Clear Sky Science · es
Detección temprana de la enfermedad renal crónica basada en un modelo de aprendizaje automático mejorado con SURD
Por qué importa detectar los problemas renales de forma temprana
La enfermedad renal crónica suele avanzar de manera silenciosa, mostrando pocos signos de advertencia hasta que los riñones están gravemente dañados. Sin embargo, análisis simples de sangre y orina pueden revelar problemas años antes, cuando el tratamiento puede ralentizar o incluso prevenir un deterioro serio. Este estudio explora una nueva forma de analizar esos resultados rutinarios mediante modelos informáticos avanzados pero interpretables, de modo que las personas con alto riesgo puedan ser señaladas antes y los médicos puedan entender por qué.
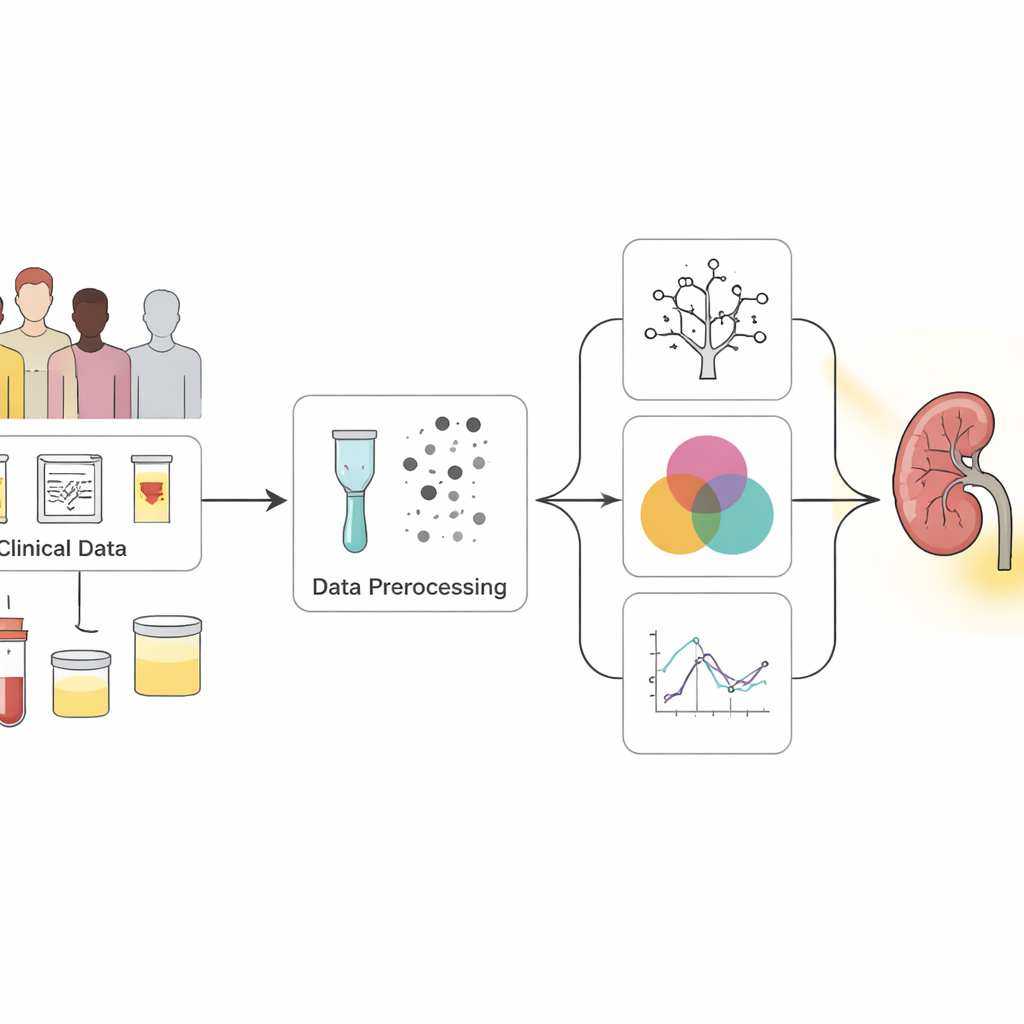
Convirtiendo datos de chequeos desordenados en señales claras
Los investigadores partieron de un conjunto de datos público ampliamente usado de 400 personas, la mayoría de las cuales ya habían sido diagnosticadas con enfermedad renal crónica. Cada persona tenía 25 mediciones, que iban desde presión arterial y recuentos sanguíneos hasta hallazgos en orina e historial médico como diabetes e hipertensión. Muchas entradas estaban incompletas, por lo que el equipo usó técnicas estadísticas cuidadosas para imputar los valores perdidos en lugar de descartar pacientes. También equilibraron los datos para que los casos sanos y enfermos estuvieran representados de forma más parecida, ayudando a los modelos informáticos a aprender a reconocer ambos grupos de manera justa.
Mirando más allá de las correlaciones simples
La mayoría de las herramientas de predicción médica tratan cada resultado de prueba por separado: examinan qué tan fuertemente una medición, como la glucemia, está vinculada con la enfermedad. Pero en el organismo, los factores de riesgo raramente actúan por separado. Algunas pruebas transmiten información casi idéntica, mientras que otras solo resultan informativas en combinación. Para capturar esto, los autores usaron un marco llamado SURD que descompone la contribución de cada variable en tres partes: información compartida con otras pruebas, información única e información que solo aparece cuando las variables actúan en conjunto. Esto les permitió agrupar valores de laboratorio y hallazgos clínicos en conjuntos “únicos”, “redundantes” y “sinérgicos” antes de introducirlos en los modelos de predicción.
Entrenando muchos modelos y eligiendo el más fiable
Con estos grupos de características basados en SURD, el equipo entrenó diez modelos de aprendizaje automático diferentes, desde árboles de decisión simples hasta enfoques más complejos como random forests y redes neuronales. Compararon el rendimiento cuando los modelos usaban todas las características disponibles frente a solo un conjunto combinado de las únicas y sinérgicas. En casi todos los tipos de modelo, este conjunto reducido guiado por SURD rindió tan bien o mejor que la colección completa de 25 variables, mejorando a menudo el equilibrio entre identificar correctamente a los pacientes enfermos y evitar falsas alarmas. En particular, modelos basados en árboles como random forests y árboles potenciados alcanzaron puntuaciones casi perfectas en el conjunto de datos original.
Probando el método en datos hospitalarios del mundo real
Un rendimiento excelente en un pequeño conjunto de referencia puede ser engañoso si un modelo falla al exponerse a pacientes más variados. Para evitar esto, los autores validaron su enfoque usando una base de datos hospitalaria mucho mayor de más de 27.000 pacientes de cuidados intensivos. Allí, el modelo de random forest construido sobre las características seleccionadas por SURD siguió distinguiendo con altísima precisión a pacientes con y sin enfermedad renal. Su rendimiento superó claramente al de un árbol de decisión más simple, lo que indica que el método puede generalizar más allá de un conjunto de investigación cuidadosamente curado hacia registros del mundo real, más heterogéneos.
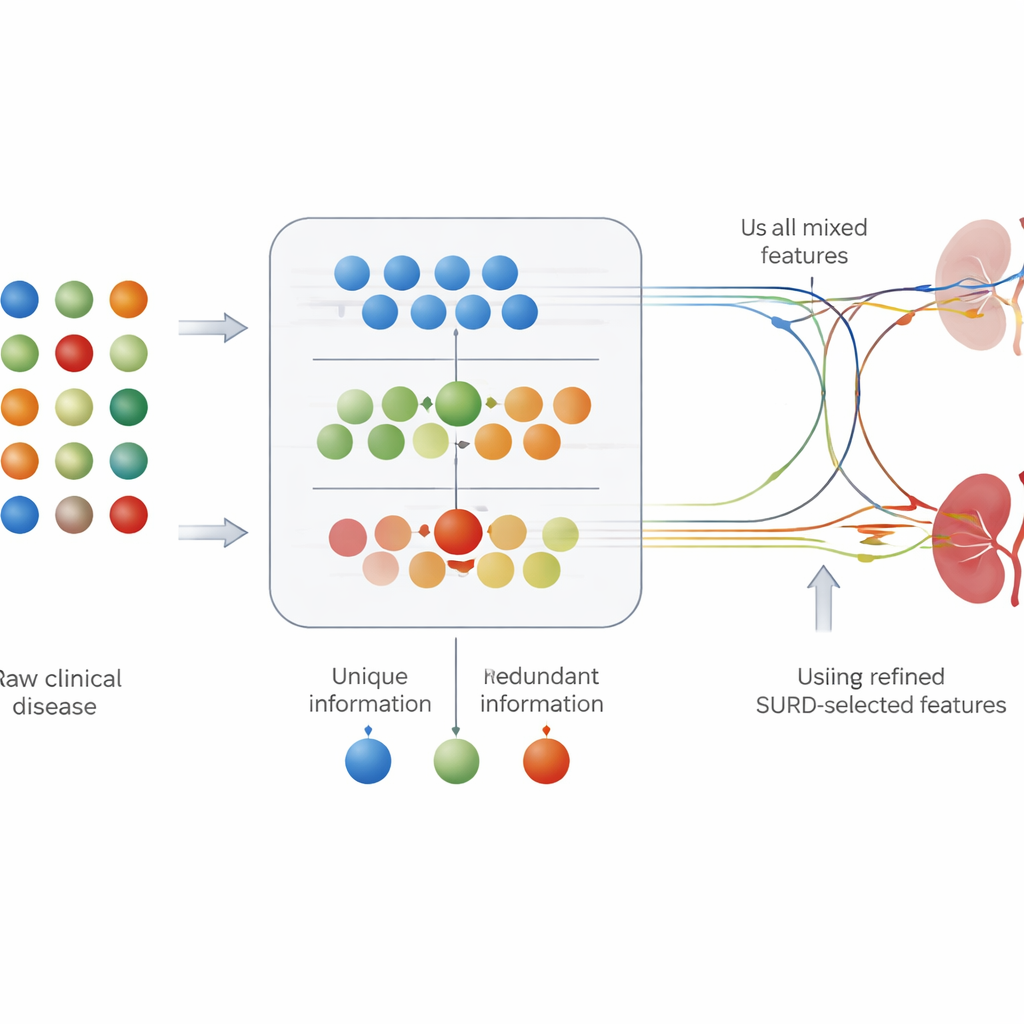
Ver qué pruebas importan y de qué manera
La precisión por sí sola no es suficiente para el uso clínico; los médicos también necesitan saber qué resultados de pruebas están impulsando una predicción. El estudio combinó SURD con herramientas modernas de explicación que asignan a cada variable una contribución a la decisión del modelo para un paciente dado. Este análisis puso de relieve marcadores de riesgo conocidos, como la creatinina sérica (un indicador directo de la función renal), los niveles de hemoglobina, la concentración de orina y la presencia de diabetes o hipertensión. De forma interesante, SURD mostró que algunos de estos factores actúan mayoritariamente en concierto con otros, mientras que la creatinina destaca como una señal fuertemente informativa por sí sola. Conjuntamente, estas técnicas ofrecen tanto una visión global de en qué pruebas se apoya el modelo como desgloses a nivel de paciente sobre por qué a una persona en particular se le predice un alto riesgo.
Qué significa esto para la atención cotidiana
En términos sencillos, el estudio demuestra que es posible construir un calculador de riesgo de enfermedad renal que sea a la vez muy preciso y razonablemente transparente. Al separar la información que se solapa de la que es realmente única en los datos rutinarios de laboratorio e historial, los modelos guiados por SURD realizan predicciones más nítidas sin convertirse en una caja negra misteriosa. Aunque se necesita trabajo adicional en grupos de pacientes más amplios y diversos, este enfoque podría eventualmente ayudar a los clínicos a detectar problemas renales antes, concentrar la atención en las pruebas más informativas y explicar a los pacientes en términos sencillos qué aspectos de su salud ponen en riesgo sus riñones.
Cita: Xue, N., Bai, T., Jia, X. et al. Early detection of chronic kidney disease based on a SURD-enhanced machine learning model. Sci Rep 16, 10444 (2026). https://doi.org/10.1038/s41598-026-41050-z
Palabras clave: enfermedad renal crónica, predicción del riesgo renal, aprendizaje automático médico, IA explicable, historiales clínicos electrónicos