Clear Sky Science · es
CMT-Unet: aprovechando un marco híbrido por etapas para mayor precisión y eficiencia en la segmentación de imágenes médicas
Vistas más nítidas del interior del cuerpo
La medicina moderna depende en gran medida de exploraciones como la TC y la RM para mirar dentro del cuerpo, pero convertir estas imágenes en escala de grises, a menudo borrosas, en contornos nítidos de órganos y tejidos sigue siendo un reto. Los médicos necesitan límites precisos para planificar cirugías, seguir la función cardíaca o medir la respuesta de un tumor al tratamiento. Este artículo presenta un nuevo enfoque de visión por computador, llamado CMT-Unet, diseñado para trazar esos contornos con mayor precisión y eficiencia, acercando el análisis automatizado de imágenes al uso clínico cotidiano.
Por qué importan los contornos en las imágenes
Antes de una operación o de un tratamiento complejo, los clínicos suelen necesitar un mapa a nivel de píxel de órganos o estructuras en una exploración, un proceso conocido como segmentación. Tradicionalmente, los expertos delineaban estas regiones a mano, una tarea lenta, fatigosa y sujeta a variaciones entre observadores. En la última década, los métodos de aprendizaje profundo han asumido gran parte de este trabajo, especialmente los modelos basados en redes convolucionales y mecanismos de atención estilo Transformer. Los modelos convolucionales sobresalen en captar detalles locales finos, como los bordes, mientras que los Transformers son especialmente buenos captando contexto amplio en toda la imagen. Sin embargo, cada enfoque tiene sus compromisos: las convoluciones pueden perder relaciones a larga distancia, mientras que los Transformers suelen requerir mucha potencia de cálculo y memoria.
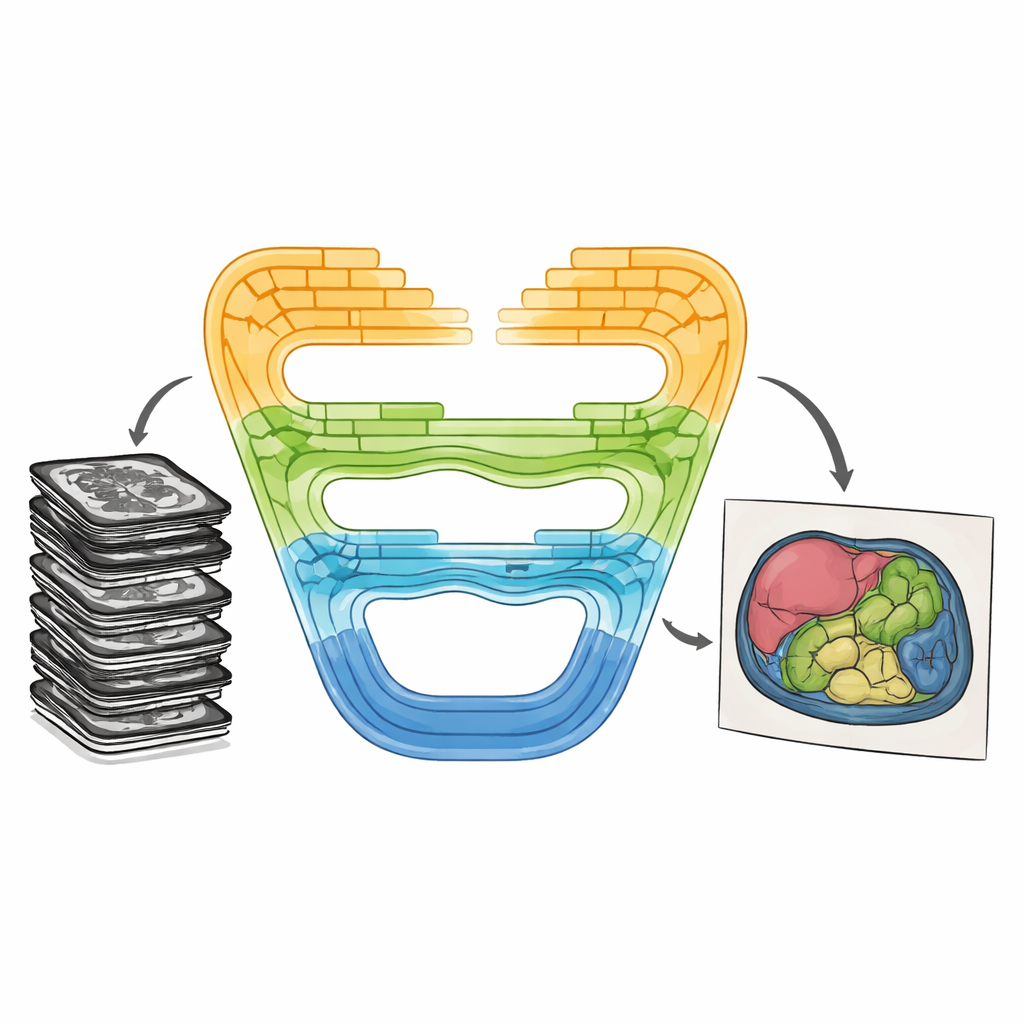
Combinar fortalezas de una manera nueva
CMT-Unet aborda estos compromisos entrelazando tres tipos de bloques constructivos de forma por etapas, en lugar de confiar en un único tipo en toda la red. En la parte inicial del sistema, una unidad convolucional de residuo invertido aprende rápidamente patrones locales: bordes nítidos y texturas que ayudan a distinguir tejidos contiguos. En las etapas intermedias, un módulo basado en los llamados modelos de espacio de estado, adaptado de una arquitectura reciente llamada Mamba, transmite información a lo largo de secuencias de características de la imagen de una manera consciente del contexto y eficiente en cómputo. Más profundo en la red, bloques Transformer mejorados con atención HiLo dividen la información en componentes de alta y baja frecuencia, permitiendo que el modelo capture tanto detalles minúsculos como formas orgánicas amplias antes de recombinarlos. Este diseño en capas refleja la progresión natural desde píxeles crudos hasta significado abstracto durante el procesamiento de imágenes.
Cómo funciona el nuevo modelo por dentro
En la práctica, CMT-Unet sigue la disposición en forma de U familiar en imagen médica: un codificador que comprime la información en características más ricas, un decodificador que reconstruye una predicción a tamaño completo y conexiones de salto que transmiten detalle espacial. La diferencia clave radica en qué módulos se usan en cada profundidad. La unidad convolucional temprana maneja la estructura de grano fino que los componentes Mamba y Transformer podrían difuminar. El bloque MambaVision modificado mejora el contexto de rango medio mezclando información espacial mediante operaciones bidimensionales especialmente diseñadas, evitando el alto coste de la atención total mientras sigue viendo más allá de parches locales. La atención HiLo en la etapa Transformer separa explícitamente los bordes definidos de los patrones de fondo suaves, combinándolos de forma que se preserven los límites. Finalmente, un módulo dual de remuestreo en el decodificador ayuda a reconstruir contornos limpios y continuos a la vez que reduce artefactos comunes como los patrones de tablero de ajedrez.
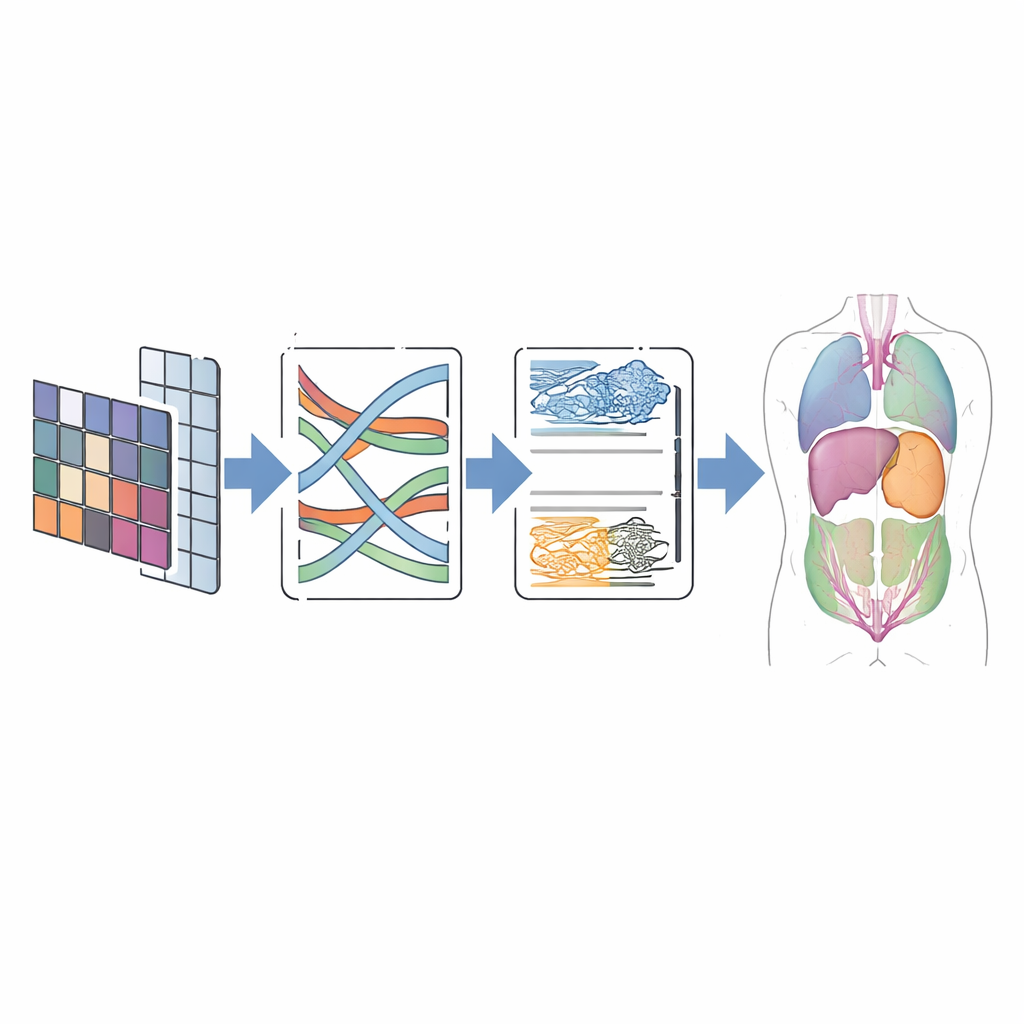
Pruebas con exploraciones del mundo real
Para juzgar si este diseño da sus frutos, los autores probaron CMT-Unet en dos conjuntos de datos públicos de uso habitual. El primero, llamado Synapse, contiene TC abdominales con ocho órganos etiquetados, incluyendo hígado, riñones y estómago. El segundo, ACDC, incluye imágenes de RM cardíaca con etiquetas de los ventrículos y la pared muscular del corazón. En estos puntos de referencia, CMT-Unet logró puntuaciones de segmentación comparables o superiores a modelos líderes basados en convoluciones, Transformers e híbridos, usando al mismo tiempo un número moderado de parámetros y una cantidad manejable de cómputo. Las comparaciones visuales mostraron contornos más suaves y anatómicamente coherentes, especialmente alrededor de regiones desafiantes como las cavidades cardiacas, cruciales para medir función y planificar intervenciones.
Qué significa esto para pacientes y clínicas
Para el público no especializado, la conclusión principal es que CMT-Unet ofrece una manera más inteligente de trazar estructuras en imágenes médicas al asignar cuidadosamente la herramienta adecuada a cada etapa del procesamiento. Al equilibrar detalle local y contexto global, el modelo puede producir contornos orgánicos precisos y limpios sin exigir recursos de supercomputación. Aunque el trabajo actual se centra en exploraciones bidimensionales y en un conjunto limitado de datos públicos, el enfoque resulta prometedor para futuras extensiones a imágenes tridimensionales y a entornos clínicos más amplios. Si se valida adicionalmente, este tipo de segmentación ligera pero precisa podría respaldar diagnósticos más rápidos, una planificación de tratamientos más fiable y guía en tiempo real en entornos hospitalarios concurridos.
Cita: Wang, R., Liu, H. & Wang, G. CMT-Unet: leveraging stage-wise hybrid framework for enhanced accuracy and efficiency in medical image segmentation. Sci Rep 16, 10079 (2026). https://doi.org/10.1038/s41598-026-40572-w
Palabras clave: segmentación de imágenes médicas, aprendizaje profundo, redes neuronales híbridas, modelos de espacio de estado, imágenes médicas