Clear Sky Science · es
IMFLKD: un mecanismo de incentivos para aprendizaje federado descentralizado basado en destilación de conocimiento
Por qué compartir puede ser seguro y justo
La inteligencia artificial moderna se nutre de datos, pero la mayor parte de nuestros datos reside en teléfonos personales, servidores hospitalarios o nubes corporativas que no pueden copiarse y compartirse libremente. El aprendizaje federado ofrece una vía para que muchos dispositivos entren un modelo compartido sin exponer sus datos en bruto, pero los sistemas actuales todavía presentan fugas de privacidad, puntos centrales de fallo e incentivos injustos para quienes más contribuyen. Este artículo presenta un nuevo marco, IMFLKD, que combina tres ideas potentes —blockchain, destilación de conocimiento y puntuación de reputación— para que este tipo de aprendizaje colectivo sea más privado, más robusto y más justo a largo plazo.
Entrenar juntos sin compartir secretos
En el aprendizaje federado clásico, un servidor central recoge actualizaciones de modelos de muchos participantes y las combina. Esto evita que los datos en bruto circulen, pero convierte al servidor en un objetivo atractivo: si falla, todo el sistema se paraliza, y si es poco fiable, puede usar o filtrar información oculta en las actualizaciones del modelo. Los autores utilizan en su lugar un libro mayor descentralizado (blockchain) para coordinar el entrenamiento. Cada participante entrena un modelo local con sus propios datos y luego interactúa con contratos inteligentes en la blockchain que registran contribuciones, agregan información y distribuyen recompensas, todo sin depender de una autoridad central única.
Compartir conocimiento, no modelos pesados
Para reducir costes de comunicación y proteger más la privacidad, el marco se apoya en la destilación de conocimiento. En lugar de enviar parámetros completos del modelo, cada participante envía solo "etiquetas suaves" —las probabilidades predichas por el modelo para un conjunto de entradas compartidas— que son mucho más ligeras y revelan menos sobre los datos de una sola persona. Dado que puede no existir un conjunto de datos compartido real, el sistema emplea un modelo generativo llamado autoencoder variacional condicional para crear un conjunto de datos sintético "pseudo-público" que aproxima la distribución global de etiquetas sin exponer registros originales. Los participantes entrenan con sus propios datos, hacen predicciones sobre este conjunto sintético y luego refinan sus modelos usando una señal agregada derivada del conocimiento combinado de todos.
Medir quién realmente aporta
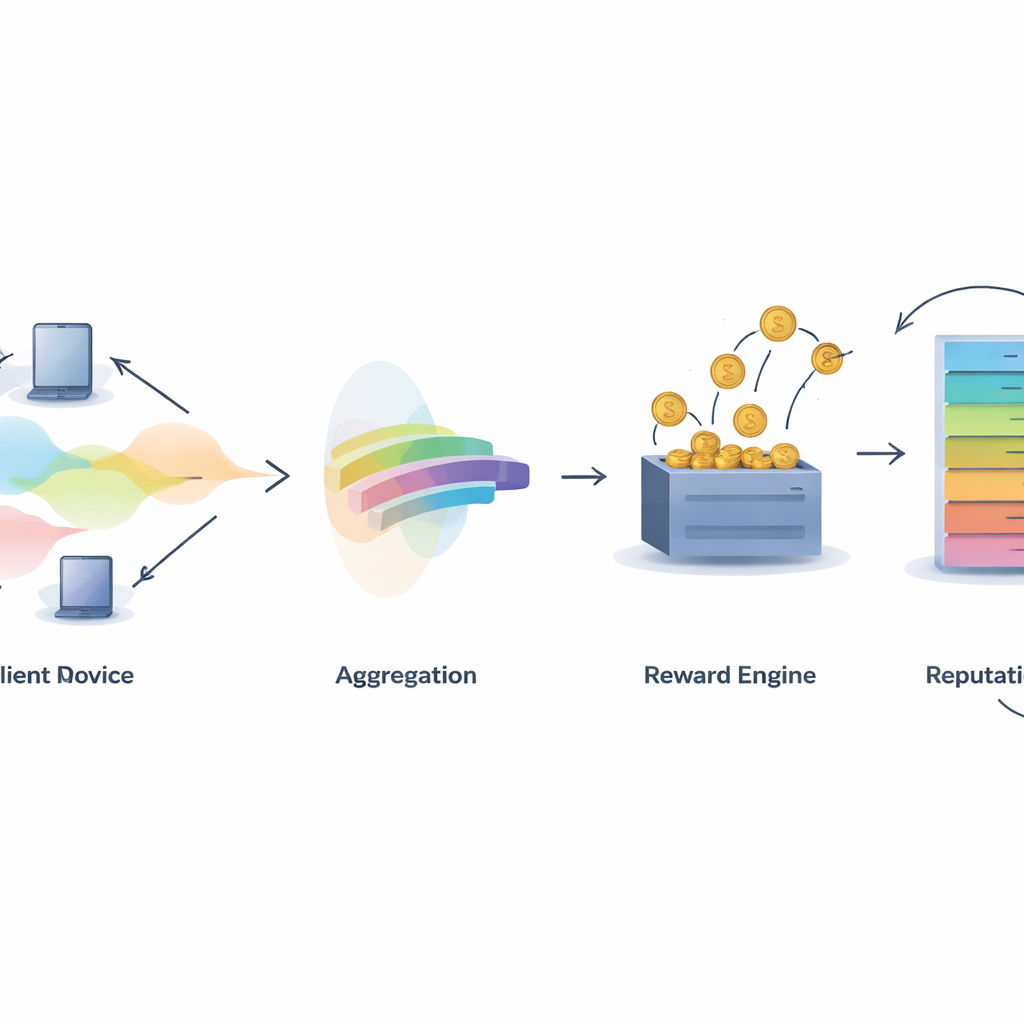
Un reto central en cualquier sistema colaborativo es decidir quién merece crédito. IMFLKD aborda esto con un método de evaluación de contribuciones en dos etapas basado en la agregación de etiquetas. Primero, un algoritmo bayesiano ligero examina las predicciones de todos los participantes e infiere tanto la etiqueta más probable para cada muestra como una puntuación de calidad para cada modelo, actualizando estas puntuaciones a medida que llegan más tareas. Este enfoque funciona en línea, sin almacenar datos pasados, y gestiona contribuidores ruidosos o maliciosos reduciendo el peso de los modelos que a menudo discrepan con el consenso emergente. Los experimentos muestran que esta agregación de etiquetas mejora la precisión en torno al 10% frente a una votación mayoritaria simple, y a la vez es lo suficientemente rápido para entornos a gran escala y con recursos limitados.
Convertir calidad en recompensas y reputación
Una vez conocida la calidad de la contribución, IMFLKD utiliza un esquema de incentivos llamado "suerum de verdad entre pares ponderado" para transformarla en recompensas. Los participantes se comparan con un consenso entre pares ponderado por calidad: quienes alinean sus predicciones con pares de alta calidad ganan más, mientras que quienes se desvían o discrepan con frecuencia son penalizados. Esto hace que la honestidad sea la estrategia más rentable a largo plazo, incluso frente a la colusión. Además, el sistema construye una puntuación de reputación multidimensional para cada participante, combinando calidad de datos, nivel de actividad y estabilidad conductual, y ajustando comportamientos antiguos con un factor de decaimiento temporal. La reputación retroalimenta las rondas posteriores influyendo en cuánto pesan las predicciones de un participante y si es seleccionado para tareas futuras.
Construir confianza en la inteligencia colectiva
En conjunto, el marco IMFLKD demuestra que es posible coordinar el aprendizaje entre muchos dispositivos independientes de manera eficiente, consciente de la privacidad y resistente a aprovechados y atacantes. Al combinar generación de datos sintéticos, puntuación rigurosa de contribuciones, recompensas basadas en teoría de juegos y seguimiento dinámico de reputación sobre una blockchain, el sistema incentiva a los participantes a comportarse de forma honesta y consistente a lo largo de múltiples rondas de entrenamiento. Para el lector general, la conclusión es que podemos aprovechar el poder colectivo de datos distribuidos —como historiales médicos, lecturas de sensores o dispositivos personales— sin entregarlo todo a una única empresa o servidor, y aun así garantizar que quienes proporcionan la información más útil sean los que más se beneficien.
Cita: Ying, X., Yan, K., Gao, X. et al. IMFLKD: an incentive mechanism for decentralized federated learning based on knowledge distillation. Sci Rep 16, 10567 (2026). https://doi.org/10.1038/s41598-026-46234-1
Palabras clave: aprendizaje federado, blockchain, destilación de conocimiento, mecanismos de incentivos, sistemas de reputación