Clear Sky Science · es
Abordar el problema del desequilibrio de datos en el modelado mediante aprendizaje automático de eventos de corte de suministro raros y disruptivos
Por qué te importan mejores pronósticos de tormentas
Cuando una gran tormenta deja sin electricidad, lo vivimos de forma muy personal: sin luces, sin calefacción, comida estropeada y comunicaciones interrumpidas. Las compañías eléctricas intentan predecir estos cortes con antelación para desplegar cuadrillas de reparación y mantener a la gente a salvo. Pero las peores tormentas son raras, lo que significa que sorprendentemente hay pocos datos sobre ellas. Este artículo muestra cómo un nuevo tipo de inteligencia artificial puede “imaginar” tormentas raras realistas, rellenando los huecos en nuestros registros y haciendo que las previsiones de cortes sean más precisas justo cuando más importa.
El reto de aprender a partir de desastres poco frecuentes
La mayor parte de los cortes de suministro son causados por el tiempo, sobre todo huracanes, nor’easters, tormentas de nieve y hielo, y tormentas eléctricas severas. Estos fenómenos están intensificándose a medida que el clima se calienta, lo que aumenta la presión sobre redes eléctricas envejecidas. Sin embargo, las tormentas más dañinas son, por definición, poco comunes. Las herramientas estadísticas tradicionales y los modelos de aprendizaje automático tienden a aprender mejor a partir de las muchas tormentas leves y moderadas, y tienen dificultades con el pequeño número de casos verdaderamente extremos. Este desequilibrio en los datos conduce a subestimaciones del daño precisamente cuando las compañías eléctricas más necesitan orientación fiable.
Enseñar a los ordenadores a crear nuevas tormentas
Para superar este desequilibrio, los autores construyen un sistema que genera tormentas sintéticas, es decir, eventos creados por ordenador que parecen y se comportan como tormentas reales pero no son copias de ningún episodio pasado concreto. Se centran en Connecticut, representando cada tormenta como una rejilla de 815 celdas con 19 tipos de información por celda, incluyendo viento, lluvia, presión, turbulencia, vegetación y la disposición de las líneas eléctricas. Primero agrupan 294 tormentas históricas en 12 clústeres según cuántos y dónde ocurrieron los “puntos problemáticos” —localizaciones de daños que las cuadrillas deben reparar—. Las tormentas raras y de alto impacto acaban en cuatro clústeres pequeños que necesitan ser reforzados.
Cómo el nuevo modelo de IA construye extremos realistas
El núcleo del marco combina dos herramientas modernas de IA. Un autoencoder variacional comprime cada mapa de tormenta multilayer en una representación “latente” de menor dimensión que aún conserva patrones importantes, como vientos más fuertes cerca de la costa. Sobre este espacio comprimido, un modelo de difusión aprende a partir de ruido aleatorio y a refinarlo gradualmente hasta obtener una tormenta realista, condicionado por el clúster de severidad de cortes que se solicite. El sistema luego filtra las tormentas generadas usando un conjunto de métricas que comparan sus estadísticas con las de eventos reales—comprobando no solo características individuales como la velocidad del viento, sino también cómo las características se mueven conjuntamente, capturado por patrones de correlación. Solo se conservan las tormentas sintéticas que coinciden estrechamente con el comportamiento físico y estadístico de las tormentas reales de un clúster dado.
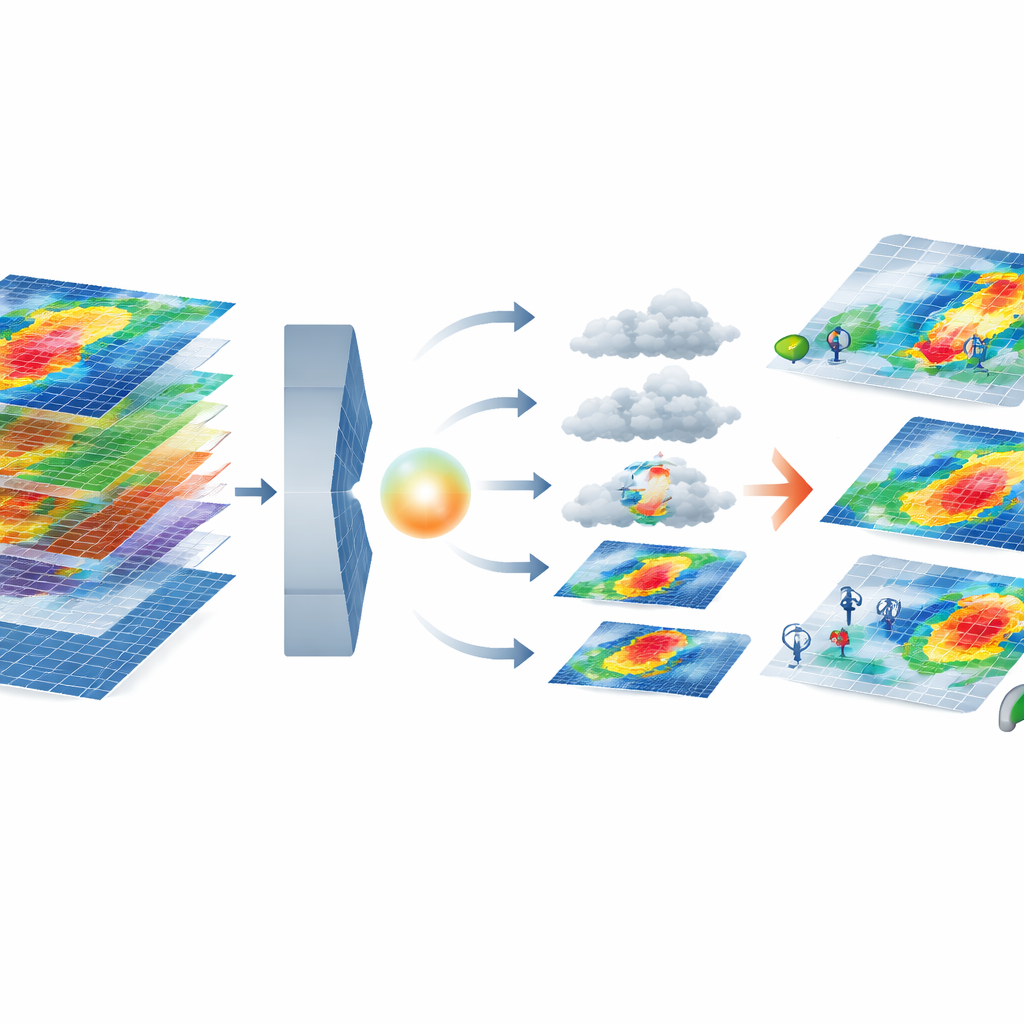
Poner a prueba las tormentas sintéticas
Los autores plantean entonces la pregunta crucial: ¿estas tormentas sintéticas realmente ayudan a predecir cortes? Entrenan un modelo existente de predicción de cortes dos veces—primero solo con tormentas reales y luego con los mismos datos enriquecidos con eventos sintéticos cuidadosamente filtrados para los clústeres raros y de alto impacto. Evalúan el rendimiento usando una prueba estricta de dejar-una-tormenta-fuera, que imita la previsión de eventos nuevos y no vistos. Con el enriquecimiento sintético, el error estructural del modelo cae bruscamente y el ajuste general mejora. Para las tormentas raras y más disruptivas, el error cuadrático medio central disminuye alrededor de un 45%, y las medidas resumen de habilidad como la eficiencia de Nash–Sutcliffe pasan de niveles peores que la línea base a un rendimiento claramente útil. Una comparación con una aumentación “aleatoria”, que añade tormentas sintéticas sin control de calidad, muestra ganancias mucho menores o incluso negativas, subrayando la importancia de un filtrado riguroso.
Qué implica esto para futuras tormentas
En términos sencillos, este estudio muestra que permitir que la IA invente tormentas extremas físicamente consistentes—y ser selectivo sobre en cuáles de esas tormentas inventadas se confía—puede hacer que las previsiones de cortes sean más fiables para los eventos que causan los mayores daños. Al enriquecer datos escasos sobre fenómenos meteorológicos raros pero devastadores, el enfoque ayuda a las compañías eléctricas a anticipar mejor cuántos puntos de daño deberán atender y dónde. Aunque se demuestra en un estado y para un tipo de peligro, la misma estrategia podría extenderse a incendios forestales, inundaciones y otras amenazas naturales, ofreciendo una nueva manera de reforzar la planificación de infraestructuras en un mundo con extremos climáticos crecientes.
Cita: Azizi, M., Zhang, X., Yasenpoor, T. et al. Addressing the data imbalance issue in machine learning modeling of rare and disruptive outage events. Sci Rep 16, 8876 (2026). https://doi.org/10.1038/s41598-026-41838-z
Palabras clave: datos sintéticos de tormentas, predicción de cortes de energía, modelos de difusión, fenómenos meteorológicos extremos, desequilibrio de datos