Clear Sky Science · es
Colisiones exactas de características en redes neuronales
Cuando imágenes diferentes engañan a una máquina inteligente
Los sistemas modernos de inteligencia artificial pueden reconocer rostros, leer exploraciones médicas y guiar coches autónomos. Ya sabemos que pueden ser engañados por cambios diminutos y cuidadosamente diseñados en una imagen. Este artículo muestra algo aún más sorprendente: esas mismas redes pueden ser ciegas ante cambios enormes y evidentes, tratando imágenes muy diferentes como si fuesen la misma. Comprender cómo y por qué ocurre esto es crucial si queremos sistemas de IA en los que podamos confiar de verdad.
De pequeños retoques a grandes puntos ciegos
Las redes neuronales profundas impulsan los avances actuales en visión, lenguaje y muchos otros campos. Investigaciones previas sobre ejemplos adversarios revelaron que un cambio apenas visible en una imagen puede hacer que una red la clasifique mal con alta confianza. Trabajos más recientes descubrieron el problema opuesto: algunas redes apenas reaccionan ante cambios grandes y obvios, y aun así producen predicciones casi idénticas. En esos casos, las características internas extraídas de dos imágenes muy diferentes "colisionan", es decir, la red las representa de forma prácticamente igual. Este estudio lleva esa idea mucho más lejos, demostrando que las redes comunes no solo presentan colisiones aproximadas, sino que pueden tener colisiones de características exactas, donde dos entradas distintas se mapean a señales internas exactamente iguales.
Cómo surgen las colisiones dentro de una red
Para explicar estas colisiones, los autores examinan el funcionamiento interno de las redes neuronales y se centran en sus matrices de pesos, los números entrenados que conectan una capa con la siguiente. Una colisión de características ocurre cuando dos entradas diferentes producen la misma salida en alguna capa; una vez que eso sucede, todas las capas posteriores también ven lo mismo y, por tanto, no pueden distinguir las entradas. Matemáticamente, esto ocurre cuando la diferencia entre dos entradas yace en el "espacio nulo" de los pesos de una capa: direcciones en el espacio de entradas que la capa ignora por completo. Los autores muestran que siempre que una matriz de pesos tiene un valor propio cero o realiza un mapeo desde un espacio de mayor dimensión a uno de menor dimensión, tales direcciones ignoradas deben existir. Debido a que la mayoría de arquitecturas del mundo real, incluidos los modelos populares para clasificación, segmentación y detección de objetos, usan muchas de estas capas, las colisiones no son casos raros sino una propiedad casi inevitable de estas redes.
Una nueva forma de construir entradas que colisionan
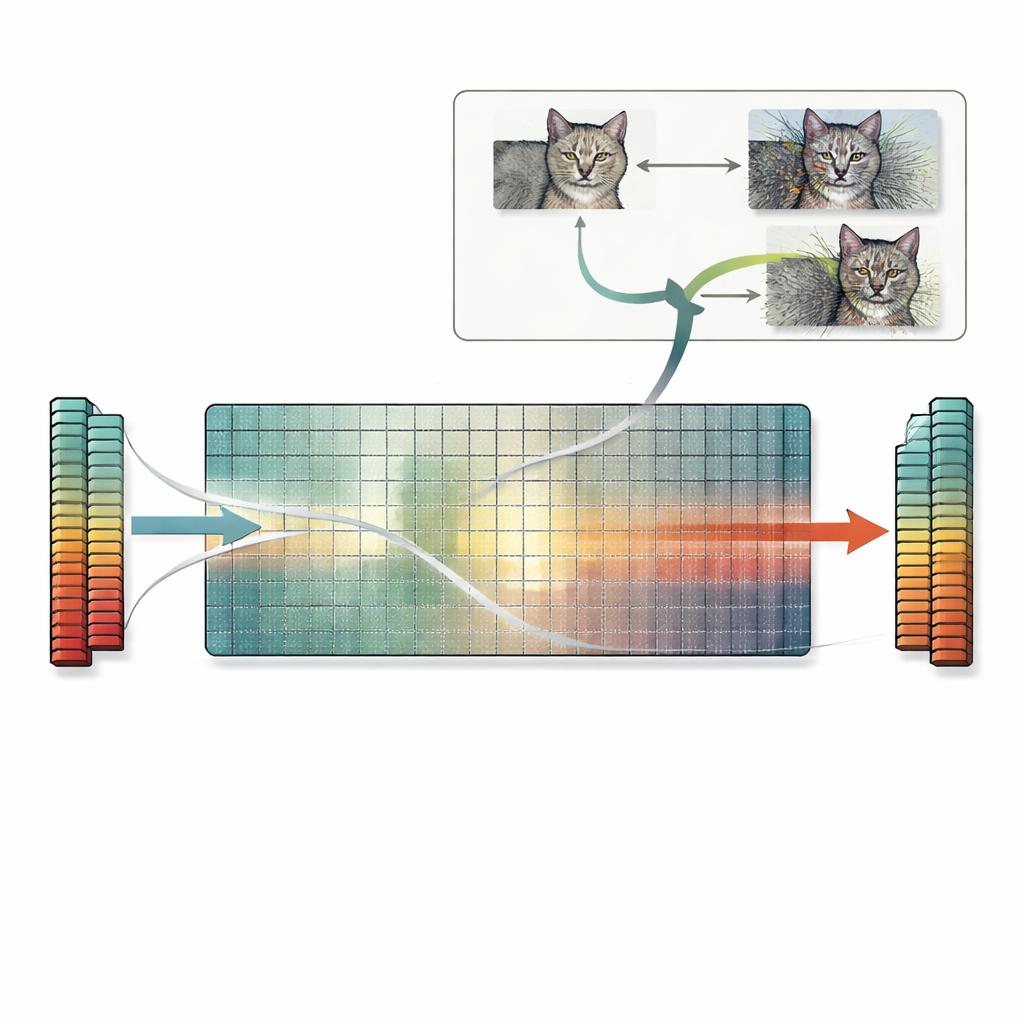
Partiendo de esta idea, el artículo introduce una receta práctica llamada la búsqueda en el espacio nulo. En lugar de confiar en prueba y error o en trucos basados en gradientes, este método utiliza directamente el espacio nulo de la primera matriz de pesos. Partiendo de cualquier imagen, los autores calculan un vector que la primera capa ignora y luego añaden una versión escalada de ese vector a la imagen. Como esa dirección es invisible para la capa, las características internas de la red —y la predicción final— permanecen exactamente iguales, aunque la imagen se vea fuertemente distorsionada para un observador humano. La misma idea se extiende a capas convolucionales y, en principio, a capas posteriores también. Los autores revisan muchos modelos estándar y encuentran que la mayoría tiene abundantes direcciones ignoradas, lo que significa que se pueden generar innumerables imágenes en colisión de esta manera para una amplia gama de tareas.
Riesgos ocultos para la similitud, las explicaciones y la seguridad
Estas colisiones exactas de características tienen consecuencias de gran alcance. Dos imágenes con características en colisión no solo compartirán la misma predicción, a menudo también compartirán los mismos mapas de explicación producidos por herramientas populares de interpretabilidad. Eso puede hacer que una imagen irreconocible y fuertemente perturbada parezca tan bien sostenida como una limpia, minando la confianza en los métodos de explicación. El problema también afecta a las medidas de similitud basadas en características que dependen de redes neuronales: tales métricas pueden juzgar una imagen muy corrupta como "idéntica" a la original porque las características coinciden exactamente, aunque métricas sencillas basadas en píxeles señalen correctamente grandes diferencias. Finalmente, la búsqueda en el espacio nulo puede combinarse con ataques adversarios estándar, produciendo muchas imágenes adversarias distintas que todas conducen a la misma predicción errónea y se mantienen dentro de los límites habituales de perturbación, agravando las preocupaciones de seguridad existentes.
Qué significa esto para construir una IA más segura
En términos sencillos, este trabajo muestra que las redes neuronales actuales a menudo descartan información de maneras previsibles, dejando direcciones enteras en el espacio de entradas que no afectan sus decisiones en absoluto. Los atacantes pueden explotar estos puntos ciegos para crear imágenes extrañas o adversarias que una red trata como idénticas a las normales. Los autores sugieren usar recuentos simples de estas direcciones ignoradas como una forma de evaluar cuán vulnerable puede ser un modelo, y arguyen que redes más esbeltas y mejor regularizadas con espacios nulos más pequeños podrían ser más robustas. Aunque queda mucho por probar en la práctica, el mensaje central es claro: si queremos IA fiable, debemos prestar atención no solo a aquello a lo que las redes responden, sino también a lo que ignoran.
Cita: Ozbulak, U., Rao, S., De Neve, W. et al. Exact feature collisions in neural networks. Sci Rep 16, 10139 (2026). https://doi.org/10.1038/s41598-026-40605-4
Palabras clave: redes neuronales, ejemplos adversarios, colisiones de características, robustez del modelo, búsqueda en el espacio nulo