánceres comunes en laminillas teñidas con los tintes rutinarios de hematoxilina y eosina. Su objetivo fue una herramienta general que pudiera integrarse en muchos flujos de trabajo diagnósticos sin rediseñarla cada vez.
Entrenar un modelo para ver muchos cánceres
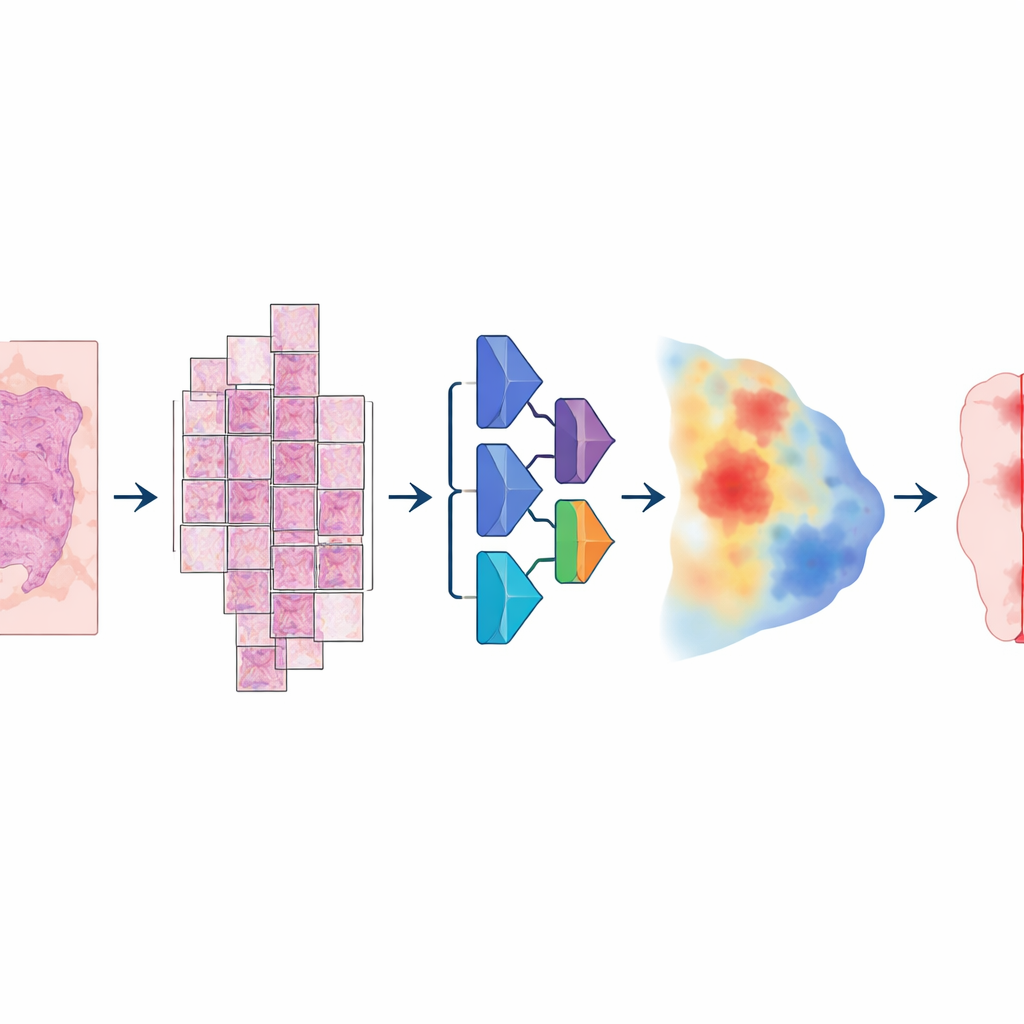
Para construir este modelo, los investigadores reunieron una colección inusualmente grande y variada de diapositivas digitales: más de 20.000 imágenes de diapositiva completa procedentes de más de 4.000 pacientes con cáncer colorrectal, endometrial, de pulmón y de próstata. Todas las muestras provenían de tejido fijado en formalina e incluido en parafina, escaneado en dos escáneres de alta resolución distintos. Un patólogo delineó cuidadosamente las áreas tumorales en cada laminilla, proporcionando la “verdad de referencia” con la que el ordenador aprendió. El modelo siguió una canalización en varios pasos: cada imagen enorme se dividió en grandes fragmentos solapados, se pasó por una red neuronal profunda que estimaba, para cada píxel, la probabilidad de ser tumor, y luego se recompuso en un mapa suave que finalmente se convirtió en una máscara limpia de tumor frente a no tumor.
Poner el sistema a prueba
De forma crucial, el equipo no se limitó al rendimiento en el entrenamiento. Probaron el mismo modelo en más de 3.000 pacientes adicionales en seis tipos de cáncer —incluyendo cáncer de mama y de vejiga que nunca se usaron en el entrenamiento— y en laminillas procedentes de varios hospitales y escáners. La precisión se midió principalmente con una puntuación estándar de solapamiento (el coeficiente Dice), que alcanza el 100% cuando el contorno tumoral del ordenador coincide perfectamente con el del patólogo. Para muestras tumorales grandes e intactas en cáncer colorrectal, endometrial, de pulmón, de próstata y de mama, el solapamiento medio superó el 80% y a menudo el 90%. En grandes colecciones externas de The Cancer Genome Atlas, procedentes de muchos laboratorios y escáneres en todo el mundo, el rendimiento volvió a mantenerse por encima del 80%, lo que sugiere que el modelo se generaliza bien más allá de su institución de origen.
Dónde tiene dificultades y cómo se compara
La principal debilidad surgió en cánceres de vejiga en estadios tempranos muestreados mediante un procedimiento que produce piezas de tejido diminutas y fragmentadas. En estos casos, el modelo a menudo no marcó ningún tumor, especialmente cuando el área cancerosa era muy pequeña. Sin embargo, cuando detectó tumor, el solapamiento con los contornos del patólogo fue alto, y ajustes sencillos en los umbrales finales mejoraron los resultados, lo que sugiere que la red subyacente reconocía el patrón pero el posprocesado era demasiado estricto. Los investigadores también entrenaron cuatro modelos “especialistas”, cada uno dedicado a un único tipo de cáncer, y encontraron que ninguno superó de forma significativa al modelo general en su propio dominio. En contraste, estos sistemas especialistas fracasaron en gran medida cuando se aplicaron a otros tipos de cáncer, mientras que el modelo general se mantuvo robusto. Frente a una herramienta de segmentación médica popular y más genérica que requiere indicaciones del usuario, el nuevo modelo normalmente rindió igual o mejor y, además, es totalmente automático.
Qué significa esto para pacientes y médicos
Para quienes no son expertos, la idea principal es que un sistema de IA bien diseñado puede resaltar de forma fiable el tejido canceroso en diapositivas digitales a través de varios tipos tumorales importantes, sin necesidad de versiones a medida para cada enfermedad o escáner. No sustituye al patólogo, pero puede premarcar regiones con probabilidad de tumor, apoyar mediciones coherentes y liberar a los especialistas para que se concentren en los casos más difíciles. La versión actual sigue pasando por alto algunos tumores muy pequeños o en estadios tempranos —particularmente muestras fragmentadas de vejiga y, probablemente, otros tejidos tipo biopsia—, por lo que aún no es adecuada para detectar las trazas más débiles de cáncer. No obstante, el estudio demuestra que la segmentación tumoral amplia, “pancáncer”, es factible en condiciones del mundo real y puede constituir un primer paso sólido para futuras herramientas automatizadas que evalúen el grado de malignidad, predigan la respuesta al tratamiento o guíen terapias de precisión.
Cita: Skrede, OJ., Pradhan, M., Isaksen, M.X. et al. Generalisation of automatic tumour segmentation in histopathological whole-slide images across multiple cancer types. npj Precis. Onc. 10, 107 (2026). https://doi.org/10.1038/s41698-026-01311-6
Palabras clave: patología digital, aprendizaje profundo, segmentación de tumores, imágenes de diapositivas completas, modelo pancáncer