Clear Sky Science · es
Enfoque dinámico de aprendizaje automático para la predicción de la carga de trabajo en entornos en la nube
Por qué importa predecir el tráfico con inteligencia
Cada vez que transmites un vídeo, sigues un gran evento deportivo en línea o compras durante una oferta relámpago, miles de personas pueden estar haciendo clic al mismo tiempo. Entre bastidores, los centros de datos en la nube se afanan por mantener los sitios rápidos sin desperdiciar dinero en máquinas inactivas. Este artículo aborda una pregunta simple con un enorme impacto práctico: ¿cómo pueden los sistemas en la nube anticipar oleadas repentinas de tráfico web lo bastante bien como para encender y apagar servidores justo a tiempo, en lugar de adivinar y pagar de más?
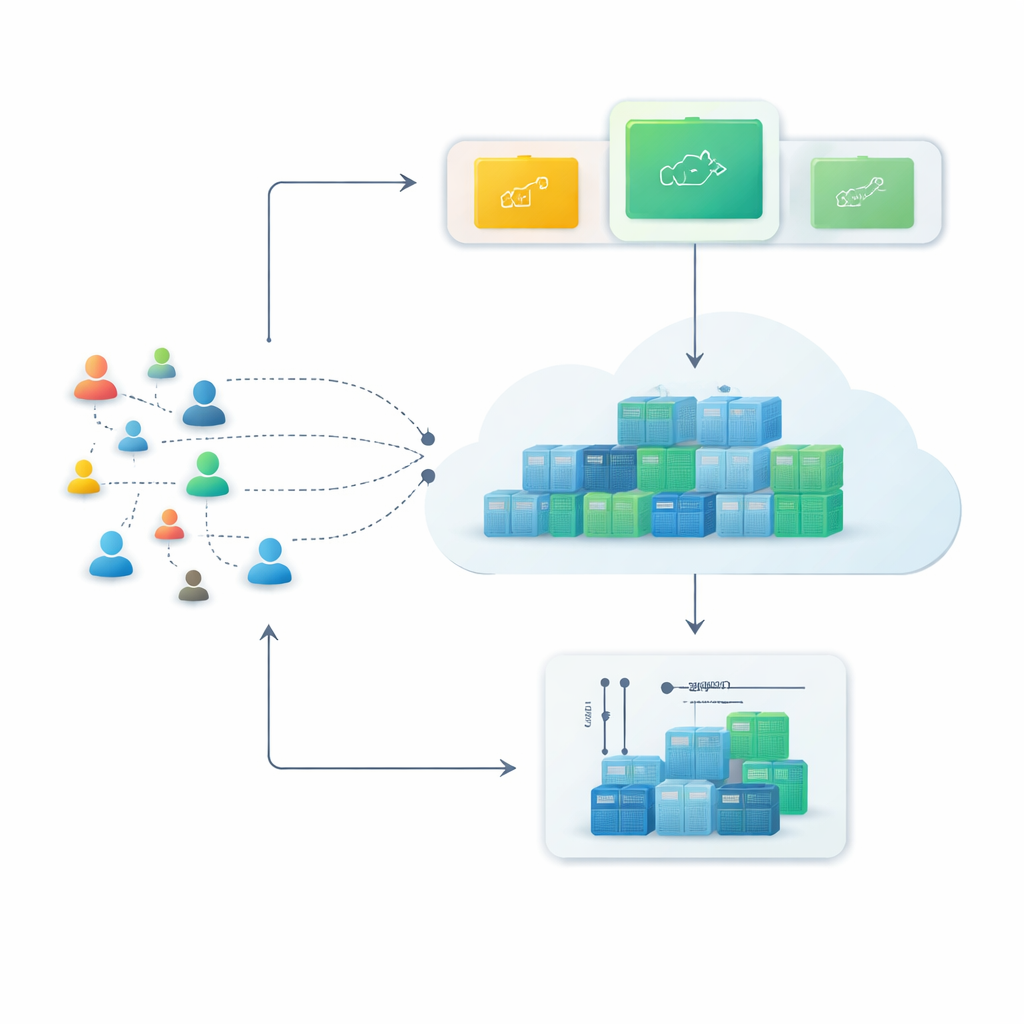
De servidores rígidos a contenedores flexibles
Las plataformas en la nube modernas dependen cada vez más de contenedores, pequeños paquetes de software que pueden iniciarse o detenerse en segundos. En comparación con las máquinas virtuales tradicionales, los contenedores son más ligeros y pueden empaquetarse con mayor densidad, lo que los hace perfectos para servicios que deben crecer rápidamente durante las horas de mayor actividad y encogerse después. Sin embargo, esta flexibilidad solo resulta rentable si el sistema puede anticipar los problemas: si puede predecir cuántas solicitudes web llegarán en los próximos minutos y preparar el número adecuado de contenedores por adelantado.
Por qué falla la predicción de talla única
Investigaciones anteriores han probado muchas formas de pronosticar el tráfico web, desde estadísticas clásicas hasta redes neuronales profundas. Algunas funcionan bien cuando la demanda cambia de forma suave a lo largo del día; otras son mejores cuando el tráfico salta de manera impredecible, como durante un partido del Mundial. El problema es que ningún método es el mejor todo el tiempo. Si los operadores eligen un modelo favorito y se aferran a él, la precisión puede caer bruscamente cuando cambia el comportamiento de los usuarios, lo que conduce ya sea a sitios lentos o a filas de máquinas infrautilizadas que consumen dinero y energía en silencio.
Un bucle de aprendizaje que no deja de adaptarse
Para superar esto, los autores proponen un marco de bucle cerrado que llaman Monitor–Train–Test–Deploy (Monitorear–Entrenar–Probar–Desplegar). La idea es tratar la predicción como un proceso vivo. Primero, el sistema registra continuamente las solicitudes web entrantes en un historial con marcas temporales. A continuación, entrena en paralelo varios métodos de pronóstico diferentes, cada uno intentando aprender patrones en ese historial reciente. Luego prueba estos modelos candidatos con los datos más recientes y los califica según cuánto se desvían sus predicciones de la realidad. Solo el modelo con mejor rendimiento pasa a encargarse de hacer predicciones en vivo, que guían cuántos contenedores ejecutar. A medida que llega nuevo tráfico, el bucle se repite: si los errores de predicción crecen más allá de un nivel tolerado durante dos ciclos consecutivos, el sistema se reentrena automáticamente y puede ceder el control a un modelo distinto.
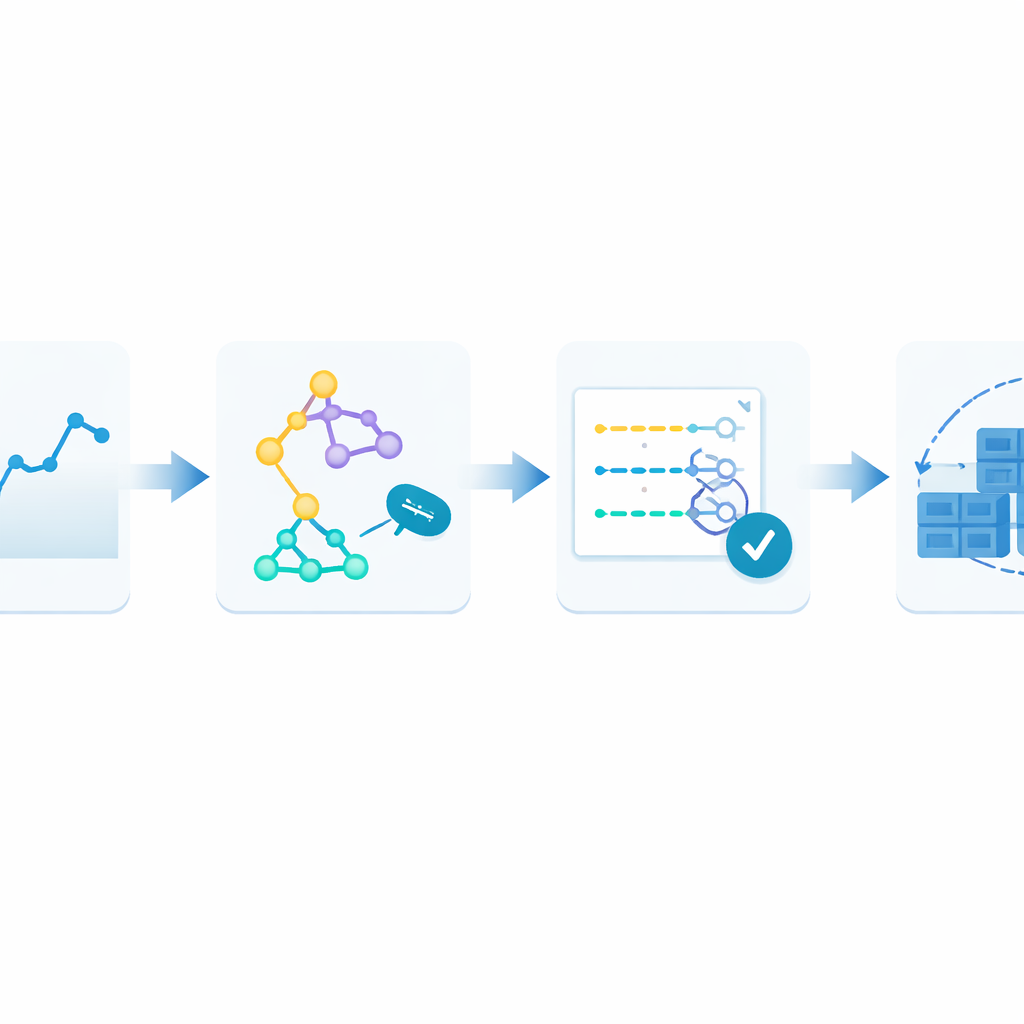
Poniendo el marco a prueba
Los investigadores evaluaron este enfoque usando trazas tanto sintéticas como reales de actividad web. Generaron varios patrones idealizados —curvas en forma de campana suavizadas, cargas que aumentan de forma sostenida a distintas velocidades y tráfico muy errático— y también emplearon registros de los sitios oficiales de la Copa del Mundo de 1998 y 2018, donde el interés se dispara de forma abrupta. Para cada caso compararon tres o cuatro herramientas de predicción conocidas, incluyendo un método basado en estadísticas, un modelo de vectores de soporte, un conjunto de árboles de decisión y, en experimentos posteriores, un tipo popular de red neuronal recurrente. El resultado clave fue que el “ganador” cambiaba según la situación: los modelos estadísticos simples sobresalían cuando la demanda era estable, mientras que los métodos basados en aprendizaje eran claramente superiores cuando el tráfico se volvía salvaje y explosivo.
Mejoras en precisión y eficiencia
Al cambiar continuamente al modelo que en ese momento se adaptaba mejor al comportamiento observado, el marco redujo los errores de predicción hasta en alrededor de un 15% en comparación con mantener cualquier modelo fijo. Igualmente importante, lo logró sin ejecutar todos los modelos todo el tiempo. Solo un predictor está activo durante la operación en vivo; los demás se reentrenan y verifican periódicamente, manteniendo la carga computacional modesta. Los autores también introducen un umbral que se estrecha gradualmente para decidir cuándo reentrenar, de modo que el sistema se vuelva menos tolerante a errores repetidos, reduciendo el riesgo de largos períodos de pronósticos deficientes.
Qué significa esto para los usuarios habituales de la nube
En términos prácticos, el estudio muestra que las plataformas en la nube pueden gestionarse de forma más inteligente dejando que los modelos de predicción compitan y adaptando su elección con el tiempo. Para los usuarios, esto puede traducirse en experiencias en línea más fluidas durante grandes eventos y menos ralentizaciones cuando aparecen multitudes inesperadas. Para los proveedores, promete un uso más eficiente de los recursos informáticos, menores costes operativos y menos energía desperdiciada. En lugar de apostar por un único algoritmo ingenioso, este trabajo aboga por un bucle de control flexible que siga aprendiendo, probando y revisando cómo anticipa la demanda en un mundo digital cada vez más impredecible.
Cita: Nashaat, M., Moussa, W., Rizk, R. et al. Dynamic machine learning approach for workload prediction in cloud environments. Sci Rep 16, 10983 (2026). https://doi.org/10.1038/s41598-026-40777-z
Palabras clave: predicción de carga en la nube, escalado automático, contenedores, aprendizaje automático, series temporales