Clear Sky Science · es
KM-DBSCAN: un marco mejorado de detección de bordes basado en densidad y centroides para la reducción de datos hacia una IA más ecológica
Por qué hacer la IA más pequeña puede hacerla más ecológica
La inteligencia artificial tiene un coste oculto: la electricidad. Entrenar modelos modernos de aprendizaje automático a menudo implica procesar millones de puntos de datos en hardware que consume mucha energía, lo que a su vez genera emisiones de carbono. Este artículo presenta KM‑DBSCAN, una nueva forma de reducir conjuntos de datos antes del entrenamiento sin desechar la información que los modelos realmente necesitan. Al conservar solo los datos más informativos, el método acelera el aprendizaje, reduce el consumo energético y aun así ofrece predicciones precisas en tareas que van desde el reconocimiento de dígitos manuscritos hasta la detección temprana del cáncer de piel.
Demasiados datos, demasiado consumo
Durante años, la creencia dominante en IA ha sido que más datos casi siempre conducen a mejores modelos. Aunque eso puede mejorar la precisión, también implica tiempos de entrenamiento más largos, ordenadores más potentes y facturas eléctricas mayores. Los investigadores han empezado a distinguir entre la “IA roja”, que persigue la precisión a cualquier coste, y la “IA verde”, que intenta equilibrar rendimiento e impacto ambiental. Una vía prometedora hacia una IA más ecológica es la reducción de datos: en lugar de alimentar a un modelo con todos los ejemplos disponibles, identificar un conjunto mucho más pequeño de casos que sigan definiendo bien el problema, especialmente los casos fronterizos difíciles que determinan las decisiones de un clasificador.
Combinar dos ideas sencillas en un filtro inteligente
El marco KM‑DBSCAN combina dos técnicas de agrupamiento bien conocidas para actuar como un filtro inteligente sobre los datos crudos. Primero, un método rápido llamado K‑Means agrupa puntos en conglomerados compactos y reemplaza cada grupo por un centro representativo, o centroide. Esto reduce el problema de miles o millones de puntos a unos pocos cientos representativos. A continuación, se aplica un método basado en densidad (DBSCAN) sobre esos centroides para encontrar qué regiones están en los bordes entre clústeres y cuáles son interiores densos y homogéneos o ruido aislado. Al operar a nivel de centroides, DBSCAN se vuelve mucho más rápido y menos sensible a la elección de parámetros que cuando se aplica directamente a todos los puntos de datos.

Conservar solo los casos difíciles e informativos
Una vez que KM‑DBSCAN ha identificado dónde los distintos grupos se tocan o solapan, conserva únicamente los puntos de datos que se sitúan cerca de esos bordes y descarta tanto los puntos de interior profundo como los valores atípicos evidentes. Los puntos interiores son en gran medida redundantes: todos se parecen y envían al modelo el mismo mensaje sobre su clase. Los puntos fronterizos, en contraste, indican al modelo exactamente dónde termina una clase y comienza otra. En conjuntos de datos sintéticos de juguete, esta estrategia reproduce las mismas fronteras de decisión que un clasificador aprende a partir de los datos completos, incluso cuando se elimina la mayoría de los puntos. En conjuntos de datos del mundo real como Banana, los dígitos USPS, el conjunto de datos de ingresos Adult, datos de colisiones de vehículos, variedades de frijol seco e imágenes de melanoma, los conjuntos reducidos preservan la estructura clave del problema mientras que son un orden de magnitud más pequeños.
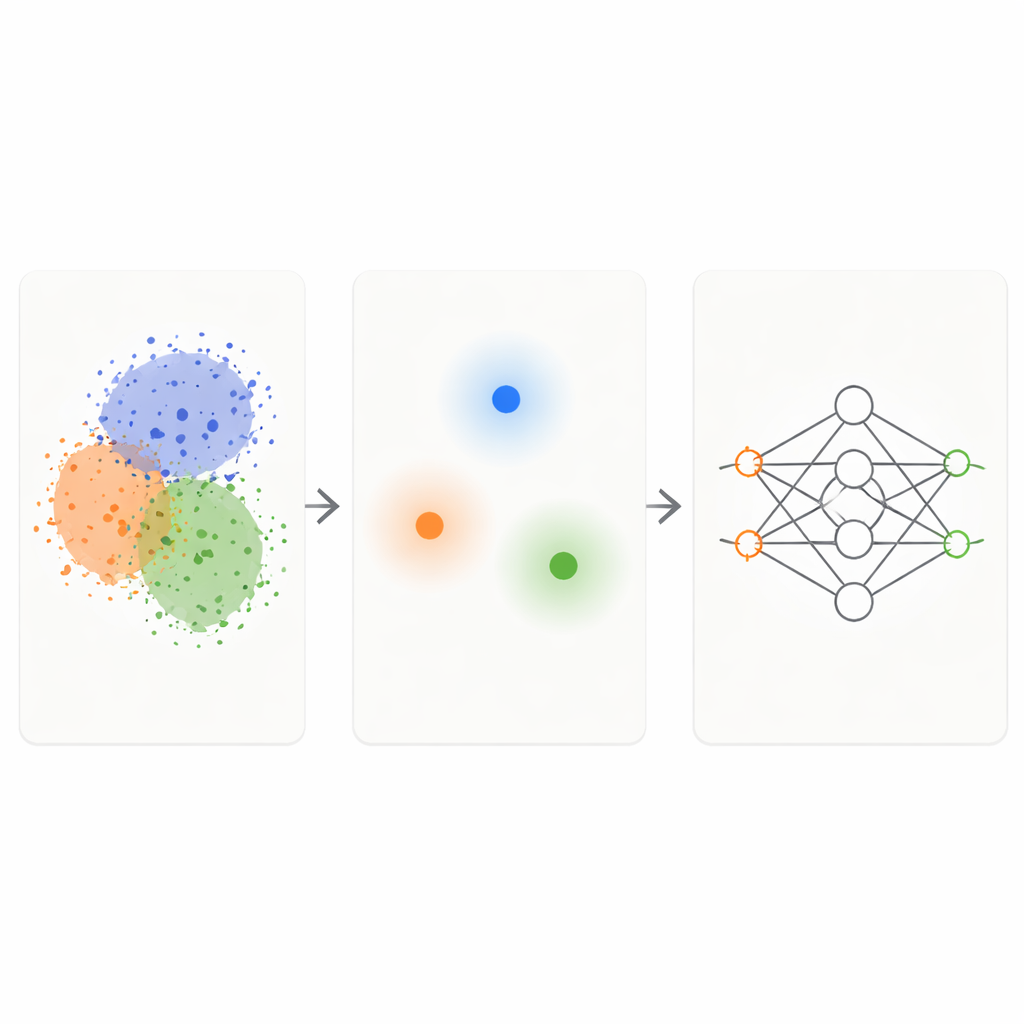
Velocidad, ahorro de carbono y aplicaciones reales
Los autores probaron KM‑DBSCAN como preprocesado para varios modelos populares, incluidos máquinas de vectores de soporte, perceptrones multicapa y redes neuronales convolucionales. En muchos casos, entrenar con los datos reducidos fue decenas a miles de veces más rápido manteniendo casi la misma precisión —y a veces incluso mejorándola ligeramente. Por ejemplo, en el reconocimiento de dígitos manuscritos, el método redujo el conjunto de entrenamiento hasta solo el 1,4% de su tamaño original y aun así aumentó ligeramente la precisión, mientras que hizo el entrenamiento 284 veces más rápido. En una tarea de predicción de ingresos con clases desequilibradas, logró una aceleración de 6907 veces usando solo alrededor del 3% de los datos con una pérdida mínima de precisión. En un experimento de detección de melanoma, una red neuronal profunda alcanzó más del 90% de precisión entrenando con menos de un tercio del conjunto original de imágenes de piel, con emisiones de carbono reducidas en más del 70%.
Qué significa esto para la IA cotidiana
Para los no especialistas, el mensaje clave es que una selección más inteligente puede superar al volumen bruto. KM‑DBSCAN muestra que elegir cuidadosamente qué ejemplos ve un modelo —centrándose en los casos fronterizos más informativos— puede reducir drásticamente el tiempo de cómputo y el consumo de energía manteniendo la fiabilidad de las predicciones. Este enfoque encaja perfectamente en el impulso más amplio hacia la IA verde, donde la calidad de los datos y el diseño cuidadoso de las canalizaciones de entrenamiento importan tanto como el tamaño bruto del modelo. Si se adoptara ampliamente, este filtrado consciente de los datos podría hacer que desde el análisis de imágenes médicas hasta los sistemas de seguridad vial sean más sostenibles, acercando herramientas de IA potentes a organizaciones que carecen de recursos informáticos masivos.
Cita: AboElsaad, M.Y., Farouk, M. & Khater, H.A. KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI. Sci Rep 16, 10349 (2026). https://doi.org/10.1038/s41598-026-40062-z
Palabras clave: IA ecológica, reducción de datos, agrupamiento, eficiencia en aprendizaje automático, detección de melanoma