Clear Sky Science · es
Un sistema de búsqueda multiusuario que preserva la privacidad para inteligencia artificial multimodal
Por qué importa mantener privadas las búsquedas inteligentes
Muchos de nosotros confiamos hoy en IA en la nube para clasificar nuestras fotos, documentos e incluso exploraciones médicas. Estos sistemas son potentes porque comprenden tanto imágenes como palabras, pero plantean una pregunta difícil: ¿cómo disfrutar de esta comodidad sin entregar el significado de nuestros datos más sensibles a servidores remotos? Este artículo presenta PMIRS, un nuevo sistema que pretende permitir a numerosos usuarios buscar en colecciones mixtas de imágenes y texto mientras mantiene su información oculta frente a las máquinas en la nube que alimentan esas búsquedas.
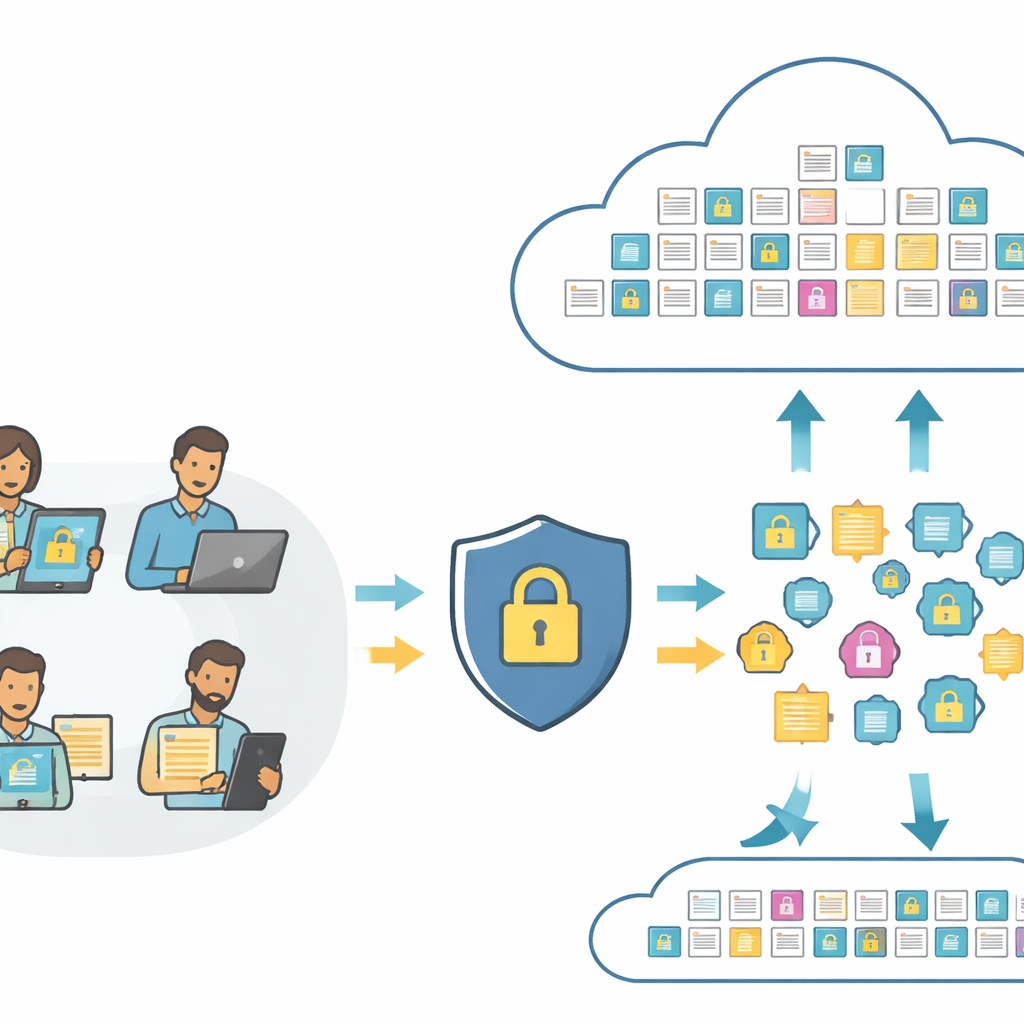
Buscar en imágenes y texto sin revelar su significado
En el núcleo de las herramientas modernas de búsqueda están los «embeddings» —huellas numéricas que capturan el contenido de una foto o una frase para que un ordenador pueda compararlos. Los sistemas estándar envían estas huellas directamente a la nube, donde pueden ser analizadas o incluso mal utilizadas. PMIRS reorganiza este flujo. Los usuarios envían primero sus imágenes y textos en bruto a una capa local, que los convierte en huellas mediante un modelo compacto de visión y lenguaje. Antes de que algo salga del lado del usuario, las huellas se mezclan de forma controlada y luego se cifran. La nube solo ve estas huellas protegidas y copias totalmente cifradas de los datos almacenados, y aun así puede realizar emparejamientos y devolver los mejores resultados.
Aprender de muchos usuarios sin reunir sus datos
Entrenar un buen modelo imagen–texto normalmente requiere reunir grandes cantidades de ejemplos etiquetados en un solo lugar, lo que implica un claro riesgo para la privacidad. PMIRS, en cambio, usa aprendizaje federado. En este esquema, el modelo subyacente, adaptado de la conocida arquitectura CLIP, se distribuye a muchos dispositivos. Cada uno entrena localmente con sus pares privados de imagen–texto y envía únicamente los pesos actualizados del modelo, que a su vez están cifrados. Un servidor central promedia estas actualizaciones para mejorar un modelo compartido sin llegar a ver las fotos o descripciones en bruto de ningún usuario. Los autores además reducen y afinan el modelo mediante un proceso de «destilación» por etapas que poda partes innecesarias mientras preserva la precisión, haciendo el sistema lo bastante ligero para un despliegue práctico.
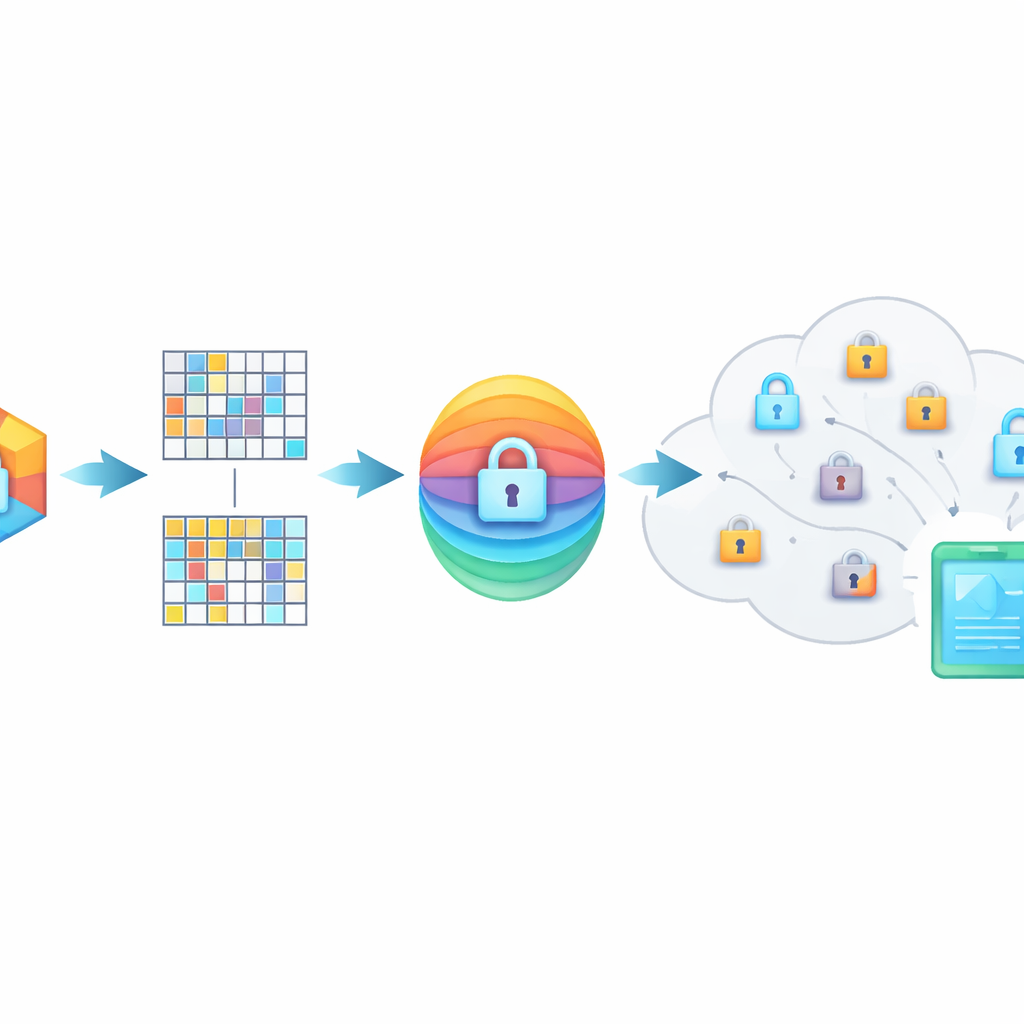
Ocultar el significado dentro de huellas mezcladas
PMIRS protege las consultas con un escudo de dos capas. Primero, cada huella se divide en bloques y cada bloque se transforma mediante una matriz secreta, además de un patrón de ruido cuidadosamente diseñado. Esta mezcla oculta la estructura original de los datos pero está configurada de modo que, cuando dos elementos relacionados son transformados, su similitud permanece. Segundo, el resultado se cifra usando el método AES ampliamente adoptado, con claves que nunca se envían abiertamente por la red. Para situaciones en las que una persona necesita buscar en los datos de otra —por ejemplo, un médico que consulta a un especialista—, el sistema emplea un protocolo de intercambio de claves Diffie–Hellman para que puedan acordar secretos compartidos sin exponerlos a eavesdroppers.
Cómo rinde el sistema en la práctica
Para comprobar si estas protecciones implican un coste excesivo, los investigadores construyeron un benchmark que empareja imágenes cotidianas con frases breves en lenguaje natural —más cercano a cómo las personas describen las cosas que etiquetas de una sola palabra. Compararon PMIRS con una búsqueda estándar basada en CLIP en tres temáticas: escenas naturales, objetos manufacturados y actividades o paisajes. A través de distintos tamaños de repositorio, PMIRS halló de manera consistente un mejor equilibrio entre capturar todos los resultados correctos (recall) y evitar coincidencias falsas (precisión), lo que condujo a una puntuación F1 media —una medida combinada de exactitud— aproximadamente un 7,7 % superior al método de referencia. Importante: los tiempos de respuesta se mantuvieron por debajo de unos 180 milisegundos, lo bastante rápidos para uso interactivo, y a menudo algo más rápidos que la línea base no segura a pesar de los pasos adicionales de protección.
Qué significa esto para los usuarios cotidianos
En términos sencillos, PMIRS demuestra que es posible construir herramientas de búsqueda en la nube que entienden bien imágenes y texto, atienden a muchos usuarios a la vez y aun así mantienen el significado de los datos de cada persona fuera del alcance del proveedor de la nube. Al combinar entrenamiento local, mezcla inteligente de huellas, cifrado fuerte e intercambio de claves seguro, el sistema ofrece una tubería de privacidad de extremo a extremo en vez de proteger solo una etapa. Aunque aún no cubre todos los posibles ataques y necesitará más afinado y pruebas en escenarios reales, el trabajo apunta hacia servicios futuros —como búsqueda de imágenes médicas, bots de atención al cliente o archivos empresariales— donde las personas pueden disfrutar de búsquedas multimodales avanzadas con mucha menos preocupación de que su contenido personal sea revelado o mal usado.
Cita: Gao, Y., Luo, W., Wang, C. et al. A privacy-preserving multi-user retrieval system for multimodal artificial intelligence. Sci Rep 16, 10348 (2026). https://doi.org/10.1038/s41598-026-40734-w
Palabras clave: IA que preserva la privacidad, búsqueda multimodal, aprendizaje federado, búsqueda cifrada, computación en la nube segura