Clear Sky Science · es
Un enfoque de aprendizaje automático basado en kNN para automatizar la valoración de causalidad de eventos adversos
Por qué importa esto para las personas que toman medicamentos
Cuando un medicamento nuevo llega al mercado, su historia apenas comienza. Millones de personas lo usarán en el mundo real y algunas experimentarán problemas de salud que podrían o no estar causados por el fármaco. Determinar qué reacciones son realmente atribuibles al medicamento es vital para la seguridad del paciente, pero hoy ese trabajo es lento, complejo y en gran medida manual. Este estudio explora cómo una forma sencilla pero potente de inteligencia artificial puede ayudar a los expertos a revisar estos informes de seguridad más rápido y con mayor consistencia, sin sustituir el juicio humano que en última instancia protege a los pacientes.
Cómo las historias de seguridad se convierten en datos
Las compañías farmacéuticas y los reguladores dependen de los informes individuales de seguridad de casos, que son resúmenes estructurados de las experiencias reales de las personas con medicamentos. Cada informe puede incluir qué salió mal (por ejemplo, un dolor de cabeza o un problema hepático), cuán grave fue, qué otros medicamentos y enfermedades estaban presentes y qué pensó el revisor original sobre la relación con el fármaco. Para más de 800.000 informes de este tipo correspondientes a seis medicamentos comercializados, los revisores médicos de la compañía ya habían decidido si cada evento adverso estaba relacionado con el fármaco, no relacionado o era imposible de valorar porque faltaba información o había datos contradictorios. Los investigadores usaron este rico registro histórico como material de entrenamiento para un modelo informático que aprendiera a imitar esas decisiones humanas en casos nuevos.

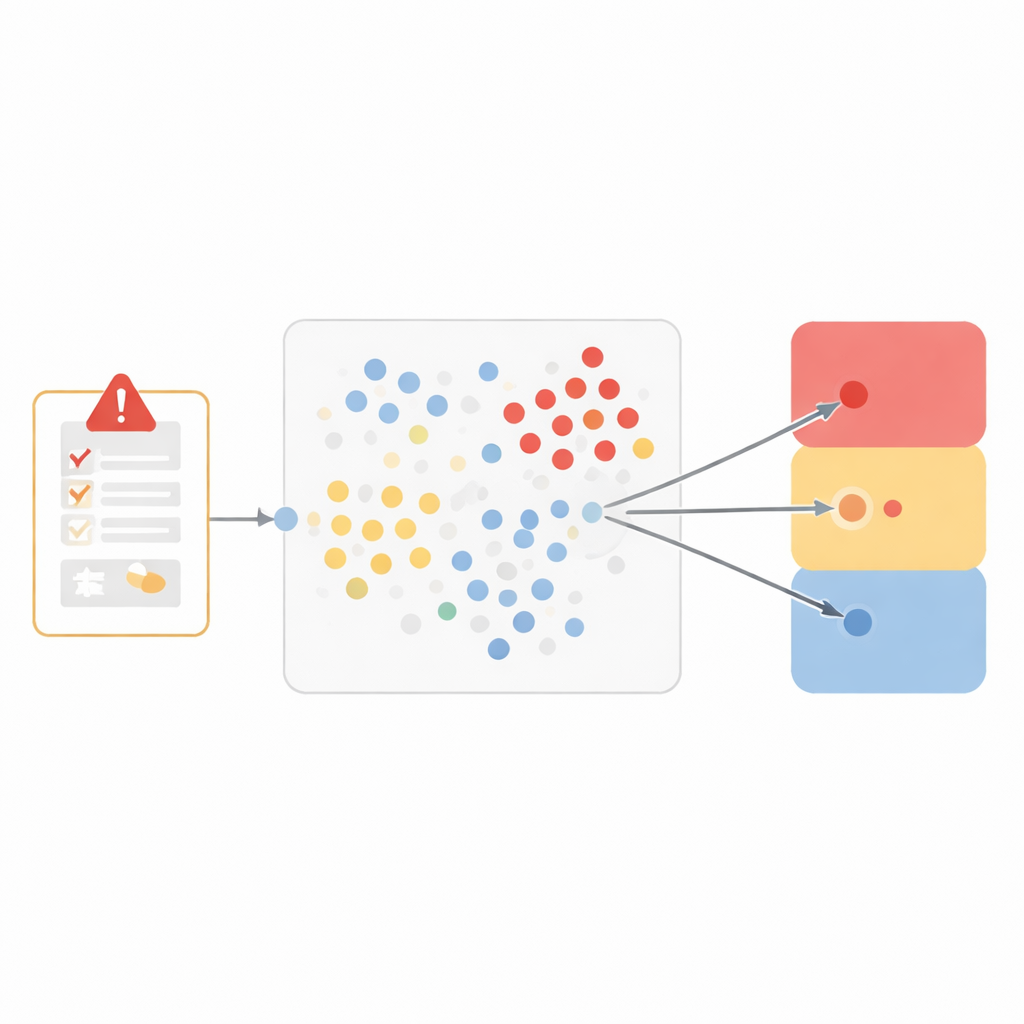
Enseñar a un ordenador a detectar casos similares
En lugar de construir un sistema de caja negra, el equipo eligió un método particularmente transparente llamado “vecinos más cercanos”. La idea es intuitiva: si dos casos se parecen mucho, probablemente compartan la misma conclusión sobre si el fármaco causó el problema. Para capturar la similitud, los investigadores representaron cada evento adverso como un perfil de siete partes, que incluía el término médico para el evento, qué ocurrió al suspender y reanudar el fármaco, si el problema era esperable para ese medicamento, la opinión del informante, otros medicamentos concomitantes, la historia médica y la gravedad del evento. Luego midieron qué tan cercanos estaban entre sí dos casos en este espacio de siete dimensiones, dando más peso a las características que importan más para la causalidad, como el evento exacto y lo que ocurrió cuando cambió el tratamiento.
De la proximidad a una decisión ternaria
Cuando llega un informe nuevo, el modelo revisa los datos históricos para encontrar los diez casos más similares. A continuación comprueba cómo habían sido clasificados esos vecinos y les permite “votar” entre tres resultados amplios: probablemente relacionado con el fármaco, no relacionado o improbable, y no evaluable. Esta clasificación ternaria equilibra la matización clínica y un rendimiento fiable. Probado en más de 250.000 eventos no vistos previamente, el modelo coincidió estrechamente con los revisores humanos para los eventos considerados relacionados y para los juzgados no evaluables, con bajas tasas de error y puntuaciones sólidas que combinan precisión y exhaustividad. Tuvo más dificultades con el grupo más pequeño de eventos claramente no relacionados, lo que refleja el reto al que se enfrentan los sistemas de aprendizaje automático cuando un tipo de ejemplo es relativamente raro.
Reducir la niebla del “no se puede saber”
Un problema práctico en la labor de seguridad en el mundo real es que la etiqueta “no evaluable” puede convertirse en un cajón de sastre cuando la información es escasa o ambigua, lo que dificulta identificar patrones reales de seguridad. Los investigadores añadieron una herramienta de ajuste que hace que el modelo sea más cauteloso al asignar esta etiqueta. En lugar de elegir “no evaluable” cada vez que gana por mayoría simple entre casos similares, el modelo ahora requiere un porcentaje más alto de vecinos que apoyen esa elección. Al elevar este umbral, el equipo pudo reducir drásticamente la frecuencia con que el modelo calificaba un caso como no evaluable y mejorar el rendimiento para las otras dos categorías, a costa de un aumento de desacuerdo en los eventos más difíciles de juzgar. Un panel de control web permite a los revisores médicos ajustar este umbral por producto, ver al instante cómo cambia el equilibrio de resultados y centrar su atención en los casos donde el modelo y los humanos discrepan.
Qué significa esto para la seguridad de los medicamentos en el futuro
Para una muestra de casos recientes que los revisores humanos habían etiquetado como no evaluables, el sistema señaló cientos en los que su conclusión difería. Cuando revisores sénior reexaminaron estos, coincidieron con el modelo en más de dos tercios de las ocasiones, mostrando que estas herramientas pueden señalar patrones pasados por alto y apoyar la supervisión de calidad en lugar de sustituir a los expertos. El trabajo demuestra que un enfoque claro, basado en la similitud, puede introducir la inteligencia artificial en la seguridad de medicamentos de una manera explicable, ajustable y alineada con la práctica médica. A medida que se acumulen más datos y se añadan narrativas de texto usando tecnologías modernas de lenguaje, sistemas como este podrían ayudar a garantizar que los riesgos emergentes se detecten antes, manteniendo a los clínicos firmemente al mando de las decisiones finales.
Cita: Ren, J., Carroll, H., McCarthy, K. et al. A kNN based machine learning approach to automating causality assessment of adverse events. Sci Rep 16, 9140 (2026). https://doi.org/10.1038/s41598-026-40267-2
Palabras clave: farmacovigilancia, eventos adversos por fármacos, evaluación de causalidad, aprendizaje automático, k vecinos más cercanos