Clear Sky Science · es
Modelo basado en clustering y regresión y análisis de rendimiento para la predicción temprana de enfermedades cardíacas
Por qué importa detectar problemas cardíacos a tiempo
Las enfermedades cardíacas con frecuencia se desarrollan de forma silenciosa durante muchos años, y cuando aparecen síntomas claros puede que ya se haya producido daño. Este estudio explora cómo los sensores corporales cotidianos y el análisis inteligente de datos pueden trabajar juntos para identificar señales de advertencia antes, dando a médicos y pacientes más tiempo para actuar. Al combinar dos maneras distintas de interpretar los datos de salud, los investigadores pretenden hacer las predicciones más precisas sin complicar la tecnología para su uso en clínicas reales.
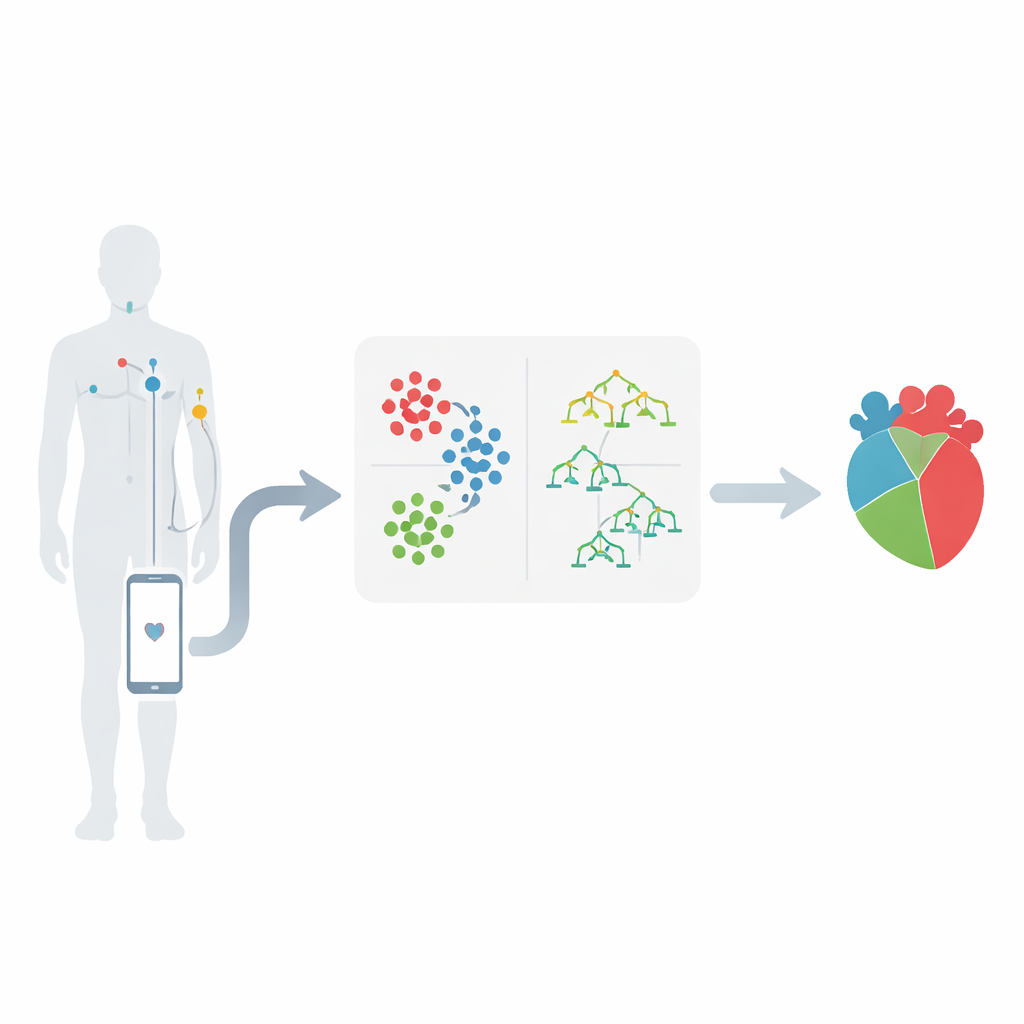
De los sensores corporales a alertas inteligentes
El trabajo se sitúa en el ámbito de las redes inalámbricas de área corporal, donde pequeños sensores colocados sobre la piel registran señales como la frecuencia cardíaca, la presión arterial y la actividad eléctrica del corazón. Estos sensores envían medidas a un dispositivo móvil, que las reenvía a un centro médico para su análisis. La idea clave es que estas series de números pueden revelar patrones que insinúan problemas cardíacos en desarrollo mucho antes de una crisis. Los autores se centran en un conjunto de datos conocido sobre enfermedades cardíacas, seleccionando 12 características importantes que incluyen el tipo de dolor torácico, la presión arterial, el colesterol, el nivel de azúcar en sangre, el dolor torácico inducido por el ejercicio y los cambios observados en un electrocardiograma.
Encontrar grupos ocultos en los datos de pacientes
En lugar de introducir todos los registros de pacientes directamente en una única fórmula de predicción, el equipo agrupa primero a los pacientes similares. Utilizan un método llamado K-means, que clasifica a las personas en clústeres según la semejanza de sus mediciones, con la edad jugando un papel central. Por ejemplo, los pacientes pueden agruparse naturalmente en conjuntos con presión arterial muy alta, colesterol elevado o patrones particulares en las pruebas cardíacas. Este paso de agrupamiento ayuda a destacar qué combinaciones de mediciones son especialmente preocupantes. También revela que ciertos rangos —como presión arterial superior a 150, colesterol por encima de 300 o cambios concretos en las trazas cardíacas— tienden a asociarse con un riesgo mucho mayor.
Enseñar a las máquinas a evaluar el riesgo
Tras agrupar los datos, los investigadores aplican varios métodos de aprendizaje automático que aprenden de casos pasados para predecir si un nuevo paciente probablemente tiene una enfermedad cardíaca significativa. Comparan diferentes enfoques, incluidos árboles de decisión, k-vecinos más cercanos, máquinas de soporte vectorial, regresión logística, Naïve Bayes y bosques aleatorios. En su diseño híbrido, cada nuevo paciente se asigna primero al clúster más cercano; luego un modelo de bosque aleatorio entrenado específicamente para ese tipo de paciente realiza la predicción final de riesgo. Los datos se limpian, escalan y dividen cuidadosamente en conjuntos de entrenamiento y prueba, y se trata el desequilibrio de clases (más pacientes sanos que enfermos) para que los modelos no se sesguen hacia el grupo mayoritario.
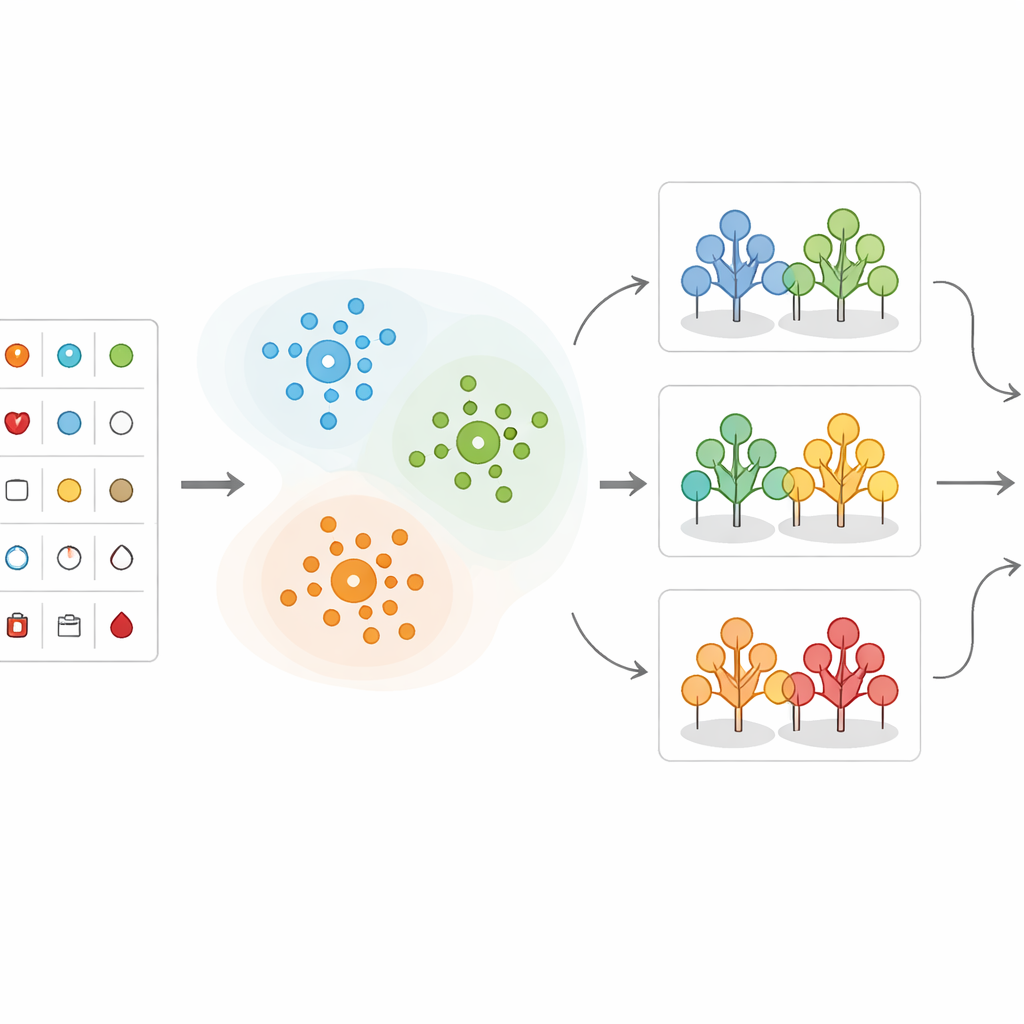
Cómo se desempeña el modelo híbrido
Para evaluar el éxito, el estudio analiza no solo la precisión global sino también con qué frecuencia el modelo detecta correctamente a los pacientes enfermos (recall), tranquiliza correctamente a los sanos (especificidad) y equilibra ambos objetivos (puntuación F1 y AUC‑ROC). Estudios previos con datos similares a menudo alcanzaban alrededor del 85 por ciento de precisión y tenían dificultades para mejorar estas métricas más finas. Aquí, el enfoque combinado de clustering más bosque aleatorio alcanza aproximadamente un 91 por ciento de precisión, con un recall sólido y una especificidad muy alta. Los intervalos de confianza de este modelo no se solapan con los de los métodos más simples, lo que sugiere que la mejora probablemente no se debe al azar. Al mismo tiempo, el tiempo de cálculo se mantiene en un rango práctico —del orden de milisegundos a segundos—, adecuado para sistemas de monitorización en tiempo real o casi en tiempo real.
Qué significa esto para pacientes y médicos
En términos cotidianos, el estudio muestra que dejar que los ordenadores primero clasifiquen a los pacientes en grupos significativos y luego apliquen reglas de predicción ajustadas puede afinar la detección temprana de enfermedades cardíacas. El método resulta especialmente prometedor para configuraciones de monitorización continua, donde los sensores vestibles recopilan datos discretamente en segundo plano. Aunque los resultados proceden de un conjunto de datos estructurado y de tamaño modesto en lugar de historiales clínicos completos, y los autores advierten sobre posibles sesgos, el mensaje es claro: un uso más inteligente de las mediciones existentes puede ofrecer a los médicos un sistema de alerta temprana más fiable. Con más trabajo y conjuntos de datos más grandes y ricos, este tipo de análisis híbrido podría ayudar a convertir lecturas crudas de sensores en alertas personalizadas y oportunas que eviten infartos y otros eventos graves antes de que ocurran.
Cita: Tolani, M., AlZahrani, Y., Suman, G. et al. Clustering-cum-regression based model and performance analysis for early prediction of heart disease. Sci Rep 16, 9494 (2026). https://doi.org/10.1038/s41598-026-40626-z
Palabras clave: predicción de enfermedades cardíacas, sensores de salud vestibles, aprendizaje automático, agrupamiento de datos médicos, modelo de bosque aleatorio