Clear Sky Science · es
Entrenamiento híbrido evolutivo‑gradiente mejora la predicción a largo plazo de series temporales
Por qué importan mejores predicciones a largo plazo
Desde la demanda eléctrica y el tráfico en autopistas hasta los tipos de cambio y el tiempo local, nuestras vidas están moldeadas por sistemas que evolucionan con el tiempo. Pronosticar con precisión esos patrones días o semanas adelante puede ahorrar energía, reducir la congestión y aumentar la resiliencia de las empresas. Pero cuanto más lejos miramos, más difícil resulta para las herramientas de inteligencia artificial actuales lidiar con condiciones cambiantes, mediciones ruidosas y presupuestos de cómputo limitados. Este artículo presenta una nueva manera de entrenar modelos de predicción para que se mantengan precisos y estables incluso cuando el mundo se niega a quedarse quieto.
Aprender de muchos modelos en lugar de solo uno
La mayoría de los pronosticadores de series temporales modernos confían en una única red neuronal profunda entrenada con descenso de gradiente, el método estándar que ajusta los parámetros paso a paso para reducir el error. Eso funciona bien cuando los datos se comportan de forma consistente, pero puede fallar cuando las condiciones derivan, las mediciones son ruidosas o el tiempo de entrenamiento es escaso. En lugar de inventar un nuevo diseño de red, los autores proponen Fusion de Módulos Guiada por Evolución con Refinamiento por Gradiente (EGMF‑GR), un marco de entrenamiento que puede envolver arquitecturas existentes. La idea clave es mantener una pequeña “población” de modelos que comparten la misma estructura pero parten de inicializaciones aleatorias distintas. Durante el entrenamiento, esos modelos exploran distintas formas de ajustarse a los datos, y el que mejor rinde en cada momento se usa para guiar mejoras en los demás.
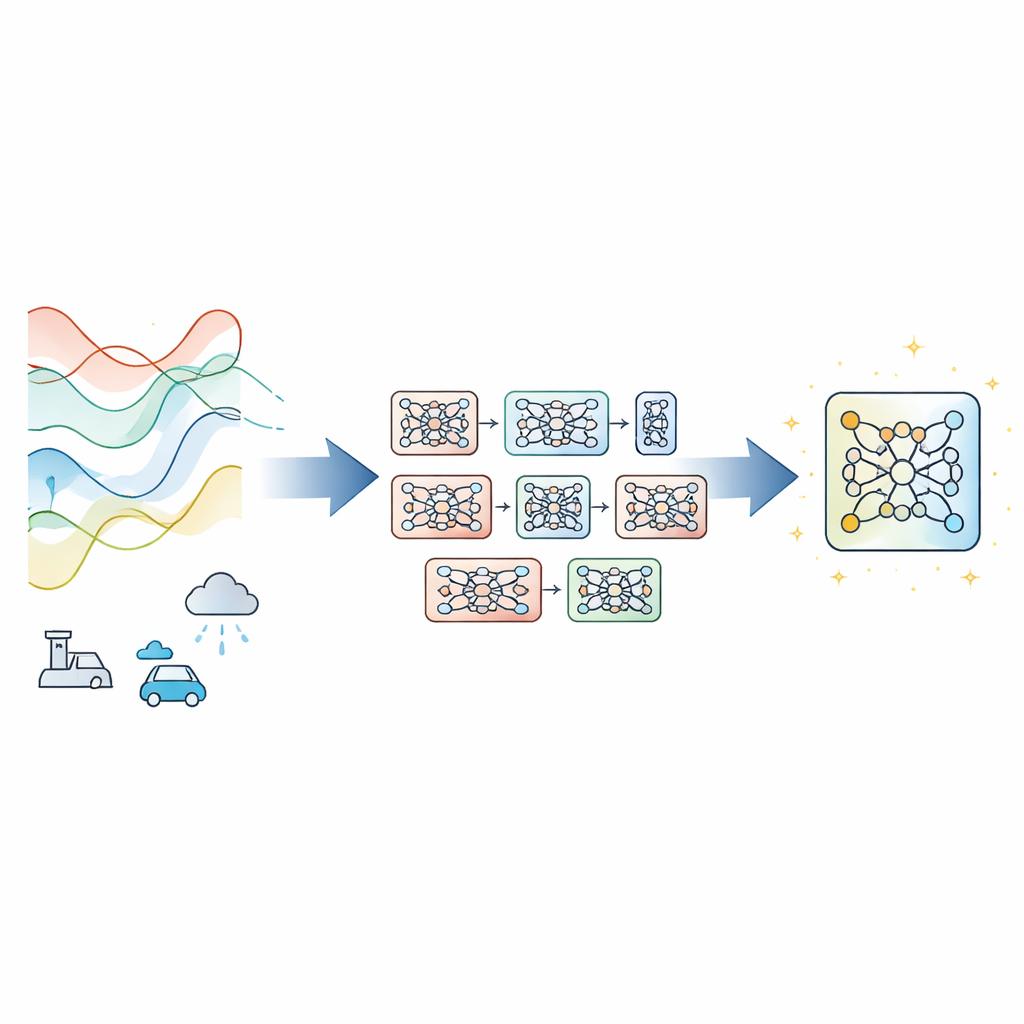
Tomar buenas partes preservando la diversidad útil
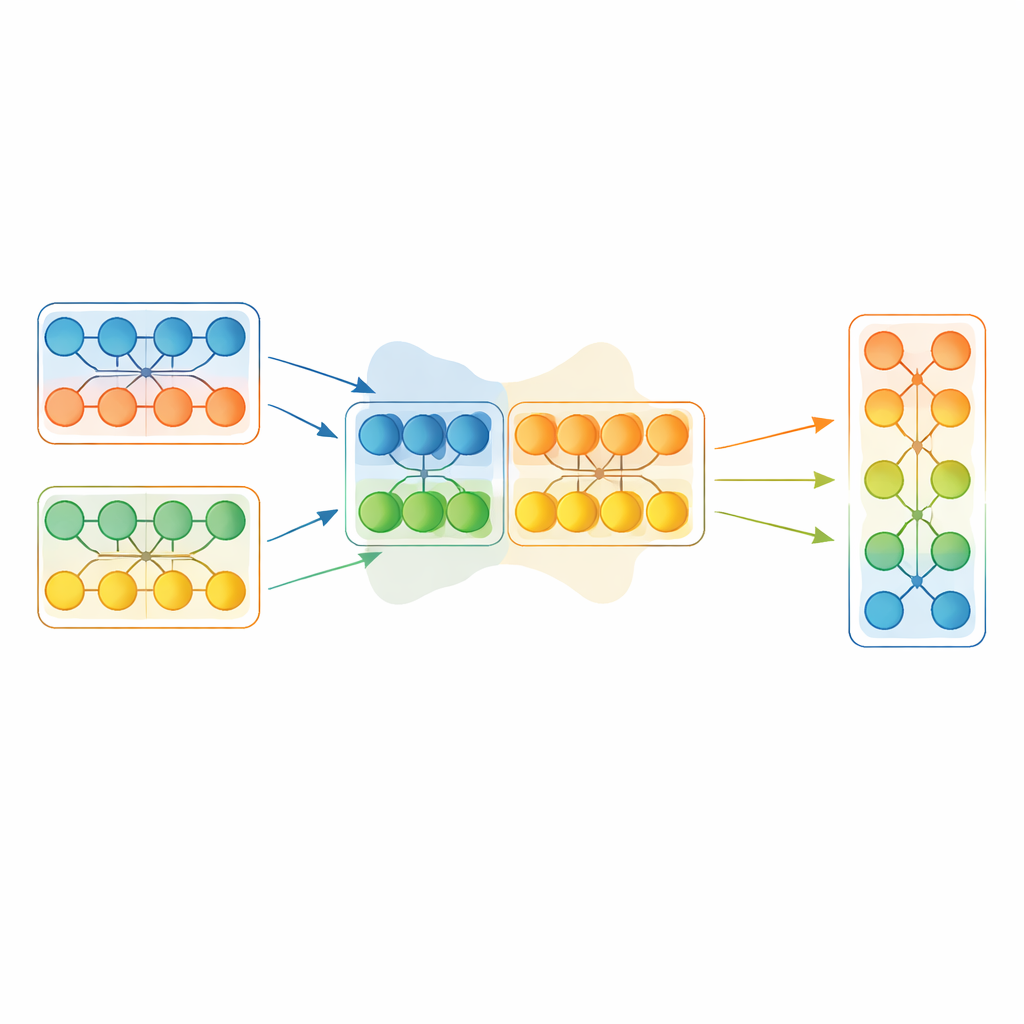
En vez de copiar íntegramente un modelo ganador, EGMF‑GR opera a nivel de módulos —bloques repetidos dentro de una red, como pilas de capas. Para cada modelo de la población, el marco alinea módulos correspondientes con los del modelo actual mejor clasificado y compara sus señales internas mientras procesan el mismo lote de entrada. Emplea varias medidas simples de diferencia que capturan tanto cómo se moldean los patrones de actividad como su magnitud. Esas discrepancias módulo‑a‑módulo se resumen, y solo los módulos cuyo comportamiento se considera valores atípicos respecto a sus pares se contemplan para actualización. Cuando eso ocurre, el módulo rezagado se empuja hacia el módulo correspondiente del mejor modelo mediante una mezcla ponderada de sus parámetros, más una pequeña perturbación aleatoria para preservar la diversidad.
Dejar que los gradientes ordenen las cosas después de los grandes movimientos
Combinar partes de diferentes redes puede introducir cambios bruscos. Para evitar desestabilizar el entrenamiento, cada modelo fusionado pasa luego por una breve fase convencional de descenso de gradiente sobre los datos de entrenamiento. Este paso de refinamiento permite que la red se readapte suavemente a su nueva configuración interna mientras conserva los beneficios del conocimiento prestado. El procedimiento general alterna: seleccionar el modelo actual mejor en base a una porción reservada de datos, fusionar selectivamente módulos de ese líder en el resto de la población y afinar brevemente a todos con gradientes. Crucialmente, el método también sincroniza estados internos de mantenimiento, como promedios móviles usados por ciertas capas, que a menudo se ignoran en esquemas de fusión más simples pero pueden influir mucho en la estabilidad.
Demostrando las ganancias en muchas señales del mundo real
Para probar el marco, los autores aplicaron EGMF‑GR a varias arquitecturas de referencia de pronóstico populares, incluidos modelos tipo Transformer y un diseño reciente basado en convoluciones, sin cambiar sus estructuras centrales. Evaluaron el rendimiento en ocho conjuntos de referencia públicos que abarcan uso de energía, flujo de tráfico, tipos de cambio y clima, y en múltiples horizontes de predicción que van desde unas horas hasta varios días. Bajo un presupuesto estrictamente igualado de costosas actualizaciones con retropropagación, el entrenamiento híbrido redujo de forma consistente los errores de predicción y suavizó el comportamiento del entrenamiento en la mayoría de las combinaciones modelo‑conjunto de datos, especialmente en entornos de alta dimensión o ruidosos. El equipo también comparó su enfoque con trucos habituales de modelo único, como promedios móviles exponenciales y promedio estocástico de pesos, y encontró que la fusión de módulos basada en población aportó beneficios adicionales más allá del simple suavizado de pesos.
Mantenerse fiable cuando las condiciones empeoran
Los sistemas reales rara vez se comportan como ejemplos de libro, por lo que los autores también evaluaron la robustez en escenarios más duros: entradas artificialmente corruptas, fragmentos de datos faltantes y periodos en los que la dinámica subyacente cambia de forma abrupta. EGMF‑GR ayudó claramente cuando las entradas eran ruidosas o parcialmente ausentes, lo que sugiere que tomar el comportamiento estable de módulos del mejor modelo actual puede contrarrestar fallos locales. Durante cambios repentinos de régimen, la ventaja fue menor, lo que indica que un alineamiento excesivo a veces puede ralentizar la adaptación a nuevos patrones. Esto apunta a refinamientos futuros en los que se atenúe la intensidad de la fusión cuando el entorno se vuelve altamente volátil.
Qué significa esto para las herramientas de predicción cotidianas
En términos sencillos, el estudio muestra que entrenar muchas versiones cooperantes del mismo modelo de predicción, y permitir que compartan solo las partes que realmente destacan como mejores, puede hacer que las predicciones a largo plazo sean más precisas y más estables sin rediseñar los modelos. EGMF‑GR funciona como un deporte en equipo disciplinado: los miembros ocasionalmente adoptan los movimientos más fuertes de los demás y luego practican un poco por su cuenta para ajustarse al juego presente. Para los practicantes, esto ofrece una estrategia de entrenamiento plug‑in que puede reforzar los sistemas de pronóstico existentes en finanzas, energía, transporte y aplicaciones climáticas, especialmente cuando los datos están desordenados y los presupuestos de cómputo son limitados.
Cita: Zhao, L., Chen, Z., Wu, N. et al. Hybrid evolutionary-gradient training improves long-term time series forecasting. Sci Rep 16, 10697 (2026). https://doi.org/10.1038/s41598-026-45017-y
Palabras clave: predicción de series temporales, entrenamiento evolutivo, redes neuronales, fusión de modelos, desplazamiento de distribución