Clear Sky Science · es
Transformador de visión multiplano para la clasificación de hemorragias usando datos de RM axiales y sagitales
Por qué esta investigación importa para pacientes y médicos
Cuando alguien puede estar sufriendo un ictus o una hemorragia cerebral, cada minuto cuenta. Las exploraciones cerebrales pueden revelar hemorragias peligrosas, pero leer estas imágenes de forma rápida y precisa es un reto, especialmente en resonancia magnética (RM), que genera muchos tipos de imágenes en distintos planos. Este estudio presenta un nuevo método de inteligencia artificial (IA) diseñado para interpretar exploraciones de RM en múltiples ángulos de manera más parecida a un radiólogo experto, con el objetivo de detectar hemorragias cerebrales de forma más fiable en condiciones reales hospitalarias.
El desafío de encontrar sangrados cerebrales en la RM
La hemorragia intracraneal —el sangrado dentro del cráneo— es una emergencia que pone en riesgo la vida y exige un diagnóstico rápido. Durante décadas, la tomografía computarizada (TC) ha sido la herramienta de imagen principal para sospechas de hemorragia cerebral porque es rápida y relativamente fácil de interpretar. La RM puede igualar o incluso superar a la TC en la detección de hemorragias y es mejor para estimar la antigüedad del sangrado y revelar otros problemas, como áreas del cerebro con falta de riego. Sin embargo, la RM tarda más, está menos disponible en algunos centros y sus imágenes son más complejas de interpretar. Esa complejidad la convierte en un objetivo atractivo para herramientas de IA que ayuden a los radiólogos a cribar un gran número de exploraciones, señalar casos sospechosos y reducir el riesgo de pasar por alto un sangrado sutil pero crítico.
Por qué las vistas múltiples y los tipos de exploración son difíciles para los ordenadores
En la práctica clínica habitual, la RM cerebral a menudo se adquiere con cortes relativamente gruesos para acortar el examen, generando imágenes que son mucho más nítidas en unas direcciones que en otras. Los radiólogos examinan el cerebro en varios planos: axial (de arriba a abajo), sagital (de perfil) y, a veces, coronal (de frente), porque algunas hemorragias resultan más visibles desde determinados ángulos. Las exploraciones también vienen en varios “contrastes” o variedades, como FLAIR, difusión y susceptibilidad, cada uno destacando distintas propiedades del tejido. La mayoría de los sistemas de IA actuales, sin embargo, esperan que todas las imágenes estén alineadas en una única orientación estándar y a la misma resolución. Para cumplir ese requisito, los hospitales deben rotar y redimensionar los datos digitalmente, lo que puede difuminar detalles finos y ocultar pequeñas hemorragias. Los conjuntos de datos clínicos reales añaden otra complicación: no todos los pacientes se exploran con el mismo conjunto de contrastes, por lo que los modelos deben lidiar con piezas de información ausentes.
Un nuevo modelo de IA multiplano que conserva más de la imagen
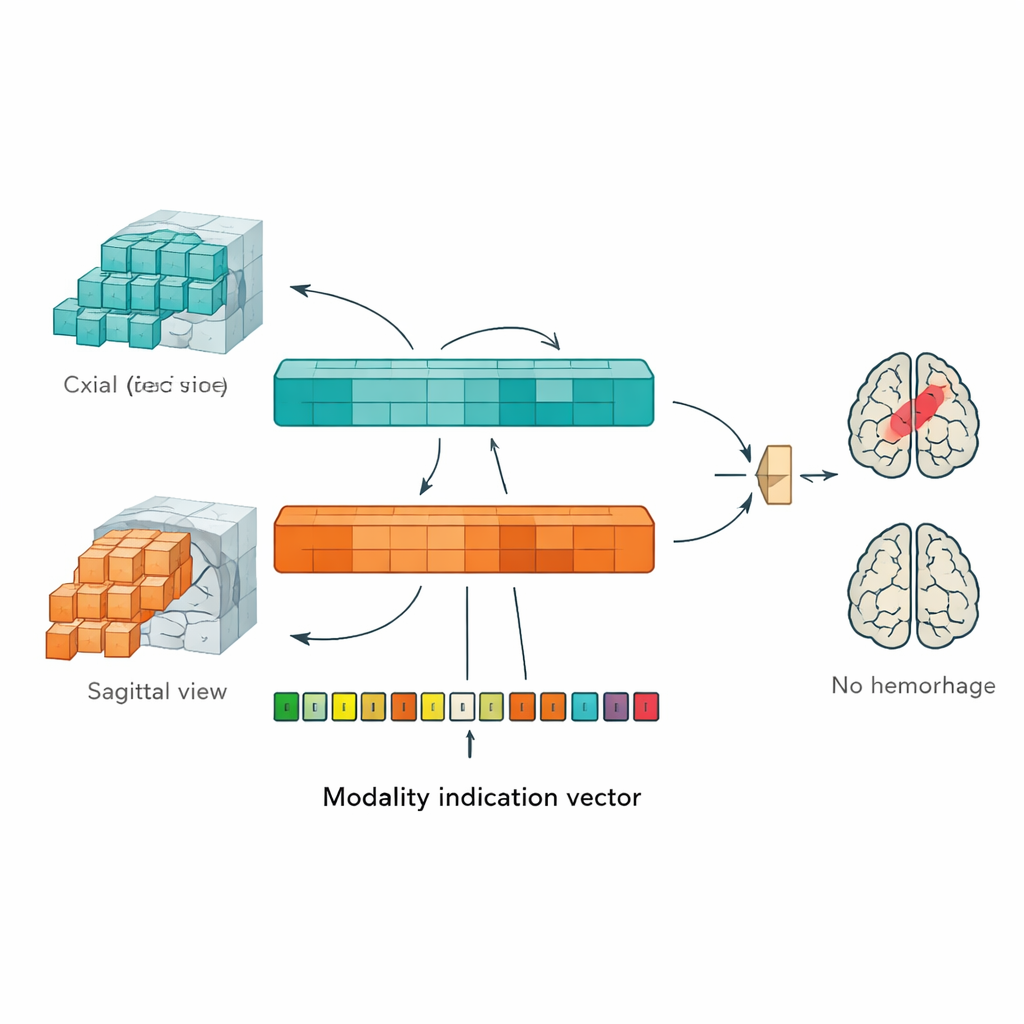
Para abordar estos problemas, los autores diseñaron un «transformador de visión multiplano» (MP-ViT), un tipo de IA originariamente desarrollado para entender imágenes naturales. En lugar de forzar todos los datos de RM a un único ángulo de visión, MP-ViT tiene dos ramas de procesamiento dedicadas: una para imágenes axiales y otra para imágenes sagitales. Cada rama divide el cerebro tridimensional en pequeños bloques, los convierte en tokens que el transformador puede procesar y aprende patrones que podrían indicar la presencia de una hemorragia. Crucialmente, estas ramas no funcionan simplemente en paralelo y de forma independiente. El modelo usa un mecanismo de atención cruzada para permitir que las dos ramas intercambien información, imitando cómo un radiólogo combina mentalmente vistas desde distintos ángulos para formarse una imagen global más clara del cerebro.
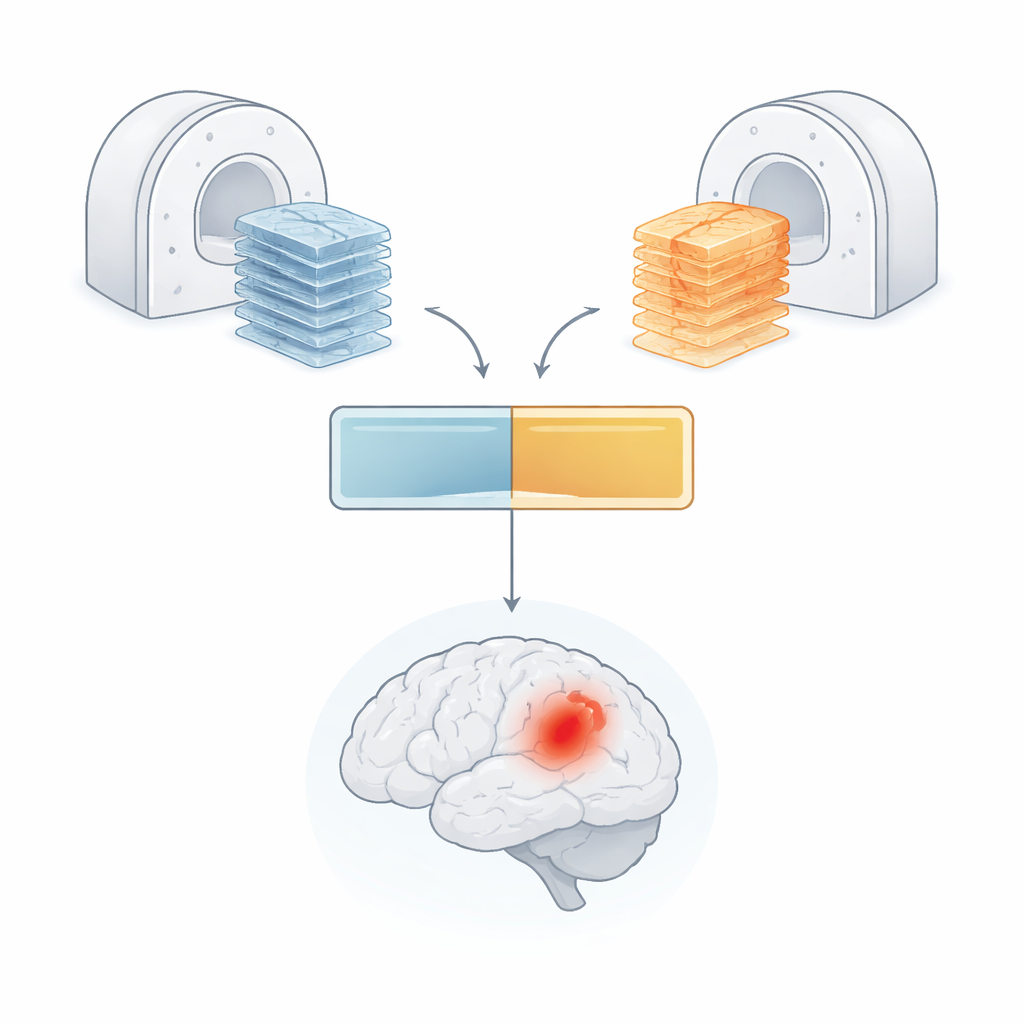
Manejar la ausencia de determinados tipos de exploración mediante una señal guía
En los flujos de trabajo hospitalarios reales, no todos los pacientes disponen del mismo conjunto de contrastes de RM; algunos pueden carecer de secuencias específicas sensibles al sangrado. Para hacer la IA robusta frente a estas lagunas, los autores añadieron un «vector de indicación de modalidad»: un código sencillo que le dice al modelo qué tipos de imágenes están presentes y cuáles faltan para un paciente dado. Ese vector se transforma en un conjunto de señales internas que interactúan con las características aprendidas por el modelo mediante un paso adicional de atención cruzada. En efecto, la red se guía para ajustar sus expectativas cuando ciertos tipos de información no están disponibles, en lugar de confundirse o mostrarse demasiado confiada. Este diseño hace que MP-ViT sea más adecuado para los datos desordenados e inconsistentes que aparecen en la práctica clínica diaria.
Qué tan bien funciona el nuevo método
Los investigadores entrenaron y evaluaron MP-ViT en un gran conjunto de datos del mundo real con más de 12.000 estudios de RM procedentes de tres fabricantes principales de equipos, etiquetados por radiólogos experimentados como que mostraban hemorragia intracraneal aguda o subaguda o no. En un conjunto de prueba independiente, MP-ViT alcanzó un área bajo la curva (AUC) de 0,854, una medida de cómo separa casos con hemorragia de los sin hemorragia en todos los umbrales de decisión posibles. Esta puntuación fue notablemente superior a la de un transformador de visión estándar que trabaja desde un solo plano, así como a la de varias arquitecturas de redes neuronales convolucionales conocidas, como ResNet y DenseNet. Pruebas estadísticas confirmaron que estas mejoras probablemente no se debieron al azar. Un análisis interno también mostró que incluir el vector de indicación de modalidad mejoró el rendimiento en más de un punto porcentual, subrayando el valor de decir explícitamente al modelo qué tipos de exploraciones tiene disponibles.
Qué podría significar esto para la atención futura
Para un público no especialista, la idea clave es que este estudio demuestra una forma más inteligente para que la IA lea exploraciones de RM: observa el cerebro desde más de un ángulo, conserva más del detalle original y se adapta cuando faltan ciertos tipos de imágenes. Aunque el trabajo se evaluó en un único conjunto de datos interno y se centró solo en la clasificación en lugar de en el contorno preciso de las hemorragias, muestra que los transformadores diseñados con cuidado pueden adaptarse mejor a la realidad desordenada de la imagen clínica. Si se validan de forma más amplia e integran responsablemente en los flujos de trabajo hospitalarios, métodos como MP-ViT podrían ayudar a los radiólogos a detectar hemorragias cerebrales con mayor fiabilidad tanto en situaciones de ictus de urgencia como en exploraciones ambulatorias de rutina, potencialmente aportando un tratamiento más rápido y resultados más seguros para los pacientes.
Cita: Das, B.K., Zhao, G., Mailhe, B. et al. Multi-plane vision transformer for hemorrhage classification using axial and sagittal MRI data. Sci Rep 16, 9333 (2026). https://doi.org/10.1038/s41598-026-44524-2
Palabras clave: hemorragia cerebral, RM, IA en imagen médica, transformador de visión, diagnóstico de accidente cerebrovascular